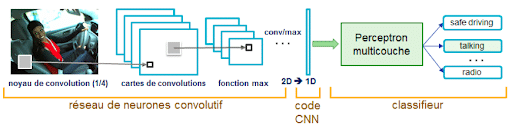
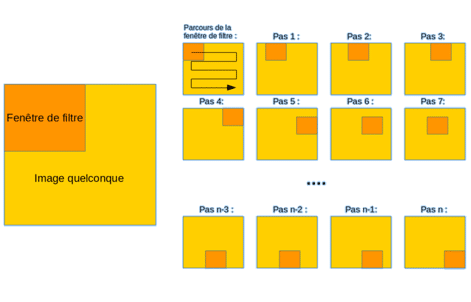
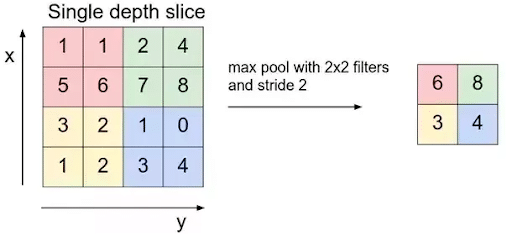
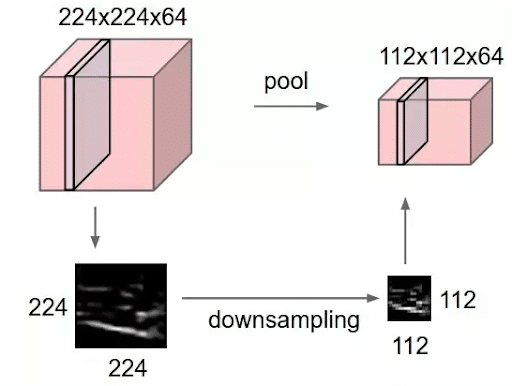
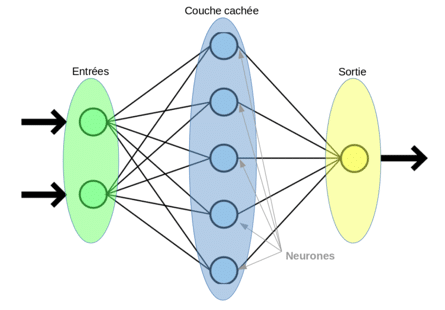
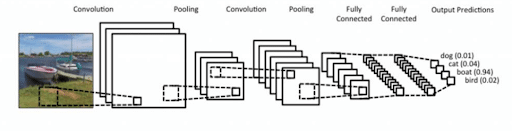
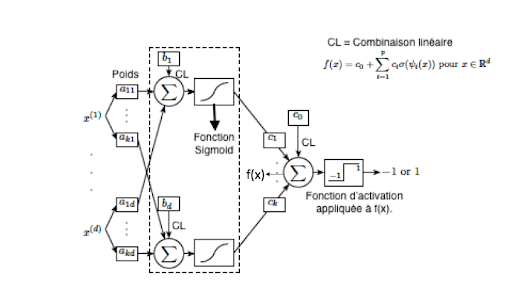
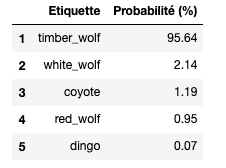
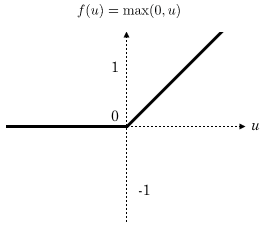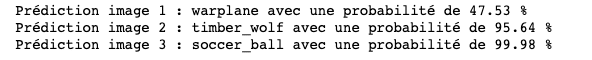Ein Convolutional Neural Network (CNN) gehört zur Familie der künstlichen neuronalen Netzwerke und wird in der Regel dem Bereich des Deep Learning zugeordnet.
Machine Learning ist ein Oberbegriff, der sich mit Algorithmen und Techniken befasst, die es Computern ermöglichen, aus Daten zu lernen und Vorhersagen oder Entscheidungen zu treffen, ohne explizit programmiert zu werden. Es gibt verschiedene Ansätze im Machine Learning, darunter überwachtes Lernen, unüberwachtes Lernen und verstärkendes Lernen.
Deep Learning ist eine spezifische Methode des Machine Learnings, die auf künstlichen neuronalen Netzwerken mit vielen Schichten (daher der Begriff „tief“) basiert.
Diese Netzwerke können komplexe Muster und Zusammenhänge in Daten erkennen und lernen, indem sie hierarchische Darstellungen der Daten erzeugen.
Convolutional Neural Networks sind eine spezielle Art von künstlichen neuronalen Netzwerken, die besonders gut für die Verarbeitung von Daten mit räumlicher Struktur geeignet sind, wie zum Beispiel Bilder. CNNs verwenden Convolutional Layers, Pooling Layers und Fully Connected Layers, um Merkmale in den Daten zu extrahieren und Klassifizierungen oder Vorhersagen zu treffen.
Insgesamt kann man sagen, dass Convolutional Neural Networks eine Technik des Deep Learning sind, das wiederum ein Teilbereich des Machine Learnings ist.