Heutzutage gibt es ein wachsendes Interesse und Fortschritte bei neuen Technologien im Bereich der künstlichen Intelligenz, insbesondere bei der Verwendung von neuronalen Netzen. Wir können die Leistungsfähigkeit dieser Netze bei der Klassifizierung von Bildern und Objekten feststellen. Auf den ersten Blick könnte man meinen, dass diese neuronalen Netze sehr leistungsstark und unfehlbar sind. In diesem Artikel geht es darum, die Herausforderungen und Auswirkungen zu verstehen, die adversarial examples mit sich bringen können.
Angesichts der raschen Entwicklung von Techniken der künstlichen Intelligenz (KI) und des Deep Learning (DL) ist es jedoch von entscheidender Bedeutung, die Sicherheit und Robustheit der eingesetzten Algorithmen zu gewährleisten. Es wäre legitim, Fragen zu stellen und sich für die möglichen Grenzen und die Leistung zu interessieren, die mit ihrer Verwendung verbunden sind.
Was ist ein "adversarial example"?
Ein „adversarial example“ oder Gegenbeispiel ist ein Beispiel für ein Objekt, das in der Lage ist, den Algorithmus eines neuronalen Netzes zu täuschen und zu überlisten, indem es ihn glauben lässt, dass es als solches Objekt klassifiziert werden sollte, obwohl dies nicht der Fall ist.
Ein „avdersarial example“ ist ein korrekt initialisierter Datensatz, dem eine für das neuronale Netz nicht wahrnehmbare Störung hinzugefügt wurde, um eine falsche Klassifizierung zu bewirken.
Adversial Examples: Was sind die Risiken ?
Wenn Du einen Menschen bittest zu beschreiben, wie er einen Panda in einem Bild entdeckt, kann er nach körperlichen Merkmalen wie runden Ohren, schwarzen Flecken um die Augen, Schnauze und behaarter Haut suchen.
Er kann auch andere Informationen liefern, z. B. die Art des Lebensraums, in dem er erwartet, den Panda zu sehen, und die Art der Posen, die er einnimmt.
Für ein künstliches neuronales Netz gilt: Solange die Anwendung der Pixelwerte auf die Gleichung die richtige Antwort ergibt, ist es davon überzeugt, dass es sich bei dem, was es sieht, um einen Panda handelt.
Mit anderen Worten: Indem du die Pixelwerte des Bildes in der richtigen Weise veränderst, kannst du die KI täuschen, indem du sie glauben lässt, dass sie keinen Panda sieht.
Im Fall des adversarial example, den wir uns im weiteren Verlauf des Artikels ansehen werden, haben die KI-Forscher dem Bild eine Rauschschicht hinzugefügt. Dieses Rauschen ist für das menschliche Auge kaum wahrnehmbar. Aber wenn die neuen Pixelnummern das neuronale Netz durchlaufen, erzeugen sie das Ergebnis eines Gibbons, obwohl es sich um einen Panda handelt.
Widersprüchliche Beispiele machen maschinelle Lernmodelle anfällig für Angriffe, wie in den folgenden Szenarien:
Ein selbstfahrendes Auto rammt ein anderes Auto, weil es ein Stoppschild ignoriert.
Jemand hatte ein Bild auf dem Schild platziert, das für Menschen wie ein Stoppschild aussieht, für die Schildererkennungssoftware des Autos aber wie ein Parkverbotsschild gestaltet wurde.
Einem Spam-Detektor gelingt es nicht, eine E-Mail als Spam zu klassifizieren.
Die Spam-Mail wurde so gestaltet, dass sie wie eine normale E-Mail aussieht, aber mit der Absicht, den Empfänger zu täuschen.
Ein mit maschinellem Lernen betriebener Scanner scannt Koffer am Flughafen nach Waffen. Ein Messer wurde entwickelt, um die Erkennung zu umgehen, indem das System glaubt, es handele sich um einen Regenschirm.
Eine automatisierte KI, die eine Krankheit nicht erkennt (z. B. eine Röntgenaufnahme), obwohl es sich in Wirklichkeit um eine schwere Krankheit handelt.
Betrachten wir nun einige konkrete Beispiele, die neuronale Netze täuschen konnten.
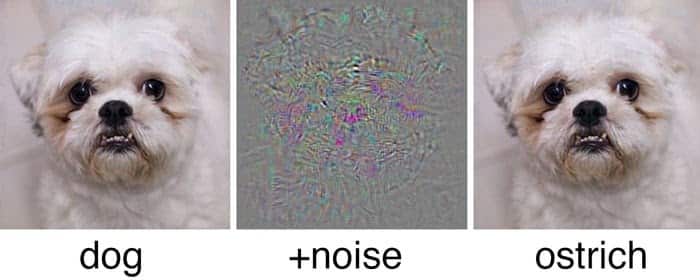
Im folgenden Beispiel sehen wir, dass es mit einer kleinen, für das bloße Auge unsichtbaren Störung möglich war, das neuronale Netz zu täuschen und das Foto eines Hundes als Strauß zu klassifizieren.
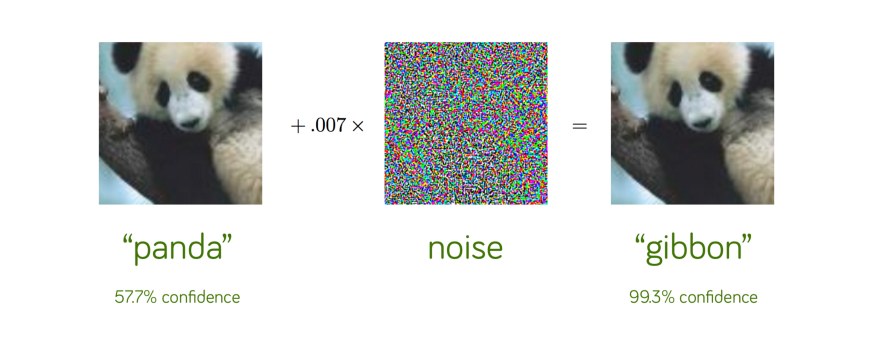
Nehmen wir ein weiteres Beispiel für die Klassifizierung von Bildern über Pandas, die ein neuronales Netz mit einem Konfidenzniveau von 57,7 % korrekt als Panda erkennt.
Wenn man ein wenig sorgfältig konstruierte Störung hinzufügt, klassifiziert dasselbe neuronale Netz das Bild nun als Gibbon mit einem Vertrauen von 99,3 %!
Hierbei handelt es sich eindeutig um eine optische Täuschung, allerdings nur für das neuronale Netz.
Wir können eindeutig sagen, dass die beiden Bilder tatsächlich Pandas entsprechen. Tatsächlich können wir nicht einmal wahrnehmen, dass dem linken Originalbild ein wenig Störung hinzugefügt wurde, um das Adversarial Example auf der rechten Seite zu konstruieren!
Im folgenden Beispiel wird gezeigt, wie sich das im Alltag auf selbstfahrende Autos auswirken kann, die ein Verkehrsschild falsch erkennen.

Im obigen Fall wurde die für das menschliche Auge wahrnehmbare Störung vom neuronalen Netz nicht erkannt. Das oben abgebildete rechte Stoppschild wurde als Geschwindigkeitsbegrenzung auf 45 km/h klassifiziert. Wir können also immer noch die Herausforderungen und Grenzen erkennen, die neuronale Netze bei der Bildklassifizierung haben können
Wie werden "adversarial examples" erstellt?
Zunächst einmal ist es notwendig, zwischen gezielten und ungezielten Angriffen zu unterscheiden.
Ein ungezielter Angriff ist einfach ein Angriff, der darauf abzielt, eine falsche Klassifizierung zu bewirken, unabhängig davon, wie diese Klassifizierung ausfällt. Wichtig ist nur, dass das neuronale Netz das Objekt falsch klassifiziert.
Ein gezielter Angriff ist dagegen ein Angriff, der darauf abzielt, eine falsche Klassifizierung in einer bestimmten Kategorie zu induzieren.
Ein nicht gezielter Angriff auf ein Bild eines Hundes wäre zum Beispiel, wenn unser neuronales Netz eine andere Klassifizierung als die eines Hundes vornehmen würde. Ein gezielter Angriff auf ein Bild eines Hundes hingegen würde unser neuronales Netz dazu veranlassen, den Hund beispielsweise als Strauß, aber nicht als Katze zu klassifizieren.
Es gibt verschiedene Methoden, um Adversarial Examples zu konstruieren. Dazu gehören Datenvergiftung, GANs (generative antagonistische Netze) und die Manipulation von Robotern.
Adversarial Examples: Wie kann man sich schützen ?
Es gibt viele Möglichkeiten, sich zu verteidigen, z. B. durch Adversarial Training (oder kontradiktorisches Training).
Dies ist die einfachste und natürlichste Art der Verteidigung.
Diese Verteidigung besteht darin, dass wir uns als Angreifer ausgeben, indem wir eine Anzahl von Adversarial-Examples gegen unser neuronales Netz erzeugen und dann unser neuronales Netz mit den erzeugten Daten trainieren.
Diese Methode hilft bei der Verallgemeinerung unseres Modells, ist aber noch nicht in der Lage, ein entsprechend hohes Maß an Robustheit zu erreichen. Angreifer könnten nämlich immer noch eine kleinere Störung finden, um das neuronale Netz zu täuschen. Es würde also auf ein Spiel hinauslaufen, bei dem Angreifer und Verteidiger versuchen, sich gegenseitig zu übertrumpfen.
Es gibt auch eine andere Art der Verteidigung, die als defensive Destillation bezeichnet wird. Bei dieser Verteidigung wird ein zweites Modell erstellt, dessen Oberfläche in den Richtungen geglättet wird, die der Angreifer angreifen möchte (d. h. das Modell fungiert als zusätzlicher Filter, um Anomalien zu erkennen), wodurch es für den Angreifer schwierig wird, Änderungen an den gegnerischen Eingaben zu erkennen, die zu einer falschen Klassifizierung führen würden. Das zweite Modell wäre eine Art Angriffssperre und in der Lage, Änderungen zu erkennen, die mit gegnerischen Angriffen zusammenhängen.
Dies ist jedoch ein noch junges Forschungsgebiet. Es ist uns noch nicht vollständig gelungen, eine zuverlässige und optimale Lösung zu finden. Oft werden neue Angriffe entwickelt, um die neuen Abwehrmechanismen zu umgehen, was diese kontinuierliche Forschungsarbeit erklärt.
Fazit
Die Adversarial Examples zeigen, dass viele moderne Algorithmen des maschinellen Lernens auf überraschende Weise gebrochen werden können. Diese Fehlschläge des maschinellen Lernens zeigen, dass selbst einfache Algorithmen sich ganz anders verhalten können, als von ihren Entwicklern erwartet. Data Scientists werden daher benötigt,um Methoden zu entwerfen, um widersprüchliche Beispiele zu verhindern, um die Lücke zwischen den Absichten der Designer und dem Verhalten der Algorithmen zu schließen.
Hast du Lust, die in diesem Artikel erwähnten Deep-Learning-Techniken zu beherrschen? Dann informiere dich über unsere Ausbildung zum Data Scientist.







