
Da Python eine der am häufigsten verwendeten Programmierprachen ist, gibt es eine Vielzahl von Frameworks, von denen viele ausschließlich für Data Science entwickelt wurden. In diesem Artikel werden wir Ihnen einen dieser Frameworks näher vorstellen: PyTorch
Die Beliebtheit der Data Science hat in den letzten Jahren stetig zugenommen, was zu einer Explosion der Ressourcen für Programmierer geführt hat: Es muss nicht mehr alles von Hand codiert werden. Programmierumgebungen wie z.B. Pytorch. Mit Hilfe von Frameworks können komplexe Modelle in nur wenigen Zeilen verwendet werden.
Die Geschichte von Pytorch
Frameworks bieten eine Grundlage sowie Tools, um die Programmierung zu erleichtern. Sie werden in der Regel als „Open Source“ entwickelt, d.h. der Code ist für jeden zugänglich und kann von jedem bearbeitet werden, was Zuverlässigkeit, Transparenz und kontinuierliche Pflege ermöglicht.
PyTorch ist hier keine Ausnahme. PyTorch basiert auf der früheren Torch-Bibliothek und wurde 2016 von einem Team des Facebook-Forschungslabors offiziell eingeführt, seitdem wird es als Open Source entwickelt. Das Ziel dieses Frameworks ist es, die Implementierung und das Workout von Deep Learning Modellen auf einfache und effiziente Weise zu ermöglichen. Durch die Zusammenlegung mit Caffe2 (einem anderen Python-Framework) im Jahr 2018 wurde seine Leistung noch weiter verbessert.
Pytorch wird heute von 17% der Python-Entwickler (Studie der Python Foundation 2020) und in vielen Unternehmen wie Tesla, Uber usw. verwendet.
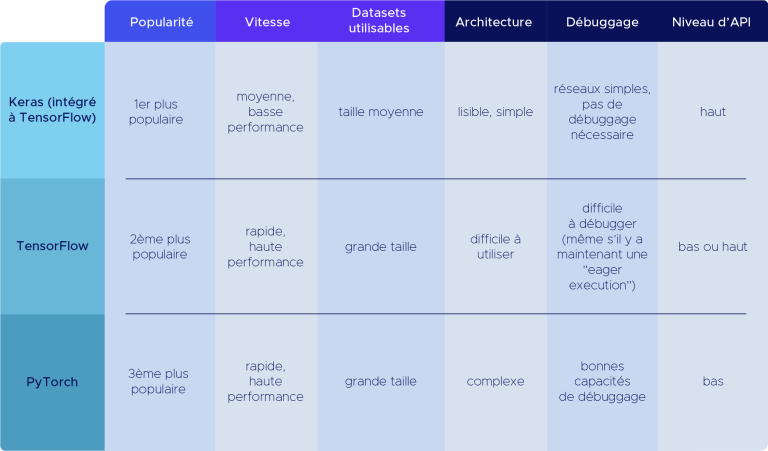
Pytorch vs. Keras vs. Tensorflow
Es ist schwierig, PyTorch vorzustellen, ohne sich die Zeit zu nehmen, über seine Alternativen zu sprechen, die alle im Abstand von einigen Jahren mit im Wesentlichen demselben Ziel, aber unterschiedlichen Methoden gegründet wurden.
Keras wurde im März 2015 von François Chollet, einem Forscher bei Google, entwickelt. Keras gewann schnell an Popularität dank seiner einfach zu bedienenden API, die sich stark an Python orientiert. scikit-learn. Die Software ist kompatibel mit der Standardbibliothek für Machine Learning von Python.
Einige Monate später, im November 2015, veröffentlichte Google eine erste Version von TensorFlow, das schnell zum Referenz-Framework für Deep Learning wurde, da es die Verwendung von Keras ermöglichte. Tensorflow entwickelte auch eine Reihe von Deep-Learning-Funktionen, die Forscher benötigten, um auf einfache Weise komplexe neuronale Netze zu erstellen.
Keras war daher sehr einfach zu bedienen, verfügte jedoch nicht über bestimmte „Low-Level“-Funktionen oder Anpassungen, die für fortgeschrittene Modelle erforderlich sind. Im Gegensatz dazu bot Tensorflow Zugang zu diesen Funktionen, sah aber nicht wie der übliche Stil von Python aus und hatte eine sehr komplizierte Dokumentation für Neulinge.
PyTorch hat diese Probleme gelöst, indem es eine leicht zugängliche und anpassbare API geschaffen hat, mit der Sie neue Netzwerktypen, Optimierer und neue Architekturen erstellen können.
Die jüngsten Entwicklungen dieser Frameworks haben ihre Arbeitsweise jedoch stark angeglichen. Bevor wir auf die technischen Details von PyTorch eingehen, finden Sie hier eine Tabelle mit den Unterschieden zwischen diesen Tools. Da Keras und Tensorflow nun zusammenarbeiten, ist es sinnvoller, sie gemeinsam zu präsentieren.
Verwendung von PyTorch für Deep Learning
Wir haben über die Komplexität der Modelle und Netzwerke gesprochen, ohne die Ausführungsgeschwindigkeit der Algorithmen zu erwähnen. PyTorch ist so konzipiert, dass diese Zeit minimiert und die Besonderheiten der Hardware optimal genutzt werden.
PyTorch stellt die Daten in Form von multidimensionalen Tabellen dar, ähnlich den NumPy-Tabellen, die als „Tensoren“ bezeichnet werden. Die Tensoren speichern die Inputs des neuronalen Netzes, die Parameter der Hidden Layer und die Outputs. Ausgehend von diesen Tensoren kann PyTorch auf verborgene und effiziente Weise 4 Schritte zum Workout des Netzes durchführen:
- Es ist möglich, das neuronale Netz während des Lernens zu verändern (Anzahl der Knoten, Verbindungen zwischen ihnen usw.).
- Durchführung von Netzwerkvorhersagen („forward pass“)
- Berechnung des Verlustes oder Fehlers in Bezug auf die Vorhersagen
- Das Netzwerk in umgekehrter Richtung durchlaufen: „Backpropagation“ und Anpassung der Tensoren, so dass das Netzwerk auf der Grundlage des berechneten Verlusts/Fehlers genauere Vorhersagen macht.
Diese Funktion von PyTorch, genannt „Autograd„, ist stark optimiert und unterstützt die Verwendung von Grafikprozessoren und Datenparallelität, was die Berechnungen erheblich beschleunigt. Darüber hinaus ermöglicht dies die Nutzung in allen Clouds, während Tensorflow beispielsweise nur für GoogleCloud und dessen TPUs optimiert ist.
Vor kurzem hat Pytorch in Zusammenarbeit mit AWS (Amazon Web Services) zwei neue Funktionen vorgestellt. Die erste, TorchServe, ermöglicht die effiziente Verwaltung des Einsatzes von bereits trainierten neuronalen Netzen. Die zweite Funktion, TorchElastic, ermöglicht die Nutzung von Pytorch über Kubernetes Cluster. TorchPort kann dabei auf mehreren Servern laufen und ist gleichzeitig ausfallsicher.
Diese drei Frameworks haben daher ihre eigenen Besonderheiten. Insbesondere PyTorch ist sehr gut für komplexe und tiefe neuronale Netze geeignet. Um PyTorch besser zu verstehen, bietet die offizielle Website Tutorials an.
Um Ihre Praxis mit diesem Framework zu vertiefen, bietet Ihnen unsere Weiterbildung zum Data Scientist Unterrichtsmodule an, die dem Deep Learning mit PyTorch gewidmet sind.
Warum PyTorch?
PyTorch ist eine recht neue Bibliothek für maschinelles Lernen, aber sie verfügt über eine große Anzahl von Handbüchern und Tutorials, in denen Sie Beispiele finden können. Sie hat auch eine Community, die sich schnell entwickelt.
PyTorch verfügt über eine sehr einfache Schnittstelle für die Erstellung von neuronalen Netzen, obwohl es notwendig ist, direkt mit Tensoren zu arbeiten, ohne eine höhere Bibliothek wie Keras für Theano oder Tensorflow zu benötigen.
Im Gegensatz zu anderen Werkzeugen für maschinelles Lernen wie Tensorflow arbeitet PyTorch mit dynamischen statt statischen Graphen. Das bedeutet, dass die Funktionen zur Laufzeit geändert werden können und die Berechnung der Gradienten mit ihnen variiert. Bei Tensorflow hingegen müssen Sie zuerst den Berechnungsgraphen definieren und dann die Sitzung verwenden, um die Ergebnisse des Tensors zu berechnen, was die Fehlerbeseitigung im Code erschwert und die Implementierung zeitaufwendiger macht.
PyTorch ist kompatibel mit Grafikkarten (GPUs). Es verwendet intern CUDA, eine API, die die CPU mit dem Grafikprozessor verbindet und von NVIDIA entwickelt wurde.
💡Auch interessant:
| Deep Neural Network |
| Deep Learning vs. Machine Learning |
| Deep Learning – was ist das eigentlich ? |
| Deep Fake Gefahren |
| Python Deep Learning Basics |
| Style Transfer Deep Learning |
| Alphacode Deepminds |
Die Vorteile von PyTorch
Obwohl PyTorch viele Vorteile hat, werden wir uns hier auf einige wenige konzentrieren.
1.PyTorch und Python
Die meisten Arbeiten im Bereich des maschinellen Lernens und der künstlichen Intelligenz werden mit Python durchgeführt. PyTorch und Python gehören zur selben Familie, was bedeutet, dass Python-Entwickler sich bei der Arbeit mit PyTorch wohler fühlen sollten als bei der Arbeit mit anderen Deep Learning Frameworks.
- Leicht zu erlernen
Wie die Sprache Python wird auch Pytorch als relativ leicht zu erlernen angesehen. Der Hauptgrund dafür ist seine einfache und intuitive Syntax.
3.Starke Community
Obwohl PyTorch ein relativ neues Framework ist, hat es sehr schnell eine engagierte Gemeinschaft von Entwicklern aufgebaut. Darüber hinaus ist die Dokumentation von PyTorch sehr gut organisiert und für Anfänger hilfreich.
4.Einfache Fehlerbeseitigung
PyTorch ist tief in Python integriert, so dass viele Python-Debugging-Tools einfach mit PyTorch verwendet werden können.







