Le cloud computing a bouleversé les méthodes de déploiement et d’exploitation des infrastructures informatiques, donnant naissance à des outils innovants destinés à simplifier, automatiser et optimiser ces processus. Ainsi, Kubernetes émerge comme un acteur clé, révolutionnant la gestion des conteneurs d’applications et jouant un rôle central dans l’écosystème du développement logiciel moderne.
Conçu à l’origine par Google et désormais géré par la Cloud Native Computing Foundation, Kubernetes est devenu le système d’orchestration de conteneurs de facto, permettant aux équipes de développement de déployer, de mettre à l’échelle et de gérer automatiquement leurs applications conteneurisées avec une efficacité et une flexibilité sans précédent.
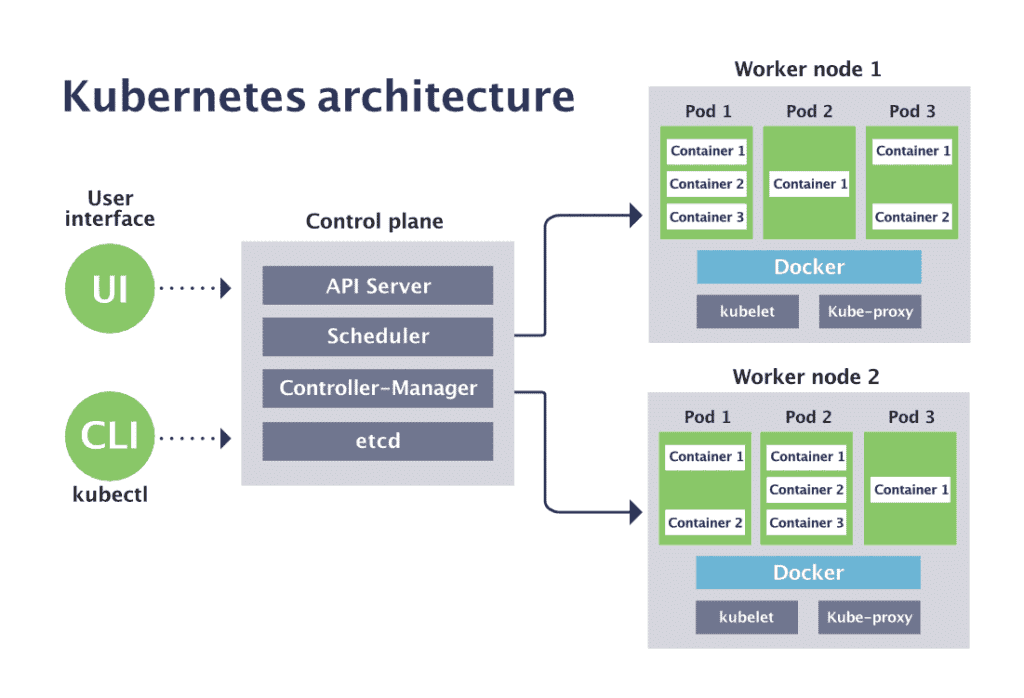
Architecture de Kubernetes
L’architecture de Kubernetes est conçue pour être hautement disponible et scalable, permettant la gestion efficace des applications conteneurisées dans un environnement distribué. Au cœur de cette architecture se trouvent plusieurs composants essentiels travaillant de concert pour orchestrer et gérer les conteneurs sur un cluster de machines.
Le nœud maître agit comme le cerveau du cluster Kubernetes, prenant des décisions critiques et orchestrant la communication entre les différents composants. Il se compose de plusieurs éléments clés :
API Server (kube-apiserver) : Le point d’entrée de l’API Kubernetes, servant de front-end pour le cluster. Il permet aux utilisateurs, et aux différents composants de communiquer et de gérer l’état du cluster.
Scheduler (kube-scheduler) : Responsable de l’assignation des pods aux nœuds, en prenant en compte les ressources disponibles, les contraintes, et les préférences.
Controller Manager (kube-controller-manager) : Gère un ensemble de contrôleurs qui régulent l’état du cluster, en s’assurant que l’état actuel du système correspond à l’état désiré. Cela inclut le contrôleur de nœud, le contrôleur de réplication, et d’autres.
etcd : Un magasin de clé-valeur léger et distribué qui stocke toutes les données de configuration et d’état du cluster, servant de source de vérité pour le cluster.
Composants des nœuds de travail (Worker Nodes)
Les nœuds de travail exécutent les applications conteneurisées et sont les composants qui font réellement le « travail » dans un cluster Kubernetes. Ils comprennent :
Kubelet : Un agent qui s’exécute sur chaque nœud de travail, s’assurant que les conteneurs sont en cours d’exécution dans un pod.
Kube-proxy : Gère le réseau sur les nœuds, permettant la communication réseau entre les conteneurs à travers les nœuds du cluster.
Container Runtime : Le moteur d’exécution de conteneurs (comme Docker, containerd, CRI-O) qui s’occupe de l’exécution des conteneurs.
Ressources de gestion
Kubernetes introduit plusieurs abstractions qui facilitent le déploiement et la gestion des applications, telles que :
Pods : La plus petite unité déployable qui peut être créée et gérée dans Kubernetes. Un pod encapsule un ou plusieurs conteneurs qui partagent le stockage, le réseau, et d’autres ressources.
Services : Une abstraction qui définit un ensemble logique de pods et une politique d’accès à eux, souvent via un réseau.
Volumes : Offrent un système de stockage persistant pour les données, permettant aux données de survivre au redémarrage des conteneurs.
Namespaces : Ils permettent de segmenter les ressources du cluster entre plusieurs utilisateurs et projets.
Kubernetes est une plateforme puissante qui offre un large éventail de fonctionnalités pour simplifier le déploiement, la gestion et l’automatisation des applications conteneurisées.
Orchestration des conteneurs
Déploiement et mise à jour automatiques : Déploiement automatique et mise à jour des conteneurs. Gestion des versions d’applications facilitées et rollback possible en cas de besoin.
Gestion de la configuration et des secrets : Permet de mettre à jour et de maintenir des informations sensibles sans reconstruire les images de conteneurs.
Mise à l’échelle
Montée en charge automatique (Auto-scaling) : Ajustement automatique du nombre de conteneurs en fonction de la charge de travail.
Équilibrage de charge : Distribue automatiquement les requêtes entrantes entre les conteneurs pour équilibrer la charge et garantir la haute disponibilité.
Gestion des ressources
Gestion des volumes persistants : Offre un système de stockage qui permet aux données de survivre au redémarrage des conteneurs.
Allocation des ressources : Permet d’allouer des ressources CPU et mémoire spécifiques pour chaque conteneur.
Haute disponibilité
Tolérance aux pannes : Kubernetes redémarre automatiquement les conteneurs qui échouent, remplace et reprogramme les conteneurs sur d’autres nœuds si un nœud échoue.
Service Discovery et Load Balancing : Les conteneurs reçoivent des adresses IP uniques et un seul nom DNS pour un ensemble de conteneurs.
Sécurité et isolation
Gestion des identités : Supporte la gestion des identités, l’authentification et l’autorisation.
Isolation des ressources : Isolation des applications et des ressources assurées, minimisant les risques de conflits et d’interférences entre les applications.
Automatisation et auto-réparation
Self-healing : Surveillance de l’état des conteneurs et des nœuds, et prise de mesures correctives automatiques pour garantir que l’état désiré de l’application est maintenu.
Automatisation des déploiements : Déploiements sans temps d’arrêt (zero-downtime deployments) et garantit que les mises à jour des applications sont effectuées de manière sûre et contrôlée.
L’adoption de Kubernetes peut sembler intimidante au début, mais avec les bonnes ressources et une approche étape par étape, vous pouvez rapidement devenir compétent dans la gestion de conteneurs avec Kubernetes.
Familiarisez vous avec les concepts de base
Avant de plonger dans la pratique, il est crucial de comprendre les concepts fondamentaux de Kubernetes, tels que les pods, les services, les déploiements, et les volumes. La documentation officielle de Kubernetes est une excellente source pour cela.
Installer et configurer Kubernetes
Vous aurez besoin d’installer Kubernetes. Minikube est un outil parfait pour cela, car il permet de créer un cluster Kubernetes local sur votre machine, idéal pour l’expérimentation et l’apprentissage.
Pratiquer avec des tutoriels interactifs
Kubernetes.io propose des tutoriels interactifs qui vous guideront à travers les tâches de base. Ces exercices pratiques sont importants pour comprendre comment Kubernetes fonctionne dans des scénarios réels.
Utiliser des outils d'interface graphique
Bien que Kubernetes soit souvent géré en ligne de commande, des outils d’interface graphique comme Kubernetes Dashboard peuvent simplifier la visualisation et la gestion des composants de votre cluster.
Construire et déployer une application simple
Le meilleur moyen d’apprendre est par la pratique. Essayez de construire une application simple et de la déployer sur votre cluster Kubernetes. Ce processus vous aidera à comprendre le cycle de vie du développement et du déploiement d’applications dans un environnement Kubernetes.
Explorer des ressources avancées
Une fois que vous avez maîtrisé les bases, élargissez vos connaissances en explorant des sujets plus avancés comme l’auto-scaling, la gestion des secrets, ou la configuration des probes de liveness et readiness.
Kubernetes s’est imposé comme un acteur incontournable dans l’écosystème du développement logiciel, révolutionnant la manière dont les applications conteneurisées sont déployées, gérées et mises à l’échelle. En offrant une plateforme robuste, flexible et hautement scalable, Kubernetes facilite la gestion des charges de travail complexes et diversifiées, tout en améliorant l’efficacité et la fiabilité des opérations informatiques.
Facebook
Twitter
LinkedIn
DataScientest News
Inscrivez-vous à notre Newsletter pour recevoir nos guides, tutoriels, et les dernières actualités data directement dans votre boîte mail.