Conditional GAN oder cGAN ist ein Modell, das im Deep Learning, einem Ableger des maschinellen Lernens, verwendet wird. Es ermöglicht eine genauere Generierung und Unterscheidung von Bildern, um Maschinen zu trainieren und ihnen zu ermöglichen, selbstständig zu lernen. Die Idee von cGAN wurde erstmals 2014 von Mehdi Mirza und Simon Osindero veröffentlicht.
Um zu verstehen, was ein cGan ist, muss man sich zunächst mit Deep Learning vertraut machen.
Bei diesem Verfahren wird ein Computerprogramm mit Tausenden von Daten gefüttert, damit es lernen kann, diese zu erkennen.
Ein erster Trainingsansatz ist das Generative Adversarial Network (GAN), das generative antagonistische Netzwerk.
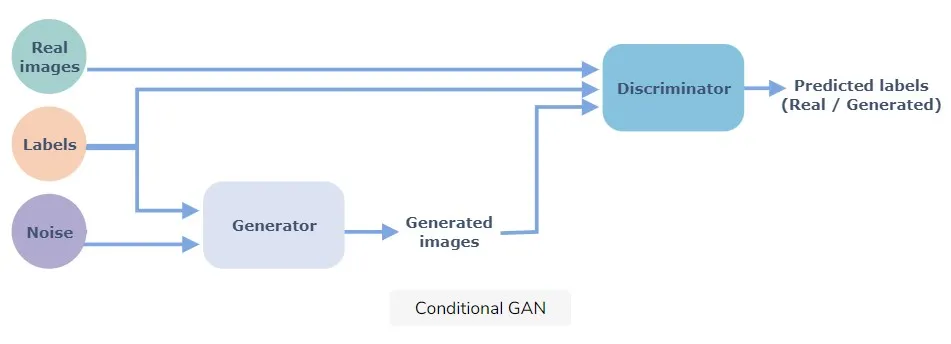
Ein GAN ermöglicht einen Dialog zwischen zwei Netzwerken, dem Generator und dem Diskriminator.
Auf der einen Seite erzeugt der Generator falsche Bilder, die so realistisch wie möglich sein sollen, um das gegnerische Netzwerk, den Diskriminator, zu täuschen.
Auf der anderen Seite beobachtet der Diskriminator Bilder, die sowohl vom Generator als auch von einer Datenbank stammen.
Er muss entscheiden, welche Bilder aus der Datenbank stammen (und sie als wahr kennzeichnen) und welche Bilder vom Generator erzeugt wurden (und somit falsch sind).
Wenn der Diskriminator die falschen Bilder richtig als falsch und die richtigen als richtig einstuft, wird er mit positivem Feedback belohnt, wenn er bei seiner Arbeit versagt, erhält er negatives Feedback.
Nach und nach wird er mithilfe des Descending-Gradient-Algorithmus den Datenumfang bestimmen, der es ihm ermöglicht, ein wahres Bild zu erkennen, aus seinen Fehlern zu lernen und sich zu verbessern.
So wird er sich nach und nach verbessern und immer relevantere Objekte erstellen
cGAN oder wie man die Leistung des Generators und des Diskriminators maximiert
Mit einem Conditional Gan ist es möglich, genauere Informationen, sogenannte Class Labels, an den Generator und den Diskriminator zu senden, um ihre Datenproduktion zu steuern. Diese Informationen präzisieren die Daten, die der Generator und der Diskriminator produzieren, damit sie schneller zum gewünschten Ergebnis kommen.
Die Labels lenken die Produktion des Generators, damit er präzisere Daten erzeugen kann. Anstatt z. B. Bilder von Kleidungsstücken zu produzieren, wird er Bilder von Hosen, Jacken oder Socken produzieren, je nachdem, welches Label ihm zur Verfügung gestellt wird.
Auf der Seite des Diskriminators werden die Labels es dem Netzwerk ermöglichen, besser zwischen echten Bildern und falschen Bildern, die der Generator liefert, zu unterscheiden. Dadurch wird das System effizienter.

cGAN und seine vielfältigen Einsatzmöglichkeiten im Bereich des maschinellen Lernens
Wenn du dir die Verwendung des Conditional GAN nicht vorstellen kannst, sind hier einige Beispiele, die dir helfen können. Das Conditional Generative Adversarial Network kann in folgenden Fällen sehr nützlich sein:
1. Die Übersetzung von Bild zu Bild
cGANs ermöglichen es, Bilder durch die Berücksichtigung zusätzlicher Informationen, sogenannter Labels, weiterzuentwickeln. cGan hat die Entwicklung der Pix2Pix-Methode ermöglicht, deren Anwendungen die Rekonstruktion von Objekten anhand von Kanten, die Synthese von Fotos aus Labelkarten und das Einfärben von Bildern ermöglichen.
2. Bilder aus Text erstellen
Mithilfe von cGAN ist es möglich, qualitativ hochwertige Fotos auf der Grundlage eines Textes zu erstellen. Die Verwendung eines Textes und der Reichtum seines Vokabulars ermöglicht es, viel genauere computergenerierte Bilder zu erstellen.
3. Die Erzeugung von Videos
Bei Videos kann der cGan auch zukünftige Bilder eines Videos auf der Grundlage einer Auswahl vorheriger Bilder vorhersagen.
4. Gesichter generieren
cGANs kann verwendet werden, um Bilder von Gesichtern mit bestimmten Attributen zu erzeugen, z. B. Haar- oder Augenfarbe.
cGAN stellt daher einen ganz besonderen Fortschritt dar, wenn man es mit GAN vergleicht. Er ermöglicht es Deep-Learning-Systemen, an Genauigkeit und Effizienz zu gewinnen. Eine kleine Revolution im Bereich des maschinellen Lernens, die die Karriere der beiden Erfinder Mehdi Mirza und Simon Osindero vorangetrieben hat. Sie arbeiten jetzt bei DeepMind, einem führenden Unternehmen in diesem Bereich.







