Dieser Artikel ist der erste einer Reihe von Artikeln über Deep Learning: Zunächst stellen wir Dir die Funktionsweise und die Anwendungen neuronaler Netze im Großen und Ganzen vor. Dann erfährst Du hier mehr über die wichtigsten Arten von Netzen und ihre Architektur und Du lernst Methoden und verschiedene Beispiele für die heutige Anwendung von Deep Learning. Los geht’s !
KI, Machine Learning und Deep Learning, Was ist was ?
Seit einigen Jahren ist in den wissenschaftlichen Artikeln ein neues Lexikon zu finden, das mit dem Aufkommen der künstlichen Intelligenz in unserer Gesellschaft zusammenhängt. Es ist manchmal schwierig zu verstehen, worum es sich dabei handelt. Künstliche Intelligenz verweist sehr oft auf die damit verbundenen Technologien wie Machine Learning oder Deep Learning. Diese beiden Begriffe werden häufig verwendet und haben immer mehr Anwendungen, werden jedoch nicht immer klar definiert. Lass uns zunächst auf diese drei wesentlichen Definitionen zurückkommen:
- Künstliche Intelligenz: Es handelt sich um ein Forschungsfeld, das alle Techniken und Methoden umfasst, um die Funktionsweise eines menschlichen Gehirns zu verstehen und zu reproduzieren.
- Machine Learning: Es handelt sich um eine Reihe von Techniken, die Maschinen die Fähigkeit verleihen, Gesetzmäßigkeiten in den Lerndaten automatisch zu erkennen, im Gegensatz zur Programmierung, bei der vorbestimmte Regeln ausgeführt werden.
- Deep Learning: Es ist eine Technik des maschinellen Lernens, die auf dem Modell der neuronalen Netze basiert: Dutzende oder sogar Hunderte von Schichten von Neuronen werden gestapelt, um die Komplexität der Regeln zu erhöhen.
Unterschiede zwiszchen KI, Machine Learning und Deep Learning - Eine Übersicht
| Aspekt | Künstliche Intelligenz (KI) | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|---|
| Definition | KI bezieht sich auf die Simulation menschlicher Intelligenz in Maschinen, um Aufgaben auszuführen, die normalerweise menschliches Denken erfordern. | ML bezieht sich auf Algorithmen und Techniken, die es Computern ermöglichen, aus Daten zu lernen und Vorhersagen oder Entscheidungen zu treffen. | DL ist ein Teilbereich des ML, der auf künstlichen neuronalen Netzwerken mit vielen Schichten basiert und komplexe Muster in Daten erlernen kann. |
| Datenbedarf | Kann sowohl große als auch kleine Datensätze verarbeiten. | Erfordert normalerweise eine ausreichende Menge an Daten für das Training. | Erfordert oft eine große Menge an Daten für das Training aufgrund der Komplexität der Modelle. |
| Merkmalsextraktion | Verwendet sowohl handcodierte als auch lernbasierte Merkmalsextraktion. | Lernt automatisch relevante Merkmale aus den Daten. | Lernt automatisch relevante Merkmale aus den Daten. |
| Anwendungsbereiche | Enthält verschiedene Bereiche wie Spracherkennung, Bildverarbeitung, Robotik usw. | Wird in verschiedenen Bereichen wie Vorhersagen, Mustererkennung, Anomalieerkennung usw. eingesetzt. | Häufig in Bild- und Spracherkennung, Natur- und medizinischer Bildgebung, Sprachverarbeitung usw. |
| Modellinterpretierbarkeit | Die Interpretierbarkeit der Modelle kann eine Herausforderung sein. | Modelle können interpretierbar sein und abhängig vom ML-Algorithmus variieren. | Die Interpretierbarkeit der Modelle kann aufgrund der Komplexität der Netzwerke schwierig sein. |
| Rechenleistung | Erfordert oft hohe Rechenleistung und Ressourcen für komplexe Aufgaben. | Erfordert weniger Rechenleistung im Vergleich zu KI und DL. | Kann hohe Rechenleistung und spezialisierte Hardware wie GPUs für das Training erfordern. |
Machine Learning: Überwachtes und unüberwachtes Lernen
Mit Machine Learning kann ein künstliches System lernen, im Gegensatz zur Programmierung, bei der es um die Ausführung vorgegebener Regeln geht.
Es gibt zwei Hauptarten des Lernens beim Machine Learning:
- Das überwachte Lernen
- Das unüberwachte Lernen
Machine Learning – Überwachtes Lernen
Beim überwachten Lernen wird der Algorithmus mit Vorwissen darüber geführt, was die Ausgabewerte des Modells sein sollten.
Infolgedessen passt das Modell seine Parameter so an, dass die Abweichung zwischen den erzielten und den erwarteten Ergebnissen geringer wird.
Je öfter das Modell trainiert wird, desto kleiner wird die Fehlerquote, wodurch es auf neue Fälle anwendbar wird.
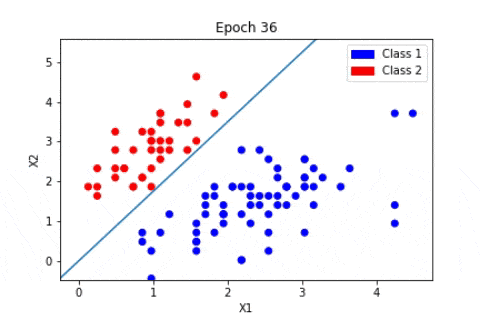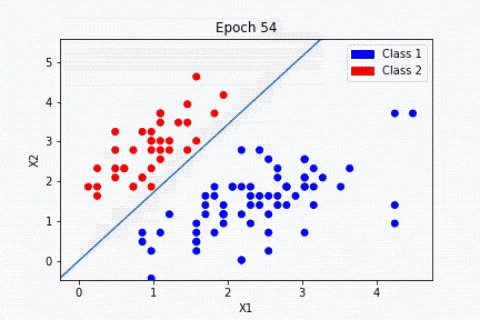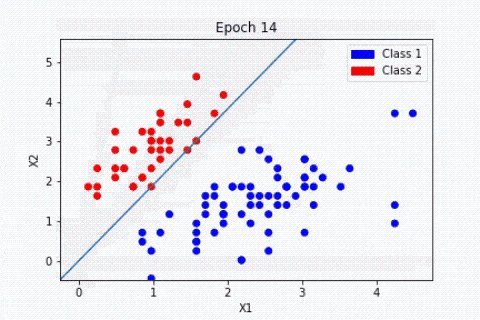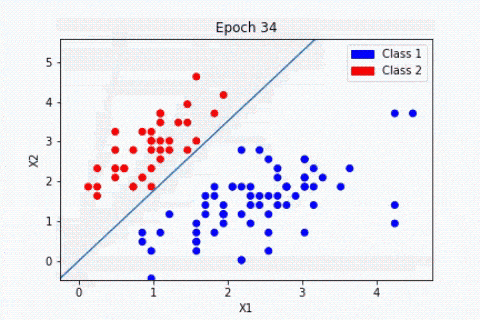
Machine Learning unüberwachtes Lernen
Im Gegensatz dazu werden beim unüberwachten Lernen keine mit Tags versehenen Daten verwendet. Daher kann der Algorithmus keine Erfolgsquote mit Sicherheit berechnen.
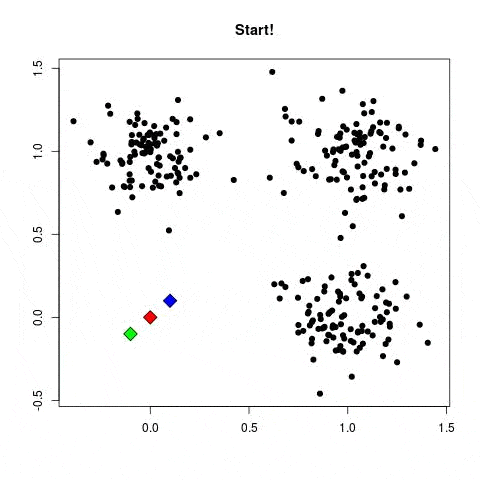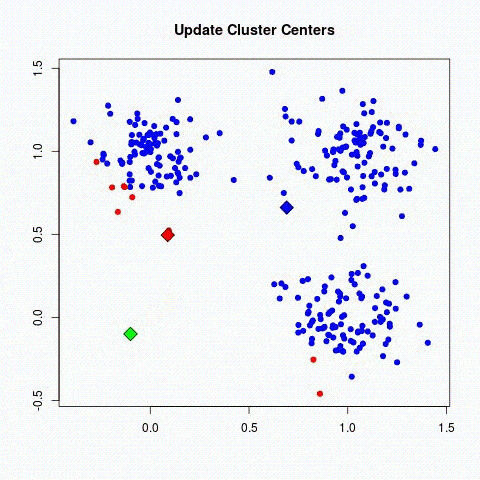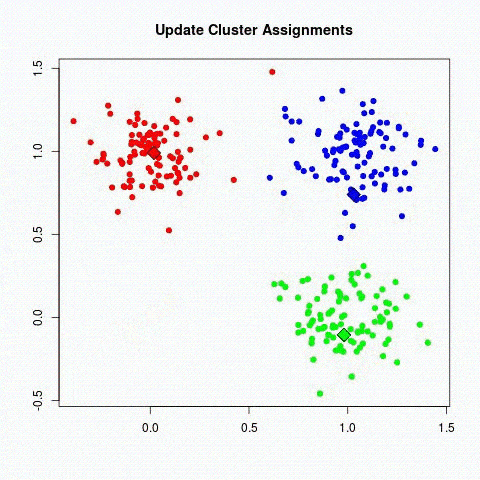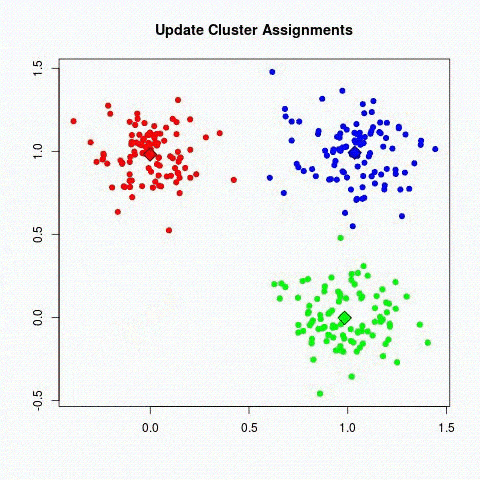
Daher ist sein Ziel, die in unseren Daten vorhandenen Gruppierungen einzuteilen.
Nehmen wir als Beispiel einen Datensatz mit Blumen: Wir möchten sie in Kategorien unterscheiden. Hier kennen wir die Art der Pflanze nicht, aber wir wollen versuchen, sie in Kategorien einzuteilen.
Zum Beispiel: Wenn die Formen der Blüten ähnlich sind, hängen sie mit einer gleichen entsprechenden Pflanze zusammen.
Es gibt zwei Hauptbereiche von Modellen im unbeaufsichtigten Lernen, um Kategorien zu finden:
- Methoden durch Partitioning: k-means-Algorithmen.
- Hierarchische Clustering-Methoden: die agglomerativen Clusterverfahren
Deep Learning, was ist das ?
Deep Learning oder tiefes Lernen ist eine der Haupttechnologien des Machine Learning. Bei Deep Learning sprechen wir von Algorithmen, die mithilfe künstlicher neuronaler Netze die Handlungen des menschlichen Gehirns nachmachen können. Die Netze bestehen aus Dutzenden oder sogar Hunderten von „Schichten” von Neuronen, die die Informationen der vorherigen Schicht empfangen und interpretieren.
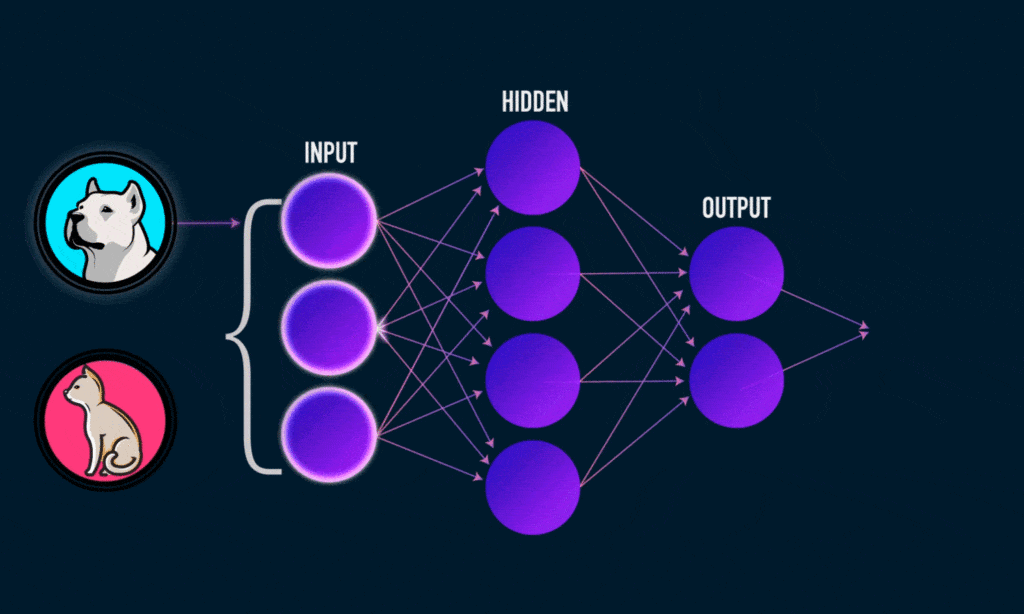
Jedes künstliche Neuron, das im vorherigen Bild mit einem Kreis dargestellt wird, kann als lineares Modell betrachtet werden. Indem wir die Neuronen in Form einer Schicht miteinander verbinden, verwandeln wir unser neuronales Netz in ein sehr komplexes nichtlineares Modell.
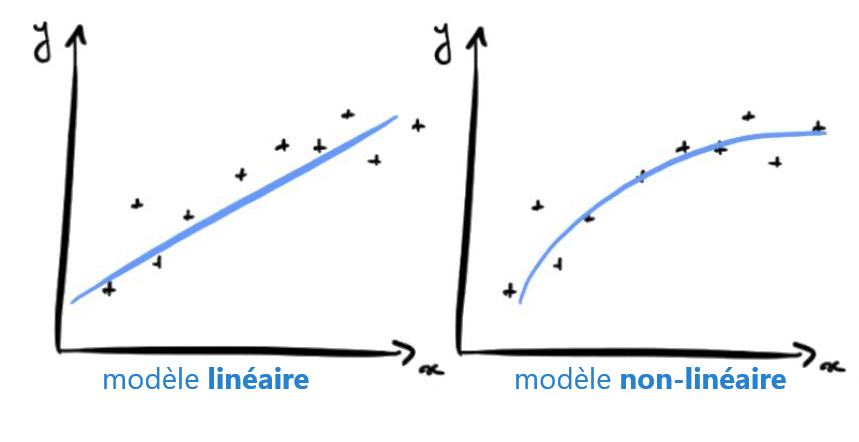
Um das Konzept zu veranschaulichen, nehmen wir ein Problem, bei dem es darum geht, anhand von Bildern einen Hund oder eine Katze zu unterscheiden. Beim Lernen wird der Algorithmus die Gewichte der Neuronen so anpassen, dass die Abweichung zwischen den erhaltenen und den erwarteten Ergebnissen verringert wird. Das Modell kann lernen, Dreiecke in einem Bild zu erkennen, da Katzen dreieckigere Ohren als Hunde haben.
Wozu braucht man Deep Learning ?
Deep-Learning-Modelle funktionieren häufig auch bei großen Datenmengen gut, im Gegensatz zu klassischeren Modellen des maschinellen Lernens , die nach einem Sättigungspunkt aufhören, sich zu verbessern.
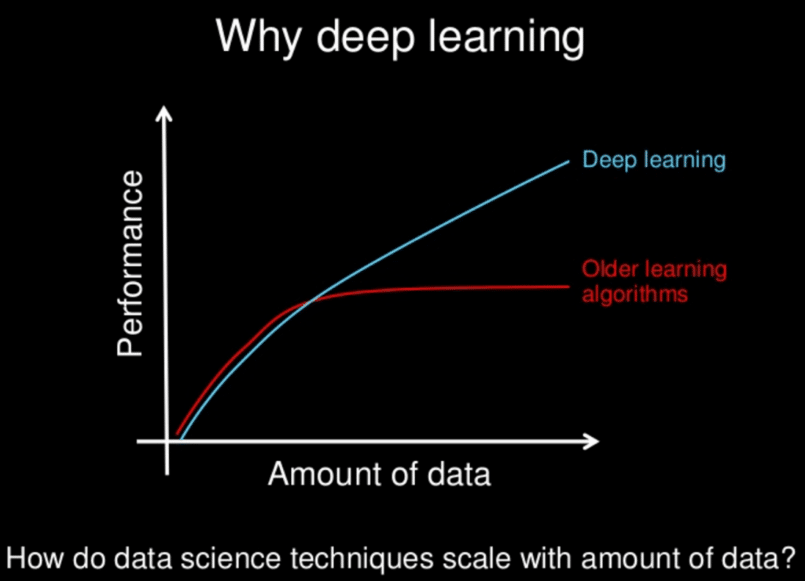
Mit den Jahren und dem Aufkommen von Big Data und immer leistungsfähigeren Computerkomponenten, haben die leistungs- und datenintensiven Deep-Learning-Algorithmen die meisten anderen Methoden überholt. Offensichtlich können sie viele Probleme lösen: Gesichter erkennen, Go- oder PokerspielerInnen besiegen, das Fahren von selbstfahrenden Autos ermöglichen oder nach Krebszellen suchen.
KI in der Berufswelt
Fast alle Branchen werden von KI betroffen. Machine Learning und Deep Learning spielen dabei eine große Rolle.
Ob Du nun im Gesundheitswesen tätig bist oder als Anwalt arbeitest, es ist möglich, dass Du eines Tages von einem hochgradig autonomen Modell unterstützt oder sogar ersetzt wirst.
In den Gesundheitsberufen gibt es bereits Anwendungen, mit denen PatientInnen automatisch diagnostiziert werden.
Auch die Berufe in der Automobilbranche werden mit dem Aufkommen des assistierten Fahrens revolutioniert.
Auch Googles Alpha-Go-Modell hat es dank Deep Learning geschafft, 2016 die besten Go-Champions zu schlagen. Die Suchmaschine des amerikanischen Riesen basiert selbst zunehmend auf Deep Learning statt auf geschriebenen Regeln.
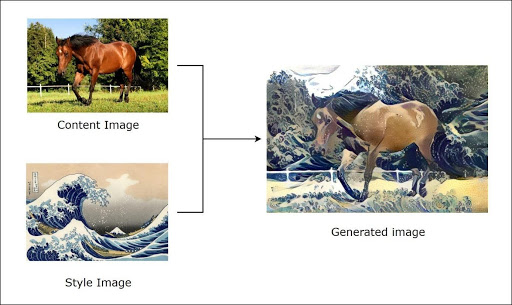
Heute ist Deep Learning sogar in der Lage, selbstständig die Kunstbilder zu „erstellen“. Dies wird als Style Transfer bezeichnet. Interessiert Dich das Thema? Einen Artikel, der sich ganz diesem Thema widmet, findest Du bald auf unserem Blog!
Im Folgenden werden wir Dir neuronale Netze mit einem neuartigen Ansatz vorstellen. Wir hoffen, dass es Dir gefällt!
Deepl Learning Anwendungsfälle
Deep Learning als Lösung im E-Commerce
Offensichtlich werden große Datenmengen im Bereich des E-Commerce erzeugt. Unternehmen, HändlerInnen und EinzelhändlerInnen sind sich dessen bewusst, dass Big-Data-Lösungen zur Verwaltung ihrer Geschäfte sie wertvoller machen werden. Trotz des Aufkommens all dieser innovativen Lösungen kann Big Data einen Segen oder einen Fluch darstellen, je nachdem, wie es genutzt und angewendet wird.
Mit der Revolution der künstlichen Intelligenz kann man die Verwaltung dieser riesigen Datenmenge mithilfe intelligenter Technologien wie Deep Learning erleichtern. Sie ist von entscheidender Bedeutung, da sie Material für eine bessere Datenanalyse liefert.
In einem praktischen Fall ermöglicht die KI-Analyse einem Online-Shop, seinen Kundinnen und Kunden leichter interessante Produkte anzubieten, ihre Vorlieben hervorzuheben und sie persönlich zu betreuen.
Zu diesem Zweck automatisiert Deep Learning die sogenannte prädiktive Analyse. Dank dieser können Kundinnen und Kunden bei einem Kauf Vorschläge erhalten.
Deep Learning definiert einen Stil, um E-Commerce zu entwickeln. Es geht nämlich nicht darum, Online-Websites zu erstellen, die einen großen Anteil an Käuferinnen und Käufern anziehen.
Vielmehr geht es darum, klare und personalisierte Botschaften an jede einzelne und jeden einzelnen von ihnen zu senden.
Big Data wird mithilfe von Deep Learning einer gründlichen Analyse unterzogen, was dazu führt, dass den Kundinnen und Kunden der Kaufprozess erleichtert wird.
Deep-Learning-Algorithmen helfen dem Unternehmen, eine bessere Erfahrung zu machen und den Überblick darüber zu behalten, wer seine Website besucht hat.
Deep Learning ist da, um die Entwicklung des E-Commerce zu erleichtern. Der Online-Verkauf wird durch Technologietrends wie Chatbots stimuliert.
In gewisser Weise definiert Deep Learning den Onlinehandel neu, dabei erleben wir noch dessen Anfänge. Daher werden diejenigen, die es einsetzen, mehr Vorteile haben.
Weitere Anwendungsfälle von Deep Learning
Bild- und Spracherkennung:
Deep Learning wird häufig in der Bilderkennung eingesetzt, um Objekte, Gesichter, Muster und Merkmale in Bildern zu erkennen und zu klassifizieren. Es wird auch zur Spracherkennung verwendet, um gesprochene Wörter in Text umzuwandeln oder Sprachbefehle zu verstehen.
Natur- und medizinische Bildgebung:
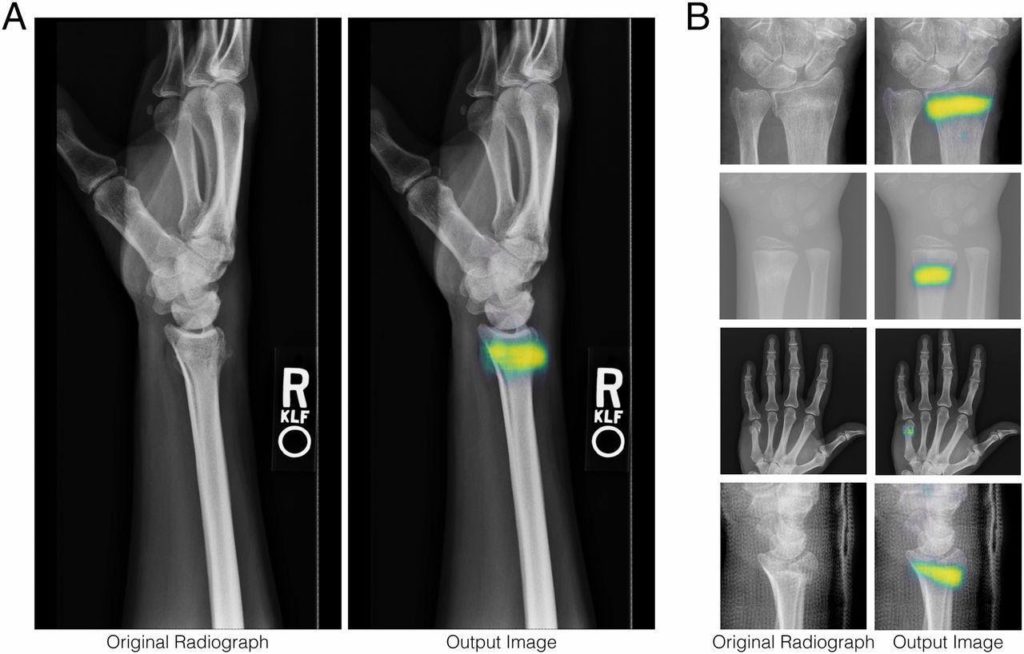
Deep Learning ermöglicht es, komplexe Muster in medizinischen Bildern wie MRT-Scans, CT-Scans oder Röntgenbildern zu erkennen. Es kann bei der Diagnose von Krankheiten, der Identifizierung von Anomalien und der Vorhersage von Behandlungsergebnissen helfen.
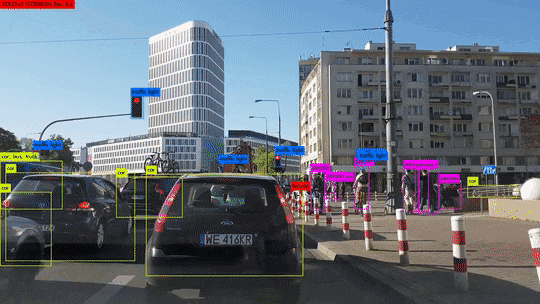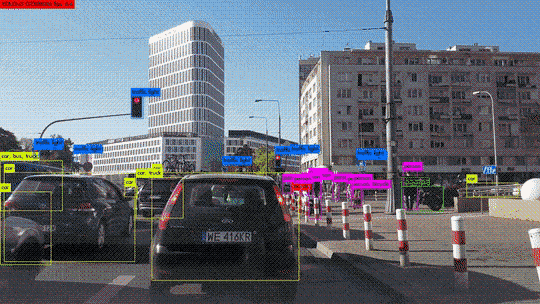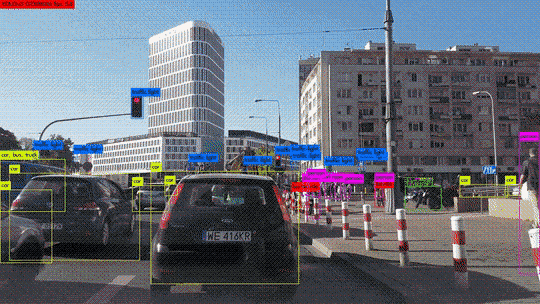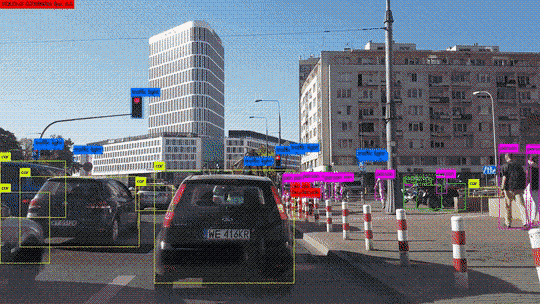
Autonome Fahrzeuge:
Deep Learning wird in der Entwicklung von autonomen Fahrzeugen eingesetzt, um visuelle und sensorische Daten aus der Umgebung zu analysieren und zu interpretieren. Es hilft bei der Erkennung von Verkehrsschildern, Fußgängern, Fahrzeugen und anderen Hindernissen.
Natürliche Sprachverarbeitung:
Deep Learning wird verwendet, um menschliche Sprache zu verstehen, zu analysieren und zu generieren. Es ermöglicht maschinelle Übersetzungen, Chatbots, Texterkennung und Sentimentanalyse.
Empfehlungssysteme:
Deep Learning kann in Empfehlungssystemen eingesetzt werden, um personalisierte Vorschläge für Produkte, Filme, Musik oder Nachrichten basierend auf Benutzerpräferenzen und Verhaltensmustern zu machen.
Finanzwesen:
Deep Learning kann im Finanzwesen zur Vorhersage von Aktienkursen, Betrugsprävention, Kreditrisikobewertung und automatisierten Handelsstrategien eingesetzt werden.
Robotik:
Deep Learning ermöglicht es Robotern, ihre Umgebung wahrzunehmen, Hindernisse zu erkennen, Objekte zu greifen und komplexe Aufgaben auszuführen. Es spielt eine wichtige Rolle in der Entwicklung von autonomen Robotern und industriellen Automationssystemen.

Welche Deep Learning Frameworks gibt es ?
Hier ist eine Tabelle mit einigen der gängigsten Deep Learning-Frameworks:
| Framework | Programmiersprache(n) | Beschreibung |
|---|---|---|
| TensorFlow | Python, C++, Java | Ein leistungsstarkes und flexibles Framework von Google. Es bietet eine breite Palette von Tools und Funktionen für Deep Learning. |
| PyTorch | Python | Ein beliebtes Deep Learning-Framework, das von Facebook entwickelt wurde. Es zeichnet sich durch eine einfache Syntax und eine dynamische Ausführung aus. |
| Keras | Python | Eine benutzerfreundliche API, die auf TensorFlow aufbaut und die Entwicklung von Deep Learning-Modellen vereinfacht. |
| Caffe | C++, Python | Ein schnelles Framework, das für seine Effizienz und einfache Netzwerkdefinition bekannt ist. Es wurde ursprünglich für die Bildklassifikation entwickelt. |
| MXNet | Python, C++, R, Scala | Ein skalierbares Deep Learning-Framework, das für seine Effizienz auf mehreren GPUs und verteilten Systemen bekannt ist. |
| Theano | Python | Ein Framework, das wissenschaftliche Berechnungen und maschinelles Lernen ermöglicht. Es konzentriert sich auf effiziente Berechnungen von mathematischen Ausdrücken. |
| CNTK | C++, C#, Python | Das Cognitive Toolkit von Microsoft ist ein effizientes Deep Learning-Framework mit Fokus auf Skalierbarkeit und Geschwindigkeit. |
| TensorFlow.js | JavaScript | Eine JavaScript-Bibliothek für Deep Learning-Anwendungen im Web und Node.js. Sie ermöglicht die Ausführung von TensorFlow-Modellen im Browser. |
| PyTorch Lightning | Python | Eine Erweiterung von PyTorch, die die Entwicklung und das Training von Deep Learning-Modellen durch eine vereinfachte und strukturierte API vereinfacht. |
Unsere Deep Learning Reihe - Dive Deep 😉👇
Artikel 1 : Einführung in Deep Learning
Artikel 2 : Neuronale Netze: Biologisch VS Künstlich
Artikel 3 : Convolutional neural network
Artikel 4 : Funktionsweise von neuronalen Netzen
Artikel 5 : Transfer Learning







