Was ist Natural Language Processing oder NLP ?
Hast Du Dich jemals gefragt, wie persönliche KI-AssistentInnen wie Siri oder Cortana funktionieren? Wie konnte Deine Rechtschreibprüfung Syntaxfehler erkennen, die Du selbst sonst nicht bemerkt hättest? Wie schafft es Deine Suchmaschine, die Wörter, die Du gerade schreiben wolltest, in den ersten Buchstaben zu erraten?
Obwohl diese Werkzeuge für völlig unterschiedliche Zwecke eingesetzt werden, basieren sie alle auf gemeinsamen Methoden: Den Methoden des Natural Language Processing (NLP) oder Linguistische Datenverarbeitung (LDV) auf Deutsch.
Ziel dieses Artikels ist es, einen Überblick über NLP zu schaffen. Am Ende der Lektüre wirst Du genau wissen :
- Was ist Natural Language Processing ?
- Was sind die Hauptanwendungsbereiche des NLP?
- Was sind die gängigsten NLP-Methoden?
Inhalt
- Einführung
- Word embedding – Word2vec
- NLP – Word translation
- NLP Twitter – Stimmungsanalyse
NLP - Natural Language Processing Definition
NLP steht für Natural Language Processing (Linguistische Datenverarbeitung auf Deutsch) und ist eine Disziplin, die sich mit dem Verstehen, der Bearbeitung und der Erzeugung natürlicher Sprache durch Maschinen beschäftigt. NLP befindet sich also tatsächlich an der Schnittstelle zwischen Informatik und Linguistik. Es handelt sich um die Fähigkeit der Maschine, direkt mit dem Menschen zu interagieren.
Welche Probleme werden mit NLP behandelt?
NLP ist ein recht allgemeiner Begriff, der ein sehr breites Spektrum von Anwendungen abdeckt. Hier sind die beliebtesten Anwendungen:
Maschinenübersetzung
Die Entwicklung der Algorithmen für die Maschinenübersetzung hat die Art und Weise, wie Texte heute übersetzt werden, wirklich revolutioniert. Anwendungen wie Google Translator sind in der Lage, ganze Texte ohne menschliches Eingreifen zu übersetzen.
Da natürliche Sprache von Natur aus mehrdeutig und variabel ist, beruhen diese Anwendungen nicht auf einer Wort-für-Wort-Übersetzung, sondern erfordern eine tatsächliche Textanalyse und -modellierung, die als statistische maschinelle Übersetzung (Statistical Machine Translation auf Englisch) bezeichnet wird.
Sentiment-Analyse
Bei der Stimmungsanalyse, die auch als „Opinion Mining” bezeichnet wird, geht es darum, subjektive Informationen in einem Text zu identifizieren, um die Meinung der Autorin bzw. des Autors zu extrahieren.
Wenn eine Marke beispielsweise ein neues Produkt auf den Markt bringt, kann sie die in den sozialen Netzwerken gesammelten Kommentare nutzen, um die von den KundInnen insgesamt geteilte positive oder negative Stimmung zu ermitteln.
Im Allgemeinen kann die Stimmungsanalyse dazu gebraucht werden, den Grad der KundInnenzufriedenheit mit den von einem Unternehmen oder einer Organisation angebotenen Produkten oder Dienstleistungen zu messen. Sie kann sogar effektiver sein als traditionelle Methoden wie Umfragen.
Während die Menschen oft nicht bereit sind, lange Fragebögen auszufüllen, teilen immer mehr VerbraucherInnen ihre Meinung in sozialen Netzwerken. So kann die Suche nach negativen Texten und die Identifizierung der wichtigsten Beschwerden dazu beitragen, Produkte zu verbessern, die Werbung anzupassen und den Grad der Unzufriedenheit der KundInnen zu verringern.
Marketing
MarketingspezialistInnen nutzen NLP auch, um Personen zu finden, die wahrscheinlich einen Kauf tätigen werden.
Grundlage dafür ist das NutzerInnenverhalten auf Websites, in sozialen Netzwerken und bei Suchanfragen. Diese Art der Analyse ermöglicht es Google, einen erheblichen Gewinn zu erzielen, indem es den richtigen Leuten die richtige Werbung anbietet. Jedes Mal, wenn BesucherInnen auf eine Anzeige klicken, zahlt der Inserent bis zu 50 Dollar!
Ganz allgemein können NLP-Methoden eingesetzt werden, um ein umfassendes Bild des bestehenden Marktes, der KundInnen, der Probleme, der Konkurrenz und des Wachstumspotenzials neuer Produkte und Dienstleistungen eines Unternehmens zu erstellen.
Zu den Quellen der Primärdaten für diese Analyse gehören Rechnungsbücher, Umfragen und soziale Medien…
Chatbots
NLP-Methoden, wie sie von fortschrittlichen Technologien wie ChatGPT und Open AI angeboten werden, stehen heute im Mittelpunkt der Funktionsweise moderner Chatbots. Diese Systeme haben sich in den letzten Jahren kontinuierlich weiterentwickelt und können jetzt Standardaufgaben problemlos bewältigen, wie zum Beispiel Kundinnen über Produkte oder Dienstleistungen informieren, Fragen beantworten und vieles mehr.
Chatbots werden über verschiedene Kanäle wie das Internet, Apps und Instant-Messaging-Dienste eingesetzt, um eine nahtlose und effiziente Interaktion mit den Nutzerinnen zu ermöglichen.
Besonders die Öffnung von Facebook Messenger für Chatbots im Jahr 2016 hat zu einer rapiden Entwicklung dieser Technologie beigetragen und neue Möglichkeiten eröffnet.
Fragen wir doch mal ChatGPT zum Beruf des Data Scientists:

Was ist Natural Language Processing vs. KI ?
Natürliche Sprachverarbeitung (NLP) ist ein Teilgebiet der Künstlichen Intelligenz (KI), das sich mit der Interaktion zwischen Computern und menschlicher Sprache befasst. NLP-Methoden ermöglichen es Maschinen, menschliche Sprache zu verstehen, zu analysieren und darauf zu reagieren. In der heutigen Zeit spielen NLP-Methoden eine entscheidende Rolle in der Funktionsweise von Chatbots.
Chatbots sind automatisierte Systeme, die menschenähnliche Gespräche führen können. Sie nutzen NLP-Methoden, um Texteingaben von Nutzerinnen zu analysieren, zu verstehen und darauf zu antworten.
Durch den Einsatz von fortschrittlichen Algorithmen und maschinellem Lernen sind moderne Chatbots in der Lage, in Echtzeit auf die Anfragen von Nutzerinnen zu reagieren und intelligente Antworten zu generieren.
Die Einsatzmöglichkeiten von Chatbots sind vielfältig. Sie können in Kundenservice, Verkauf, Marketing und vielen anderen Bereichen eingesetzt werden, um Nutzer*innen zu unterstützen und ihnen eine personalisierte Erfahrung zu bieten. Chatbots können beispielsweise Produktempfehlungen geben, Bestellungen entgegennehmen, Buchungen durchführen, FAQ beantworten und vieles mehr.
Ein wichtiger Fortschritt im Bereich der NLP-Methoden für Chatbots ist die Fähigkeit zur Sentiment-Analyse, also zur Erkennung von Emotionen und Stimmungen in Texten. Moderne Chatbots können nicht nur den Inhalt einer Nachricht verstehen, sondern auch die Emotionen dahinter erkennen, um entsprechend darauf zu reagieren.
Es ist jedoch wichtig zu beachten, dass Chatbots noch nicht perfekt sind und ihre Fähigkeiten weiterhin verbessert werden können. Die Herausforderungen in der NLP-Forschung und Entwicklung von Chatbots liegen unter anderem in der Verbesserung der Sprachverständnis-Fähigkeiten, der Erkennung von Ironie, der Unterstützung von mehreren Sprachen und der Berücksichtigung von kulturellen Unterschieden.
Trotzdem ist die Kombination von NLP-Methoden und Chatbots ein spannendes Feld mit großem Potenzial für die Zukunft.
Mit der Weiterentwicklung von KI-Technologien wie ChatGPT und Open AI werden wir voraussichtlich noch fortschrittlichere und leistungsfähigere Chatbots sehen, die in der Lage sind, menschenähnliche Gespräche zu führen und noch mehr Aufgaben effizient zu bewältigen.
Andere Anwendungsbereiche
- Textklassifizierung: Hier geht es darum, einem gegebenen Text eine Reihe vordefinierter Kategorien zuzuordnen. Textklassifikatoren können angewandt werden, um eine Reihe von Texten zu organisieren, zu strukturieren und zu kategorisieren.
- Zeichenerkennung: Diese Funktion extrahiert Schlüsselinformationen aus Quittungen, Rechnungen, Schecks, juristischen Abrechnungsunterlagen usw. auf der Grundlage der Zeichenerkennung.
- Automatische Korrektur: Die meisten Texteditoren verfügen heute über eine Rechtschreibprüfung, die den Text auf Rechtschreibfehler überprüft.
- Automatische Zusammenfassung: NLP-Methoden werden auch eingesetzt, um kurze, präzise und flüssige Zusammenfassungen eines längeren Textdokuments zu erstellen.
Was sind die wichtigsten Methoden im NLP?
Im Großen und Ganzen können wir zwei Aspekte unterscheiden, die für jedes NLP-Problem wesentlich sind:
- Der „linguistische” Teil, der aus der Vorverarbeitung und Umwandlung der eingegebenen Informationen in einen verwertbaren Datensatz besteht.
- Der Teil des „maschinellen Lernens“ oder von „Data Science„, der die Anwendung von Modellen von Machine Learning oder Deep Learning auf diesen Datensatz beinhaltet.
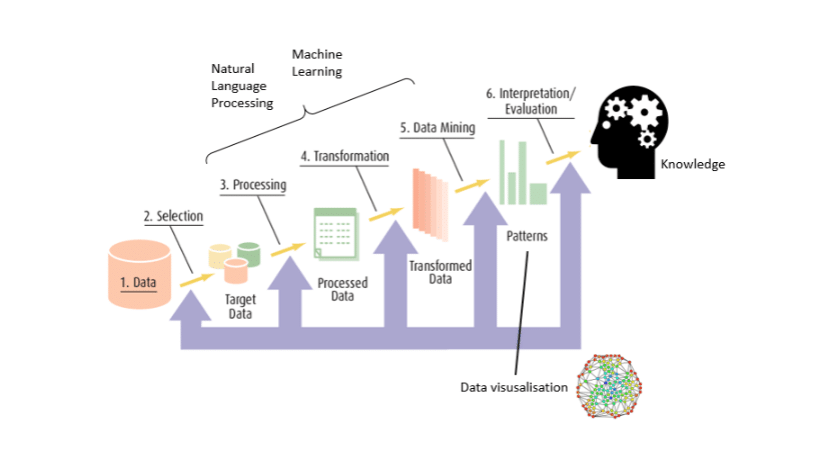
Im Folgenden werden wir diese beiden Aspekte erörtern, die wichtigsten Methoden kurz beschreiben und die größten Herausforderungen hervorheben. Nehmen wir ein klassisches Beispiel: die Spam-Erkennung.
Die Vorverarbeitungsphase: vom Text zu den Daten
Nehmen wir an, Du möchtest in der Lage sein, allein anhand des Inhalts einer E-Mail festzustellen, ob es sich um Spam handelt oder nicht. Dazu ist es notwendig, die Primärdaten (den Text der E-Mail) in verwertbare Daten umzuwandeln.
Die wichtigsten Schritte sind:
- Bereinigung: Je nach Datenquelle besteht diese Phase aus der Durchführung von Aufgaben wie Löschen von URLs, Emoji usw.
- Normalisierung der Daten:
- Tokenisierung, d. h. Aufteilung des Textes in mehrere Teile, die Tokens genannt werden.
Beispiel: „Sie finden das betreffende Dokument in der Anlage”; „Sie”, „finden“, „in der Anlage“, „das Dokument“, „betreffend“.
- Tokenisierung, d. h. Aufteilung des Textes in mehrere Teile, die Tokens genannt werden.
- Stemming: Ein und dasselbe Wort kann in verschiedenen Formen vorkommen, je nach Geschlecht (männlich, weiblich, neutral), Zahl (Singular, Plural), Person (ich, du, sie, usw.), usw. Stemming bezieht sich im Allgemeinen auf den groben heuristischen Prozess des Abschneidens von Wortendungen, um nur den Wortstamm zu erhalten.
Beispiel: „finden“ -> „find-„.
- Lemmatisierung: Diese besteht darin, dieselbe Aufgabe auszuführen, aber mit einem Wortschatz und einer genauen Analyse des Wortaufbaus. Die Lemmatisierung ermöglicht es, nur die unflexiblen Endungen zu entfernen und so die kanonische Form des Wortes, das so genannte Lemma, zu isolieren. Beispiel: „gefunden“ -> „finden”
- Andere Operationen: Löschen von Zahlen, Interpunktionszeichen, Symbolen und stopwords, Umstellung auf Kleinschreibung.
Um Machine Learning-Methoden auf natürlichsprachliche Probleme anwenden zu können, müssen Textdaten in numerische Daten umgewandelt werden.
Es gibt mehrere Ansätze, von denen die wichtigsten die folgenden sind:
- Term-Frequency (TF): Diese Methode besteht darin, die Anzahl der Vorkommen von Tokens im Korpus für jeden Text zu zählen. Jeder Text wird dann durch einen Vektor von Vorkommnissen dargestellt. Dies wird im Allgemeinen als Bag-Of-Word bezeichnet.

Dieser Ansatz hat jedoch einen großen Nachteil: Einige Wörter werden von Natur aus häufiger verwendet als andere, was das Modell zu fehlerhaften Ergebnissen führen kann.
- Term Frequency-Inverse Document Frequency (TF-IDF): Diese Methode besteht darin, die Anzahl der Vorkommen der Token im Korpus für jeden Text zu zählen, die dann durch die Gesamtzahl der Vorkommen derselben Token im gesamten Korpus geteilt wird.
Für das X-Element, der im Y-Dokument vorkommt, können wir seine Wichtigkeit durch die folgende Beziehung definieren:

Wo :
- tƒx,y ist die Häufigkeit des Begriffs x in y ;
- dƒx ist die Anzahl der Dokumente, die x enthalten;
- N ist die Gesamtzahl der Dokumente.
Dieser Ansatz liefert also für jeden Text eine Vektordarstellung, die Vektoren der Wichtigkeit und nicht mehr der Vorkommen enthält.
Die Effizienz dieser Methoden ist je nach Anwendungsfall unterschiedlich. Sie weisen jedoch zwei wesentliche Einschränkungen auf:
- Je umfangreicher das Vokabular des Korpus ist, desto größer sind die Vektoren, was ein Problem für die im nächsten Schritt verwendeten Lernmodelle darstellen kann.
- Das Zählen der Wortvorkommen erlaubt es uns nicht, die Anordnung der Wörter und damit die Bedeutung der Sätze zu berücksichtigen.
Es gibt einen weiteren Ansatz, der diese Probleme beheben kann: Word Embedding. Sie besteht darin, Vektoren fester Größe zu konstruieren, die den Kontext berücksichtigen, in dem die Wörter gefunden werden.
Zwei Wörter, die in einem ähnlichen Kontext stehen, haben also engere Vektoren (in Bezug auf den Vektorabstand). Auf diese Weise lassen sich sowohl semantische als auch syntaktische oder thematische Ähnlichkeiten von Wörtern erfassen.
Eine genauere Beschreibung dieser Methode wird in einem späteren Abschnitt gegeben.
>> Auch interessant: Natürliche Sprachverarbeitung in Python
Die Lernphase: Von den Daten zum Modell
Insgesamt lassen sich 3 wesentliche NLP-Ansätze unterscheiden: regelbasierte Methoden, klassische Machine Learning-Modelle und Deep Learning-Modelle.
Regelbasierte Methoden
Regelbasierte Methoden beruhen in hohem Maße auf der Entwicklung domänenspezifischer Regeln (z. B. reguläre Ausdrücke). Sie können zur Lösung einfacher Probleme wie der Extraktion strukturierter Daten aus unstrukturierten Daten (z. B. Webseiten) angewandt werden.
Im Falle der Spam-Erkennung könnte dies bedeuten, dass E-Mails, die Schlagworte wie „Promotion“, „begrenztes Angebot“ usw. enthalten, als Spam eingestuft werden.
Diese einfachen Methoden können jedoch schnell von der Komplexität der natürlichen Sprache überfordert werden und sich als unwirksam erweisen.
Klassische Modelle des Machine Learning
Klassische maschinelle Lernverfahren können zur Lösung schwierigerer Probleme eingesetzt werden. Im Gegensatz zu Methoden, die auf vordefinierten Regeln beruhen, basieren sie auf Methoden, bei denen es wirklich um Sprachverständnis geht. Sie nutzen Daten, die beispielsweise mit einer der oben beschriebenen Methoden aus vorverarbeitetem Primärtext gewonnen wurden. Sie können auch Daten über die Satzlänge, das Vorkommen bestimmter Wörter usw. anwenden. Sie implementieren in der Regel ein statistisches maschinelles Lernmodell wie Naive Bayes, Logit-Modell usw.
Modelle für tiefes Lernen
Die Anwendung von Deep-Learning-Modellen für NLP-Probleme ist derzeit Gegenstand zahlreicher Forschungsarbeiten.
Diese Modelle lassen sich noch besser verallgemeinern als klassische Lernansätze, da sie eine weniger ausgefeilte Textvorverarbeitungsphase erfordern: Die neuronalen Schichten können als automatische Merkmalsextraktoren betrachtet werden.
Dies ermöglicht die Erstellung von End-to-End-Modellen mit geringer Datenvorverarbeitung. Abgesehen vom Feature-Engineering sind die Lernfähigkeiten von Deep-Learning-Algorithmen im Allgemeinen leistungsfähiger als die des klassischen Machine Learning, was ermöglicht, bei verschiedenen komplexen, schwierigen NLP-Aufgaben wie z. B. Übersetzungen bessere Ergebnisse zu erzielen.
Was sind die Perspektiven und Herausforderungen des NLP?
Die Regeln, die für die Umwandlung von natürlichem Text in Informationen gelten, sind für Computer nicht leicht zu verstehen.
Man muss sowohl die Wörter verstehen als auch die Art und Weise, wie die Konzepte miteinander verbunden sind, um die gewünschte Botschaft zu vermitteln.
Zu den wichtigsten Herausforderungen gehören:
Zweideutigkeit
In der natürlichen Sprache sind Wörter eindeutig, können aber in verschiedenen Kontexten unterschiedliche Bedeutungen haben, was zu lexikalischer, syntaktischer und semantischer Mehrdeutigkeit führt. Um dieses Problem zu lösen, schlägt das NPL mehrere Methoden vor, z. B. die Bewertung des Kontexts. Die semantische Bedeutung der Wörter in einem Satz zu verstehen, ist jedoch noch nicht ganz ausgereift.
Synonymie
Ein weiteres Schlüsselphänomen der natürlichen Sprache ist, dass wir dieselbe Idee mit verschiedenen Begriffen ausdrücken können, die auch vom jeweiligen Kontext abhängen.
Beispielsweise können die Begriffe „groß“ und „breit“ bei der Beschreibung eines Gegenstands oder eines Gebäudes synonym sein, aber sie sind nicht in allen Zusammenhängen austauschbar: „groß“ kann auch wichtig bedeuten.
Koreferenz
Bei Koreferenzaufgaben geht es darum, alle Ausdrücke zu finden, die sich auf dieselbe Entität beziehen. Dies ist ein wichtiger Schritt für viele anspruchsvolle NLP-Aufgaben, die ein Verständnis des gesamten Textes erfordern, wie z. B. die Zusammenfassung von Dokumenten, die Beantwortung von Fragen und die Informationsextraktion. Dieses Problem wurde mit der Einführung moderner Deep-Learning-Techniken wiederbelebt.
Schreibstil
Je nach der Persönlichkeit, den Absichten und den Gefühlen der AutorInnen kann ein und derselbe Gedanke auf unterschiedliche Weise ausgedrückt werden.
Einige AutorInnen zögern nicht, Ironie oder Sarkasmus zu verwenden und damit eine Bedeutung zu vermitteln, die der wörtlichen Bedeutung entgegengesetzt ist.
Während Menschen eine Sprache leicht beherrschen können, sind es die Mehrdeutigkeit und die Ungenauigkeit natürlicher Sprachen, die es Maschinen schwer machen, NLP zu implementieren.
Willst Du die Kunst des NLP beherrschen? Der Rest unserer Features folgt in Kürze! Nächste Folge: Wie kann ein Wort dank Word Embedding durch einen Vektor dargestellt werden?
Referenzen:
- P. Olivier, Introduction to NLP (Part. I), Ekino
- P. Olivier, Introduction to NLP (Part. I), Ekino
- I. ElDen, Introduction to Natural Language Processing (NLP), Towards Data Science, September 2017
- O. Kharkovyna, Natural Language Processing (NLP): Top 10 Applications to Know, Towards Data Science, December 2019
- Sciforce, Biggest Open Problems in Natural Language Processing, February 2020
- An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec, Analytics Vidhya, June 2017
- S. Ananiadou, J. McNaught, The Natural Language Processing and Text Mining, University of Manchester
- P. Clough and F. Borg, Unlocking Insights from Unstructured Data with Text Mining, December 2019







