Die Definition des richtigen Modells ist entscheidend, um mit Machine Learning aussagekräftige Vorhersagen zu treffen. Aber eine schlechte Anpassung der Lerndaten kann die Leistung der Vorhersageanalyse beeinträchtigen. Genau das passiert beim Underfitting. Worum handelt es sich also? Und wie kann man es vermeiden? Die Antworten findest du hier.
Was ist Underfitting ?
Underfitting ist ein unumgängliches Konzept des Machine Learning, da es für eine schlechte Leistung des überwachten Lernens aus Daten verantwortlich sein kann. Bevor wir uns also näher mit diesem Begriff beschäftigen, sollten wir uns einige wesentliche Elemente der Funktionsweise von Machine Learning vergegenwärtigen.
Erinnerung an die Funktionsweise von Machine Learning
Erinnerung an die FunktionMachine Learning hat das Ziel, ein Muster anhand von Lernmodellen auf noch unbekannten Daten vorherzusagen.
Um dies zu erreichen, basiert das überwachte Lernen auf zwei Kernideen. Nämlich:
Approximation: Es geht darum, Lerndaten (oder Trainingssets) zu trainieren, um ein Modell mit einer möglichst geringen Fehlerquote zu erhalten.
Verallgemeinerung: Nach diesem Training verwenden die Data Scientists Validierungsdaten, um die verschiedenen Modelle zu testen. Dadurch wird ein Modell entworfen, das sich auf neue, noch nie zuvor gesehene Daten verallgemeinern lässt.
Die Gesamtidee ist es, ähnliche Fehlerquoten beim Lernen und bei der Validierung zu erreichen.ie Funktionsweise von Machine Learning

Underfitting oder Unterlernen
Underfitting kann mit Unteranpassung oder Unterlernen übersetzt werden. In diesem Fall wird auch gesagt, dass das Modell unter einem großen Bias (oder einer Verzerrung) leidet.
Dies geschieht, wenn man nur relevante Variablen benennt, die mit dem Problem in Verbindung stehen, oder wenn man das Modell zwingt, das Lernen vorzeitig zu beenden. In diesem Fall ist das erstellte Modell zu einfach und es besteht die Gefahr, dass der allgemeine Trend übersehen wird.
Ein unterangepasstes Modell passt sich schlecht an das Trainingsset an. Es wird verzerrte Vorhersagen machen, weil es nicht ausreichend trainiert wurde, und es wird in der Lernphase viele Fehler machen.
Mit anderen Worten: Ein zu generalistisches Lernmodell ist nicht in der Lage, genaue Vorhersageanalysen zu liefern.
Daher ist es wichtig, dieses Konzept im Machine Learning zu beherrschen, bevor man geeignete Modelle entwirft. Bevor wir uns jedoch ansehen, wie man Underfitting vermeiden kann, wollen wir uns auch mit seinem Gegenteil beschäftigen.
Overfitting als Gegenpol zum Underfitting
Im Gegensatz zum Underfitting wird das Overfitting als Überanpassung oder Überlernen bezeichnet.
Hier werden möglichst viele Variablen verwendet, um auf alle Hypothesen vorbereitet zu sein. Aber Vorsicht: Es besteht die Gefahr, dass man zu viele Variablen verwendet, die für die aktuelle Studie nicht relevant sind.
Zwar führt diese Methode zu ähnlichen Fehlerniveaus beim Lernen und bei der Validierung, doch wird das Modell dadurch stark komplexer. Dies bedeutet, dass die Anzahl der zu schätzenden Parameter steigt. Infolgedessen wird das Modell mehr irreführende Korrelationen erkennen.
Das überangepasste Modell konzentriert sich darauf, sich die sehr spezifischen Eigenheiten der Daten zu merken. Man sagt, dass es sich an das Rauschen in den Daten anpasst. Mit der Zeit wird es kausale Zusammenhänge zwischen Daten finden, die nichts miteinander zu tun haben. Dann kann er bei Lerndaten sehr gut abschneiden, aber das geht auf Kosten des allgemeinen Trends.
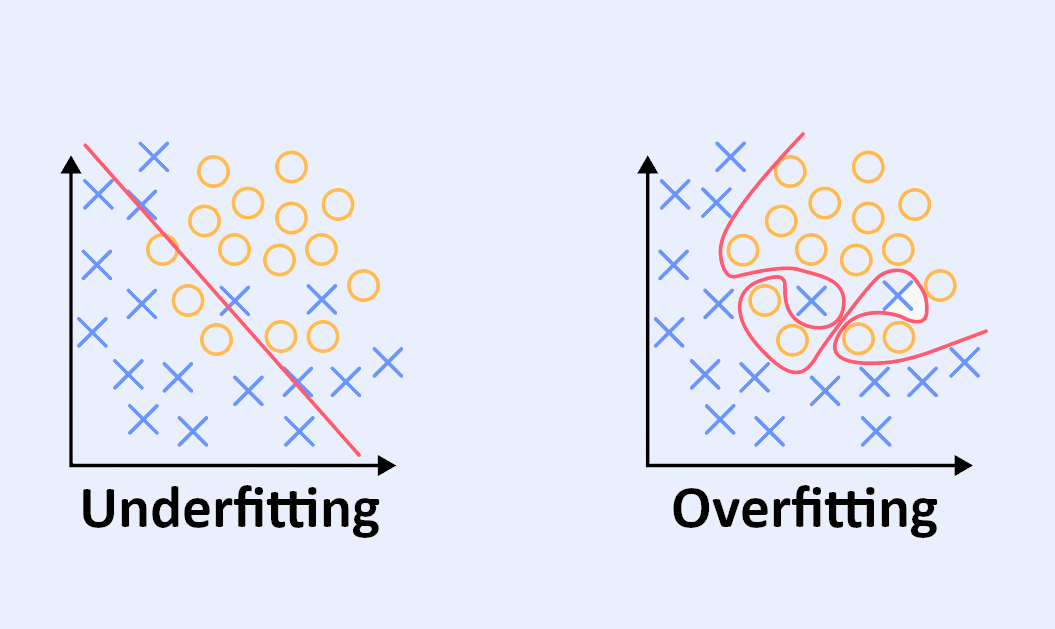
Wie kann man Underfitting vermeiden?
Die Herausforderung für Data Scientists besteht darin, das richtige Modell zu entwerfen, das weder zu einfach noch zu komplex ist. Das heißt, Underfitting zu vermeiden, aber nicht in Overfitting zu verfallen.
Um dies zu erreichen, musst du den Sweet Spot identifizieren, der die richtige Balance findet. Zuvor musst du jedoch lernen, wie du Underfitting und Overfitting erkennen kannst.
Wenn die Testdaten eine niedrige Fehlerrate haben, die Trainingsdaten aber eine hohe Fehlerrate, liegt wahrscheinlich ein Underfitting vor.
In diesem Fall solltest du darauf achten, dass das Modell nicht zu komplex wird. Hier wird die umgekehrte Situation eintreten, nämlich: Trainingsdaten mit einer niedrigen Fehlerrate und Testdaten mit einer hohen Fehlerrate. Overfitting ist charakterisiert.
Sobald du in der Lage bist, das eine oder andere zu identifizieren, kannst du das Vorhersagemodell in der Lernphase verfeinern. Dadurch werden die Fehler im Trainingsset schrittweise reduziert.
Die Data Scientists müssen das Modell weiter verfeinern, bis die Fehler in der Validierungsphase ansteigen. Das Gleichgewicht liegt kurz bevor diese Fehler in dieser Phase ansteigen.
Wenn du diese Methode anwendest, kannst du den vorherrschenden Trend erkennen und ihn weitgehend auf neue Datensätze anwenden.
DataScientest, um Machine Learning-Modelle zu meistern
Die richtige Balance zwischen Underfitting und Overfitting zu finden, erfordert Übung und mehr Wissen über die Datenanalyse.
Genau aus diesem Grund bietet DataScientest verschiedene Schulungen im Bereich Machine Learning an. Zögere nicht, dir unsere Programme anzusehen.







