Python Deep Learning: Es ist sehr wahrscheinlich, dass du in deinem Alltag Anwendungen nutzt, die auf Deep-Learning-Modelle zurückgreifen. Übersetzungen, OCR, Gesichtserkennung... Verschiedene deiner Anwendungen beinhalten Deep Learning.
Diese Anwendung von Python Deep Learning wurde durch die Verfügbarkeit großer Datenmengen, die Algorithmen benötigen, um effizient zu sein, und durch die zunehmende Rechenleistung von Maschinen, die das Training dieser Algorithmen ermöglicht, möglich.
Deep-Learning-Modelle können in verschiedenen Sprachen erstellt und trainiert werden, aber in diesem Artikel verwenden wir Python und seine speziell für Deep Learning entwickelten Bibliotheken: Tensorflow und Keras.
Keras ist eine Open-Source-Bibliothek, die entwickelt wurde, um alle wichtigen Werkzeuge für das Experimentieren mit neuronalen Netzen bereitzustellen.
Es ist notwendig, die Bibliothek auf deiner Arbeitsumgebung zu installieren. Die Google Colab-Umgebung bietet den Großteil der Voraussetzungen für Deep Learning und Data Science.
Trainiere dein erstes neuronales Netz
Nachdem du dich mit den Tools vertraut gemacht hast, die du für Deep Learning verwenden kannst, ist es nun an der Zeit, selbst Hand anzulegen und dein erstes Deep-Learning-Modell zu bauen, zu trainieren und auszuwerten.
Aber dabei wirst du nicht allein sein. Wir haben für dich ein Tutorial entworfen, das die wichtigsten Schritte behandelt, die ein Data Scientist beim Trainieren eines neuronalen Netzes durchführt.
Wir werden diese Schritte erklären, damit du den Prozess für deine zukünftigen Modellierungen durchführen kannst.
Öffne zuerst dein Jupyter- oder Colab-Notebook, um den ersten Schritt in Angriff zu nehmen. Du kannst die Zellen einfach in dein Notebook kopieren, aber wir empfehlen dir dringend, selbst zu kodieren, um die Syntax besser zu verinnerlichen.
Denke daran, dass Übung den Meister macht.
Daten laden:
Es ist allgemein bekannt, dass man für ein Deep-Learning-Projekt (oder für Data Science im Allgemeinen) eine große Menge an Daten benötigt. Der erste Schritt ist daher natürlich die Auswahl und der Import unserer Daten.
Der Datensatz, den wir verwenden werden, ist unter Datenwissenschaftlern sehr bekannt, es handelt sich um den MNIST-Datensatz, der fast 60.000 28×28 Pixel große Bilder von handgeschriebenen Zahlen mit numerischen Zahlen als Zielvariable enthält. Das Ziel unseres Modells wird es sein, die geschriebene Zahl auf dem Bild zu erkennen.
Im Skript findest du den Import der Bibliotheken, die wir für unsere Modellierung benötigen. Du wirst auch feststellen, dass das Dataset im Keras-Modul enthalten ist und dass wir zwei verschiedene Datensätze haben, den Trainingsteil (train) und den Testteil (test).
Als Ergebnis der Ausführung dieser ersten Zelle erhältst du die Größe des Datasets sowie die Abmessungen der Bilder.
Hier werfen wir einen Blick auf eine zufällige Auswahl von Bildern mit ihren entsprechenden Labels.
Hier ist ein Beispiel für die Ausführung der obigen Zelle.
Vorverarbeitung von Daten
Nachdem du deine Daten hochgeladen hast, musst du sicherstellen, dass sie für die Trainingsphase bereit sind. Um dies zu erreichen, wendest du einige Transformationen auf deine Daten an.
Dazu gehören das Ändern der Größe, das Normalisieren und das Kodieren der Daten.
Aber keine Panik, auch hier werden wir dich durch den Prozess begleiten und jede Vorverarbeitung wird erklärt.
Größenänderung: Eine Besonderheit der Algorithmen des maschinellen Lernens und des Deep Learning ist, dass sie keine Matrizen als Eingabe nehmen. Dies führt dazu, dass du deine 28×28-Matrizen in Vektoren der Größe 784 umwandeln musst.
Normalisierung: Dieser Schritt ist für das Training deines Modells nicht zwingend erforderlich, kann aber seine Leistung steigern. Die Normalisierung wird angewendet, indem jedes Pixel durch 255 geteilt wird. Lies diesen Artikel, um mehr über Normalisierung zu erfahren.
Kodierung: Die Umwandlung von Labels in kategoriale Vektoren verbessert die Vorhersagegenauigkeit.
Definition des Modells :
Da deine Daten nun (wirklich) fertig sind, kannst du mit der Modellierung deines neuronalen Netzes fortfahren. Hier wirst du dein Modell Schicht für Schicht aufbauen.
Auch hier bist du bei der Umsetzung nicht allein. Wir werden dich bei der Modellierung des Netzes unten begleiten.

input und output: gleiche Farbe
mittlere Schichten: gleiche Farbe
Beispiel:
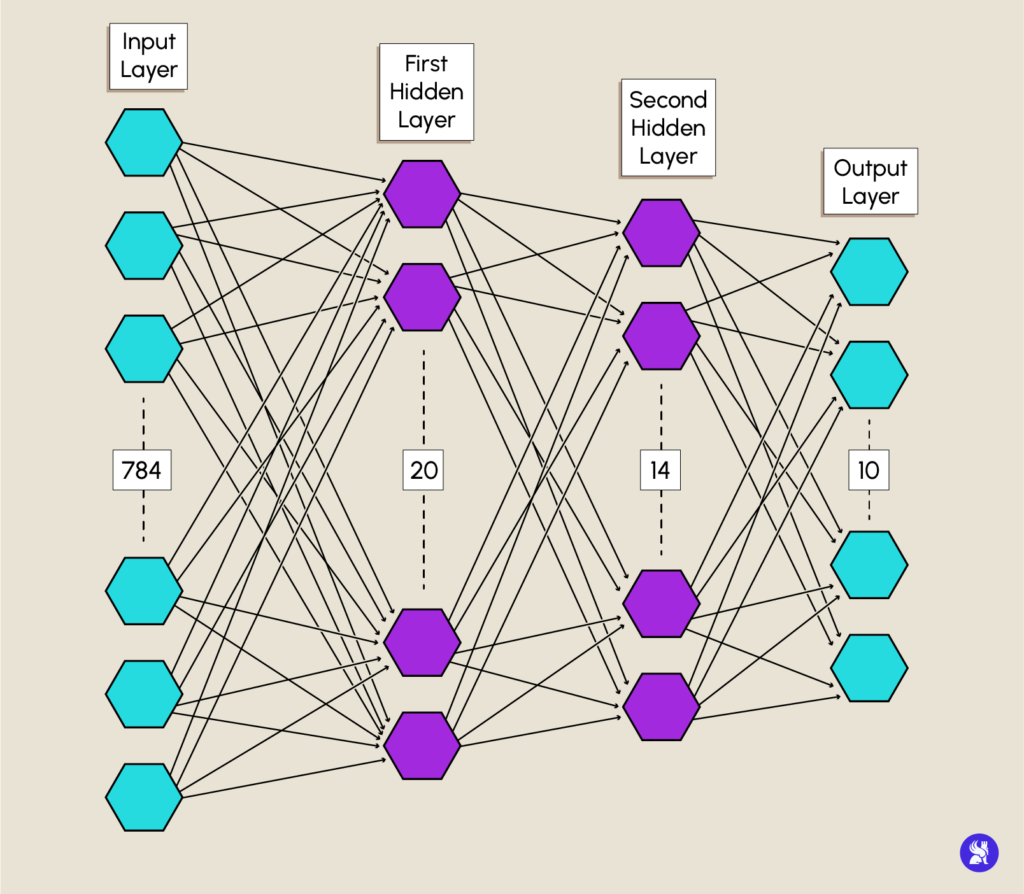
Das Modell besteht aus einer Eingabeschicht (Input layer) mit einer Anzahl von Neuronen, die der Anzahl von Merkmalen entspricht, die ein Datensatz haben kann, in unserem Fall ist das die Anzahl der Pixel eines Bildes.
Du definierst deine Eingabeschicht mithilfe des Input-Konstruktors von keras.layers und gibst die Größe unserer Daten an.
Hidden Layers werden mit dem Konstruktor Dense definiert, wobei das Argument units dazu dient, die Anzahl der Neuronen in einer Schicht anzugeben.
Für dein Modell initialisierst du die erste Schicht mit 20 Neuronen und die zweite Schicht mit 14 Neuronen. Die beiden verborgenen Schichten werden die Aktivierungsfunktion relu verwenden.
Die Ausgabeschicht (Output Layer) hat eine Neuronenanzahl, die der Anzahl der verschiedenen Klassen entspricht, hier die Anzahl der Ziffern, also 10. Du benutzt auch den Konstruktor Dense mit der Funktion softmax, die uns eine Verteilung zwischen 0 und 1 gibt, was die Wahrscheinlichkeit ist, dass unsere Daten den entsprechenden Klassen angehören.
Hier ist deine Vorlage, die nach der Ausführung des obigen Codes definiert wurde.
Modell kompilieren :
Wir wissen, dass du unbedingt mit dem Training des Modells fortfahren willst, aber es gibt noch einen letzten kleinen Schritt, der getan werden muss: das Kompilieren unseres Modells.
Die compile-Methode konfiguriert den Prozess des Modelltrainings, indem sie drei wichtige Parameter angibt.
- loss: Ein Parameter, der dem Modell mitteilt, auf welche Verlustfunktion sich die Fehlerberechnung und -optimierung stützt. Hier werden wir die „categorical_crossentropy“ verwenden.
- optimizer: Dieser Parameter legt den Optimierungsalgorithmus fest, den wir verwenden werden, um den Gradientenabstieg der Verlustfunktion durchzuführen. Wir wählen den „adam“-Optimierer, der in der Regel gute Ergebnisse bei einer großen Anzahl von Problemen liefert.
- metrics: Ein Parameter, der dazu dient, die Metriken für die Bewertung des Modells während des Trainingsprozesses auszuwählen. Die für dieses Modell festgelegte Metrik ist die Genauigkeit (accuracy), die am häufigsten für Klassifikationsprobleme verwendet wird.
Die Ausführung der nächsten Zelle kompiliert dein Modell und macht es schließlich bereit für das Training.
Modell trainieren :
Jetzt sind wir endlich in der Trainingsphase angelangt, in der die ganze Magie des Deep Learning zum Tragen kommt. Aber vorher müssen noch ein paar notwendige Begriffe erklärt werden.
Deep-Learning-Algorithmen sind bekannt dafür, dass sie sehr datenintensiv sind. Die Datenmengen, die zum Trainieren eines neuronalen Netzes verwendet werden, können Hunderte oder sogar Tausende von GB erreichen. Um es Maschinen mit begrenztem Arbeitsspeicher zu ermöglichen, Modelle zu trainieren, teilen wir unsere Datenmenge in kleinere Teile, sogenannte Batches, auf, um sie leichter in den RAM der Maschine laden zu können.
Wenn alle Stapel durchlaufen wurden, sagt man, dass eine Epoche abgeschlossen wurde. Das Lernen eines neuronalen Netzes erfordert mehrere Epochs.
Du wirst sehen, dass dieser Teil gar nicht so kompliziert ist, denn du brauchst nur eine einzige Zeile Code, um das Training zu starten. Allerdings haben wir dir versprochen, dir jedes Detail des Codes zu erklären, daher wirst du hier die fit-Methode auf deinem Modell ausführen, mit deinem Trainingsdatensatz (train dataset) als Argument und zusätzlichen Parametern:
- batch_size: die Anzahl der Datenproben, die ein Batch enthalten wird.
- epoch: die Anzahl der epochs, die benötigt werden, um das Modell zu trainieren.
- validation_split: der Prozentsatz der Daten, die für die Bewertung unseres Modells während des Trainings verwendet werden.
Die Trainingszeit für ein Modell kann von vielen Kriterien abhängen: Größe des Datensatzes, Komplexität der Modellarchitektur, Anzahl der Epochs und Rechenleistung.
Bewertung des Modells :
Herzlichen Glückwunsch! Du hast gerade dein erstes Deep-Learning-Modell trainiert. Jetzt musst du sicherstellen, dass es gut funktioniert, indem du seine Genauigkeit (accuracy) misst.
Wie bereits erwähnt, ist die Genauigkeit eine Metrik zur Bewertung von Klassifizierern, z. B. das Verhältnis von korrekt klassifizierten Punkten zur Gesamtzahl der Daten.
Wenn du diesen Code ausführst, wird dir die Genauigkeit des Trainings und der Validierung in Abhängigkeit von den Epochen angezeigt. Ein Beispiel für die erzielten Ergebnisse folgt gleich danach

Die training accuracy wird erreicht, indem man die Tests mit den Lerndaten durchführt, d. h. mit Daten, die das Modell schon vorher gesehen hat. Die Validierungsgenauigkeit hingegen wird mit neuen Daten erzielt, was den Unterschied im Diagramm erklärt.
Hier haben wir eine Validation accuracy von 95%, was ein sehr zufriedenstellendes Ergebnis ist.
NB: Du wirst nicht unbedingt die gleichen Ergebnisse wie die angezeigten haben, da sie von der Initialisierung der Gewichte des Modells abhängen, die zufällig erfolgt, aber der Unterschied wird nicht auffällig sein.
Werde Deep Learning-Profi!
Da du nun weißt, wie du dein eigenes neuronales Netz aufbauen, trainieren und testen kannst, kannst du in die Welt des Deep Learning eintauchen und viele neue Dinge ausprobieren. Bei diesem Modell kannst du versuchen, die Architektur, die Aktivierungsfunktionen oder die Trainingseinstellungen zu verändern. Hierzu kannst du einen Blick in die Dokumentation von Keras werfen.
Starte neue Projekte, die Daten aus neuen und unterschiedlichen Quellen verarbeiten. Beschränke dich nicht nur auf einen einzigen Datentyp, sondern greife z. B. strukturierte Daten und NLP an.
Halte dich auch auf unserem Blog auf dem Laufenden, der voller Wissen über Deep Learning steckt, wie dieser Artikel, der dein theoretisches Wissen über das Thema vertiefen wird.
Und wenn du deine Fähigkeiten im Bereich Deep Learning verbessern willst, dann schau dir die von DataScientest entwickelten Expertenkurse an.







