
Apache ZooKeeper is an open-source distributed coordination system that provides a platform for configuration management, process synchronization, and lock management. Originally developed by Yahoo, it is now maintained by the Apache Software Foundation.
ZooKeeper also offers high availability and fault tolerance, making it a reliable solution for large-scale distributed environments. It can handle very high workloads and is designed to adapt to increasingly complex environments.
In this article, we will attempt to uncover how it works and understand its fundamentals.
How does Zookeeper work?
Let’s begin by describing the architecture of Apache ZooKeeper.
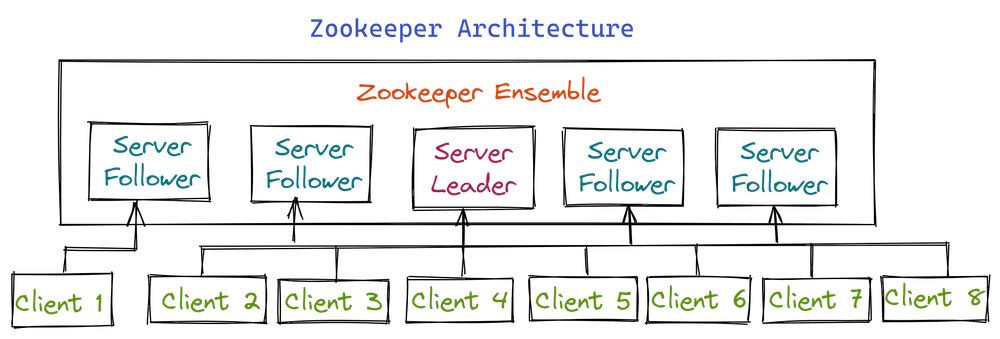
et’s describe each element of the Apache ZooKeeper architecture as outlined in your provided information:
Client (Application Client):
- A client refers to an application that interacts with the ZooKeeper service by sending requests to the ZooKeeper servers.
- Clients can connect to any ZooKeeper server, and that server will redirect the client’s request to the appropriate server in the ensemble.
- Clients use ZooKeeper to manage configurations, synchronize distributed services, and receive notifications about changes in the distributed system.
Server (ZooKeeper Server Node):
- A server is a node within the ZooKeeper cluster responsible for handling incoming client requests.
- Servers store and maintain the data used for distributed coordination and synchronization.
- Servers can replicate data among themselves to ensure high availability and fault tolerance. Replication helps in maintaining consistent data across the ensemble.
Leader (ZooKeeper Leader):
- Within the ensemble, one server is elected as the leader.
- The leader is responsible for coordinating and managing the replication of data across all servers in the ensemble.
- It handles client requests, processes transactions, and assigns tasks to other servers.
- If the leader fails for any reason, another server is immediately elected to take its place and assume its functions. This leader election ensures continuous operation.
Follower (ZooKeeper Follower):
- A follower, also known as a “suiveur,” is a ZooKeeper server node that follows the instructions and state changes dictated by the leader.
- Followers replicate the leader’s data and maintain an up-to-date copy of the distributed state.
- While followers cannot make authoritative decisions on their own, they play a critical role in maintaining data consistency and ensuring fault tolerance.
Ensemble (ZooKeeper Ensemble):
- The ensemble refers to the group of ZooKeeper servers that collectively provide the ZooKeeper service.
- Typically, an ensemble consists of an odd number of servers (e.g., 3, 5, 7) to ensure that a majority of servers must agree on the state for decisions to be made.
- The ensemble is the foundation of ZooKeeper’s high availability and fault tolerance features, as it ensures that the system can continue to operate even if some servers fail or become unreachable.
In summary, ZooKeeper follows a “client-server” architecture, where clients are applications that interact with the ZooKeeper service through servers. Servers are nodes within the ZooKeeper cluster responsible for managing data and handling client requests. The leader coordinates the replication of data, while followers replicate the leader’s state. The ensemble is the group of ZooKeeper servers working together to provide a reliable distributed coordination and synchronization service.
What is a data model?
ZooKeeper uses a data model based on a hierarchy of nodes, similar to the structure of a file system. Therefore, each node is identified by a unique path within the tree. They can have children, which are essentially nodes placed under the parent node in the hierarchy. This tree-like structure allows for the creation of complex data structures to represent the information required for the coordination and synchronization of distributed applications.
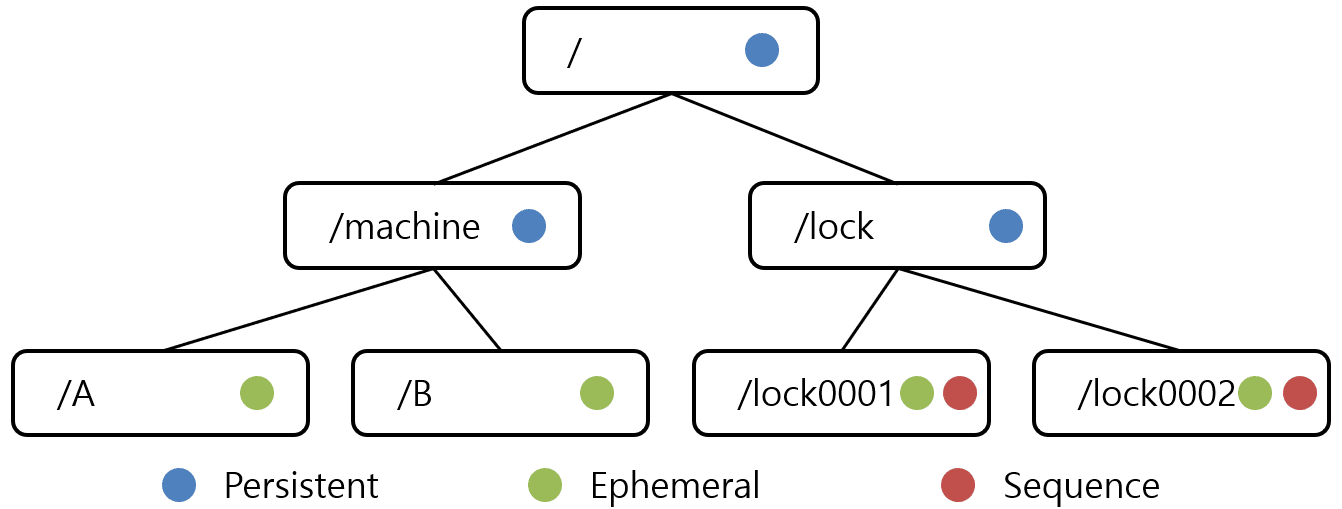
In Apache ZooKeeper, each node is referred to as a Znode, and each Znode is identified by a name.
Each of these Znodes in the ZooKeeper data model maintains a stat structure. It simply provides the metadata for a Znode, which consists of the following elements:
1. Version number increases every time data associated with the Znode changes. This concept is crucial when multiple clients attempt operations on the same Znode.
2. ACLs (Access Control Lists) act as an authentication mechanism to access the Znode.
3. Timestamp represents the time elapsed since the creation or last modification of the Znode, expressed in milliseconds. This change is identified by the transaction identifier (zxid). This zxid is unique and enables easy identification of the time elapsed between multiple requests.
4. Data length represents the total amount of data stored in a Znode. It is possible to store a maximum of 1 megabyte of data.
What are the different types of knot?
Znodes can take on different types in ZooKeeper:
1. Persistent Znodes: These nodes persist even if the client that created the Znode disconnects. By default, all Znodes are persistent unless specified otherwise.
2. Ephemeral Znodes: They remain active as long as the client is connected. When a client disconnects, ephemeral Znodes are automatically deleted. Due to this, they cannot have additional children. When an ephemeral Znode is deleted, the next appropriate node fills its position. Ephemeral Znodes play a crucial role in leader election.
3. Sequential Znodes: This type of Znode can be either persistent or ephemeral. When a sequential Znode is created, ZooKeeper appends a 10-digit sequence to the original name, forming the Znode’s path.
For example, if a Znode with the path /myapp is created as a sequential Znode, ZooKeeper will change the path to /myapp0000000001 and set the next sequence number to 0000000002.
In the case of two sequential Znodes being created simultaneously, ZooKeeper will never use the same number for each Znode. This type of Znode plays a significant role in locking and synchronization.
Les sessions
This is a very important concept for ZooKeeper’s operations. At regular intervals, heartbeats are sent by the client to keep its session active.
If no heartbeats reach the ZooKeeper set, the client is considered “dead”, and ephemeral znodes are deleted.
Watches
This mechanism enables customers to receive notifications of changes to the Apache ZooKeeper package. They can define watches when reading a particular node, and these watches send the client a recorded notification of any changes to the node.
💡Related articles:
Conclusion
Apache ZooKeeper is a distributed coordination system, which presents itself as a single entity, but conceals an entire complex system. It solves all the problems encountered by distributed applications thanks to its framework, which also provides a number of services, including configuration management and naming services.
Now that you know all about coordination and synchronization with Apache ZooKeeper, don’t hesitate to sign up for a DataScientest training course to learn more. Find out more about our data courses!








