Für die effektive Verarbeitung sequenzieller Daten im Deep Learning und Machine Learning ist es entscheidend, die Gated Recurrent Units (GRUs) zu verstehen. Diese neuronalen Netze können sich über längere Zeiträume an wichtige Informationen erinnern und diese nutzen.
Daten mit zeitlichem Bezug sind allgegenwärtig: Texte, Musik, Börsenwerte, Sensordaten … Der Sinn jedes einzelnen Elements hängt von den vorhergehenden Daten ab:
Ein Wort erhält seine vollständige Bedeutung nur im Kontext der vorherigen Wörter im Satz.
Die Vorhersage der Temperatur für morgen basiert auf den Werten von heute und den Vortagen.
Die Erkennung eines Musters in einem Audiosignal erfordert die Analyse einer gesamten Tonsequenz.
Klassische neuronale Netze sind für solche Sequenzen ungeeignet, da ihnen eine Gedächtnisfunktion fehlt.
Der erste Ansatz für die Verarbeitung dieser Daten waren Recurrent Neural Networks (RNNs). Diese haben jedoch Schwierigkeiten, entfernte Informationen zu speichern, bedingt durch das Problem des vanishing gradient: Die Gradienten werden bei jeder Schicht kleiner, bis sie so gering sind, dass sie die Gewichte in weit zurückliegenden Schichten nicht mehr effektiv anpassen können. Dadurch geht die Information über den Anfang einer Sequenz verloren, wenn man deren Ende erreicht.
Um diese Einschränkung zu überwinden und Deep-Learning-Netzwerken die Verarbeitung langer Sequenzen zu ermöglichen, wurden komplexere Architekturen der RNNs entwickelt.
Zu den effektivsten und beliebtesten zählen die Gated Recurrent Units (GRUs).
Sie stellen eine Weiterentwicklung der einfachen RNNs dar, die gezielt entwickelt wurde, um das Gedächtnis und die Informationsweitergabe über lange Zeiträume deutlich besser zu verwalten.
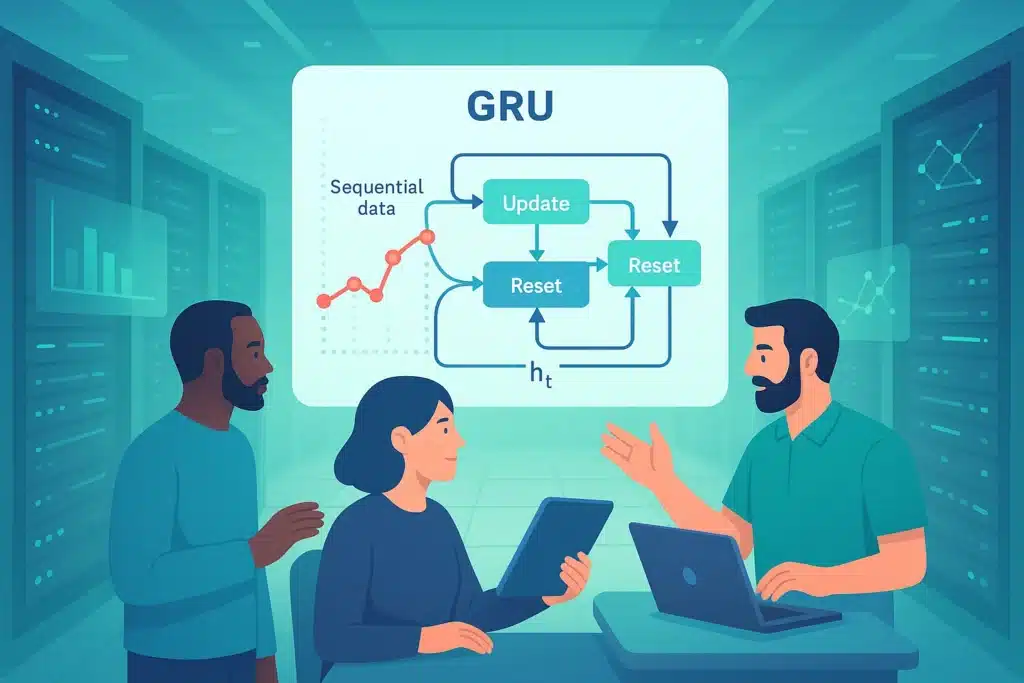
Der Schlüsselmechanismus: Die Tore (Gating Mechanism)
Die größte Innovation der GRUs – und auch anderer RNN-Varianten wie LSTMs – liegt im Einsatz von sogenannten „Gates“ (Gating Mechanisms). Anstatt, wie ein einfaches RNN, lediglich den aktuellen Eingang und den vorherigen versteckten Zustand (hidden state hₜ₋₁) roh zu kombinieren, steuern GRUs mithilfe dieser Tore selektiv und dynamisch den Informationsfluss innerhalb der rekurrenten Einheit.
Diese Tore funktionieren wie Filter: Sie basieren auf Aktivierungsfunktionen (z. B. der Sigmoid-Funktion) und entscheiden, welche Informationen aus dem alten Speicher und aus den neuen Eingabedaten besonders wichtig sind.
Ein GRU verwendet zwei zentrale Tore:
Reset-Gate (Reset-Tor): Es entscheidet, welcher Teil des vorherigen versteckten Zustands beim Berechnen des neuen Zustands ignoriert oder vergessen wird.
Update-Gate (Update-Tor): Es steuert, wie viel des vorherigen versteckten Zustands erhalten bleibt und welcher Anteil des neuen Kandidatenzustands – der die potenziell zu integrierende Information repräsentiert – hinzugefügt wird, um den neuen versteckten Zustand zu formen.
Dank dieser Mechanismen können GRUs gezielt Informationen über lange Zeiträume hinweg behalten oder vergessen.
GRUs vs. LSTM
Long Short Term Memory (LSTMs) ähneln den GRUs, da auch sie Tore nutzen, um ihr Langzeitgedächtnis zu steuern und das Problem des vanishing gradient zu verringern.
Der Unterschied: LSTMs verwenden drei Tore, während GRUs nur zwei benötigen. Das macht LSTMs komplexer und langsamer im Training.

Die Vorteile der GRUs
Der größte Vorteil der GRUs gegenüber klassischen RNNs ist ihre Fähigkeit, Abhängigkeiten in Datenserien auch über größere Distanzen hinweg zu erkennen. Dank der Tore können GRUs selektiv entscheiden, welche Informationen über sehr lange Sequenzen beibehalten und welche ignoriert werden sollen.
Beispielsweise kann ein GRU in einem langen Satz lernen, sich das Hauptthema und das Verb zu merken, auch wenn sie durch viele Wörter getrennt sind. So stellt es am Ende die grammatikalische und semantische Kohärenz sicher. Diese Fähigkeit macht GRUs besonders stark im Verstehen von Kontext in langen Datenreihen.
Die Tore ermöglichen es den Gradienten, direkter über die Zeit zu fließen, was verhindert, dass sie zu klein werden (vanishing gradient). Das stabilisiert das Training und erlaubt es dem Netzwerk, effektiv die Gewichte zu lernen, die für langfristige Abhängigkeiten entscheidend sind.
Während LSTMs dieselben Prinzipien nutzen, haben GRUs eine einfachere Architektur mit weniger Parametern. Das macht sie computational effizienter: Sie sind in der Regel schneller zu trainieren und auszuführen, erreichen jedoch Spitzenleistungen in vielen sequenziellen Aufgaben – und übertreffen LSTMs in manchen Fällen sogar.
Dieser Vorteil ist besonders relevant für Echtzeitanwendungen oder wenn die Rechenressourcen begrenzt sind.

Welche Anwendungen haben GRUs?
Die Vorteile der GRUs eröffnen zahlreiche konkrete Einsatzmöglichkeiten in verschiedenen Bereichen:
Natural Language Processing (NLP): GRUs werden häufig für Aufgaben wie maschinelle Übersetzung, Textgenerierung, Sentiment-Analyse, Spracherkennung und andere Anwendungen eingesetzt, bei denen das Verständnis des sequentiellen Kontexts entscheidend ist.
Zeitreihenanalyse: Sie eignen sich hervorragend, um zukünftige Werte auf Basis historischer Daten vorherzusagen – etwa bei finanziellen Prognosen, Wettervorhersagen oder Energieverbrauchsanalysen.
Sequenzmodellierung: Darüber hinaus werden GRUs regelmäßig für die Erstellung von Musik, die Analyse von Genomen und andere Aufgaben verwendet, die auf geordneten Sequenzen basieren.
Fazit
Die Gated Recurrent Units (GRUs) stellen einen bedeutenden Fortschritt gegenüber den einfachen Recurrent Neural Networks (RNNs) dar.
Dank ihrer intelligenten Tormechanismen verwalten sie das Langzeitgedächtnis effizient und überwinden typische Trainingsprobleme wie den vanishing gradient.
Ihre Effizienz, Robustheit und starke Leistung machen GRUs zu einer der beliebtesten Architekturen im Deep Learning und Machine Learning – und zu einer bevorzugten Wahl für eine Vielzahl moderner Anwendungen.








