
What is web scraping?
As a Data Scientist, Data Engineer, or Data Analyst, you often find yourself handling datasets that will feed into an application, a Machine Learning algorithm, or data analysis.
In some cases, you may use pre-constructed datasets, but there are instances where you need to create your own dataset or supplement an existing one by collecting information from the internet.
Manually retrieving information, such as copying and pasting the content you need from each webpage, is impractical when dealing with a substantial amount of data. Fortunately, automating the collection of online content is possible through web scraping.
Web scraping refers to the automatic retrieval of data and content from the internet. Python offers several libraries that enable web scraping.
Among them, Beautiful Soup is perhaps the most well-known and has the advantage of being user-friendly.
However, it is not capable of retrieving dynamically inserted information on a webpage via JavaScript.
Today, we will focus on the Selenium framework, which, among other benefits, allows for this capability.
Why use Selenium for web scrapping?
Selenium is an open-source framework originally developed for running automated tests on various web browsers (Chrome, Internet Explorer, Firefox, Safari, etc.). This library is also used for web scraping because it enables navigation between web pages and interaction with page elements as a real user would. This makes it possible to scrape dynamic websites, which are sites that return specific results to the user based on their actions.
In the rest of this article, we will see how to use Selenium to retrieve news articles from the Euronews website and create a dataframe ready for use in a text mining project.
Case study: web scraping of press articles from Euronews
To implement our web scraping script and analysis, we will use Jupyter Notebook. First, it will be necessary to install the various libraries required for using Selenium via a pip install in your Python environment.
pip install selenium
pip install webdriver_manager
The Selenium module provides access to:
- The Selenium webdriver, an essential component that interprets our code, here in the Python language, and interacts with the browser. In this tutorial, we will use a web driver that controls the Chrome browser.
- The By method, which allows us to interact with the DOM and find elements on the web page.
The WebDriver Manager module ensures the management (download, configuration, and maintenance) of the drivers required by Selenium WebDriver.
Now let’s import the libraries – we’ll need:
- import time
- import pandas as pd
- from selenium import webdriver
- from selenium.webdriver.common.by import By
- from selenium.webdriver.common.keys import Keys
- from webdriver_manager.chrome import
- ChromeDriverManager
We’re ready to dive into the subject. We will scrape articles from Euronews published yesterday.
Here’s an overview of the different steps we will perform:
1. Navigate to the archive page of articles from the previous day.
2. Retrieve the links to all articles published yesterday and store them in a list.
3. Iterate over the links in our list and create another list containing a dictionary for each article with:
– The article’s title
– The date it was published
– The authors
– The paragraphs of the article
– The category
– The link to the article.
4. Conduct a quick visual analysis of our text corpus.
Step 1: Use Selenium to access previous day's articles
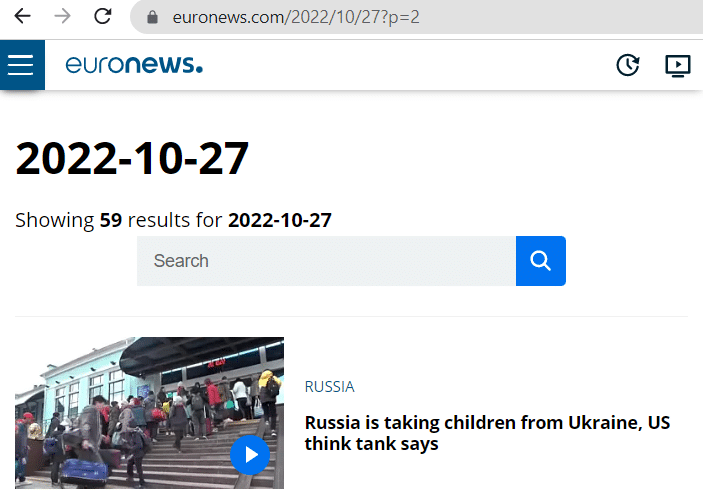
First, let’s take a look at the structure of Euronews’ archive URLs. To retrieve articles from a specific day, the URL follows this format: https://www.euronews.com/{year}/{month}/{day}.
We also notice that there is pagination with 30 articles per page. When the number of articles exceeds 30, you can navigate to other pages by adding a query parameter to the URL: https://www.euronews.com/{year}/{month}/{day}?p={page}
To retrieve the date of the previous day, we use the datetime library and create three variables containing the year, month, and day.
Let’s test the Selenium library by initializing a Chrome webdriver. The code below allows us to automate with Selenium everything we would have done manually: opening the browser, accessing the Euronews page containing articles from the previous day, clicking the cookie acceptance button, and scrolling on the page.
It’s worth noting that the “scroll” function has been defined in a cell located higher up in the notebook.
Here is a video showing the result of our code:
Taking control of a Chrome browser with Selenium
Step 2: Retrieve article links
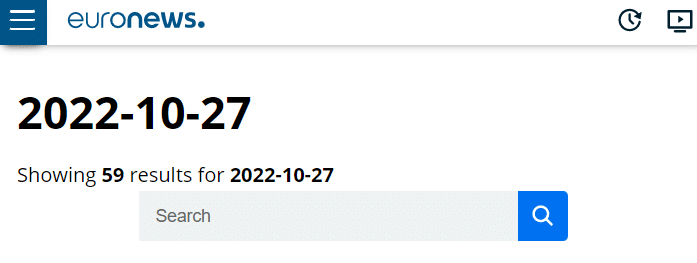
We notice that the number of articles for a given day is written on the web page, which will tell us how many pages we need to retrieve the articles from:
Regardless of the web scraping libraries used, it’s essential to inspect the page to identify the elements of the web page that interest us. We can access them via CSS selectors.
To inspect a page, right-click and then click “Inspect,” or use the shortcut Ctrl + Cmd + C on macOS or Ctrl + Shift + C on Windows and Linux.
How do I inspect a web page?
Thanks to Selenium’s BY class (which we’ll use instead of the .find_elements_by method), we can choose between several types of properties to locate an element on a web page, including :
- Element ID
- Element name
- Tag name
- Xpath
- Its class
After inspection, we see that the element counter is located in the first strong tag of the “c-block-listing__results” class.
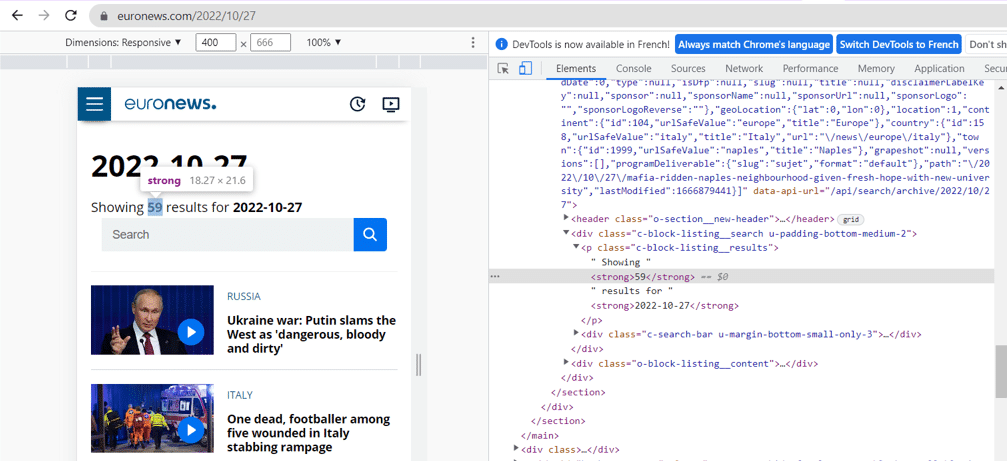
To retrieve the element, we will use its XPath. XPath is an XML path that allows you to navigate the HTML structure of a page and find any element on it. In web scraping, it is particularly useful to use the XPath path of an element when the element’s class alone is not sufficient to identify it, for example, when we want to retrieve a subtag of an element with a certain class.
The Xpath of an HTML element is structured as follows:
//tag_name_of_major_element[@attribute="Value"]/tag_name_of_sub_element[index_of_the_sub_element]
Where:
- tag_name_of_major_element corresponds to the main tag (div, img, p, b etc.)
- attribute corresponds to the element’s class or id and value to its value
- tag_name_of_sub_element corresponds to the tag of the sub tag
- index_of_the_sub_element starts at 1 and corresponds to the number of the sub-tag. This index is only used if there are several sub-elements contained in the main tag.
The method .text, allows us to access the text value of the element, here “57”.
Using the number of items retrieved and the pagination at 30 we’ve observed, we calculate the number of pages we’ll need to scrape, in this case 2.
We’re now going to retrieve the links for the various articles. On inspection, we notice that the article links have the object__title__link class. We retrieve all elements with this class and create a list containing, for each element, the value of the href attribute (which contains the link) retrieved using the get attribute method.
Step 3: Scraping the content of each article
We’re now entering the crucial part of this article: scraping each article from the list created earlier. Let’s inspect the structure of the HTML page:
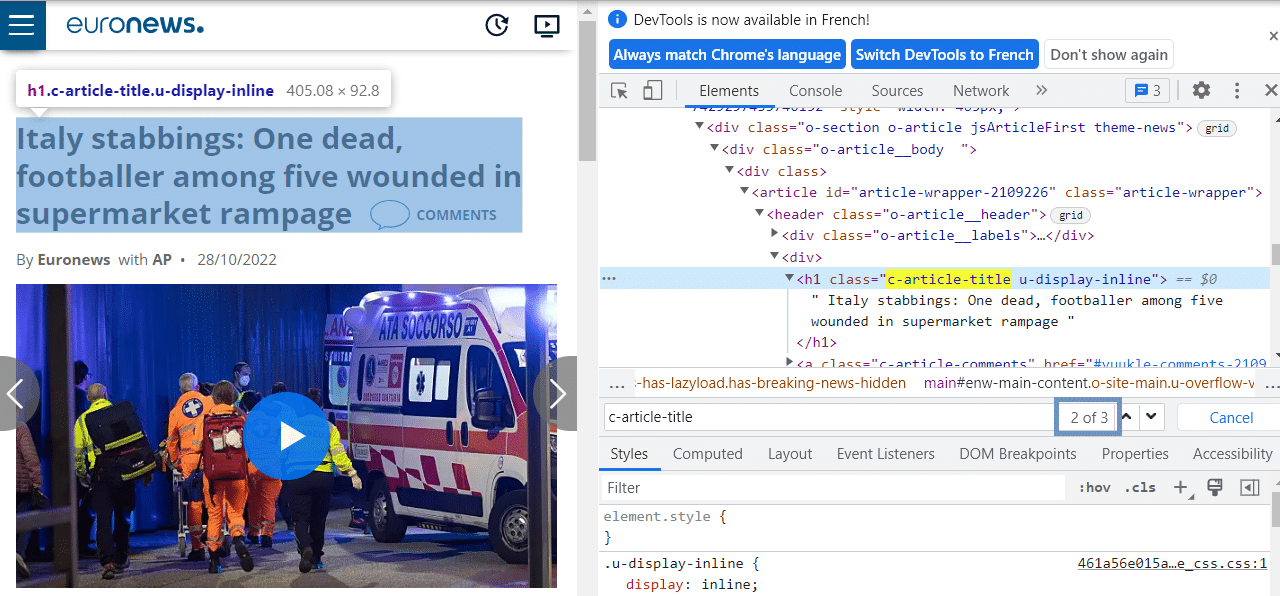
We can observe that the contextual data we’re interested in, such as the title, author, category, etc., are consistently in the second position among the located classes. Indeed, in the first position, the HTML contains information about the previous article, which is not displayed on the page.
The code below retrieves the content we’re interested in on the page:
Here are the different steps of the previous code:
1. Access each article.
2. Retrieve the text from the contextual data of the article (title, authors, category, publication date).
3. Retrieve the paragraphs of the article.
4. Create a dictionary with the retrieved data.
5. Add this dictionary to a list named “list_of_articles.”
6. In case of an error, record the link of the article in an “errors” list.
Note: It’s noticeable that the majority of articles in error are video articles with a different HTML structure. For the purpose of this article, we decide not to handle these few error cases.
Here is a video showing the result of our code for the first scraped pages.
Automatic page navigation with Selenium
Step 4: Quick view
Before concluding, we’ll take a quick look at the scraped articles. This is one of the first steps in a Natural Processing Language (NLP) project.
First, we import the libraries we’ll need for the rest of the process, then build a dataframe using the list_of_articles dictionary list.
Here are the first lines of the dataframe:

First, we’ll look at the different article categories, displaying the number of articles per category using the Seaborn library.
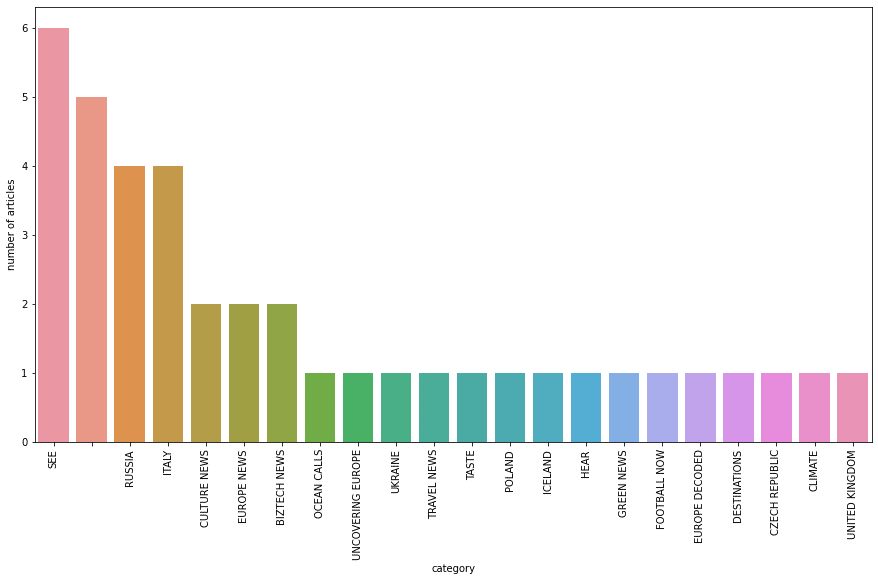
Before displaying the word cloud, we remove stopwords using the stopwords class in the nltk.corpus package.
Finally, we define a function to build a word cloud using the wordcloud module, which takes our article series as an argument.
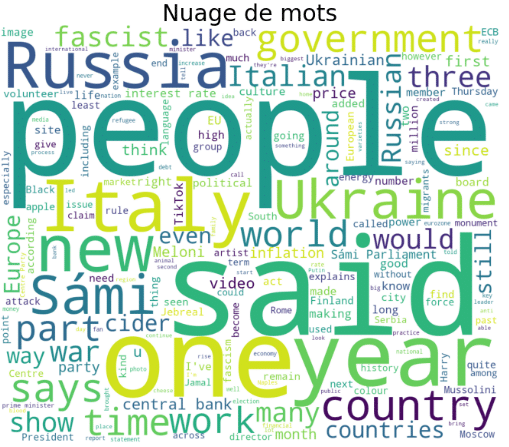
That’s it, we’ve come to the end of this tutorial, which has shown how Selenium can help you scrape data from the Internet, and given us the opportunity to perform a quick visual analysis on textual data.
If you’d like to find out more about how web scraping is used in the various data professions, take a look at our article on the subject, or find out more about the content of our various courses.








