
As an Internet browser, we have access to a lot of information about customers, offers, share prices, physical phenomena and so on. This data can be read by users, but we'd like to be able to exploit it by transforming it into an operational format so that we can analyze it and make the most of it. Web scraping is the technique that enables this information to be extracted in a format that can be used by computer programs. In this article, we'll find out how to do it with Beautiful Soup.
What is Beautiful Soup?
For example, you might want to have access to all the reviews of a Pack of HP Black Ink Cartridges on Amazon, so you can perform syntactic, semantic and sentimental analysis and form your own opinion. Web scraping from a store locator (such as a map) can be used to create a list of commercial locations. You can also obtain stock prices to help you make better investment decisions.
As far as data analysis is concerned, there are specific techniques for each type of data and each objective. The following diagram illustrates the “logistical” process involved in making informed decisions:
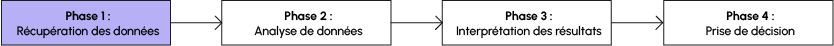
If we’re in the data retrieval phase, we’d like to have access to all the information present on a web page, so that we can then carry out the desired study.
This can be done by copying it “by hand” into another document. But this can be a time-consuming process, not to mention the typing errors that can occur during input. As mentioned in the introduction, web scraping provides access to this information in a usable format.
In the second phase, we call on the technical skills of data analysts, data engineers or data scientists to implement algorithms and relevant statistical studies. For example, when analyzing product reviews, an NLP algorithm can be used, which enables machines to understand human language.
Data interpretation is often carried out within a team, taking into account the opinions of specialists in the field (for example, taking into account the doctor’s opinion if working on a project with medical data), to finally arrive at an optimal decision.
Introducing Beautiful Soup
In this article, we’ll concentrate on Phase 1, since we’re interested in data retrieval.
In the next paragraph, we’ll take a look at an application of the Beautiful Soup library for web scraping in Python.
In the next paragraph, we’ll take a look at a web scraping library available in Python that provides an excellent (and easy-to-handle) tool for extracting information from unstructured data: Beautiful Soup.
The Beautiful Soup Python library extracts content and transforms it into a Python list, array or dictionary.
This library is very popular because of its comprehensive documentation and well-structured functionality. What’s more, there’s a large community offering various solutions for using this library.
Why is it called "Beautiful Soup"?
Websites are written in HTML and CSS, the computer languages used to lay out web pages. HTML is used to manage and organize content. CSS is used to manage the appearance of the web page (colors, text size, etc.).
In web development, “tag soup” is a derogatory term for syntactically or structurally incorrect HTML written for a web page.
An example of web scraping with Beautiful Soup
Let’s take a simple example to familiarize ourselves with these notions. The following example has been taken from Kaggle and the aim is to scrape data on the world’s population. The data is available on the Worldometer site, an open source managed by an international team of volunteer developers and researchers, whose aim is to make global statistics available to a wide audience worldwide.
Here’s a sneak preview of the page we’ll be scraping:
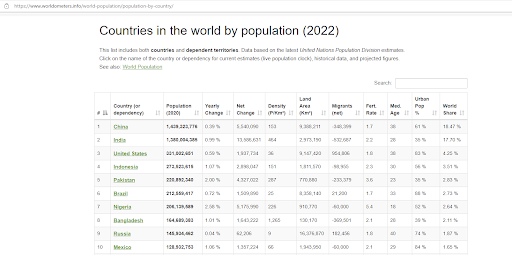
Our aim is to retrieve this table and transform it into a DataFrame without having to copy all the data by hand.
In a Jupyter Notebook, we start by importing the necessary libraries.
- Then we create a url variable in string format (text) containing the link to the page in question.
To prepare the data, use the requests.get() function:
- Now that the data has been prepared, the BeautifulSoup() function is used to extract the HTML code from this page. In the argument to this function, we select the .text object.
- In the variable data we store the HTML code we search for the keyword “table” with the function .find_all() :
- We use the .read_html(str()) command to have the machine read the HTML code and then retrieve the first and only element of this object (the array).
Now we display the first elements, DataFrame .head() command:
- You can also export the database in csv format with the following command:
This command creates a file in csv format, located at the path indicated.
To make it easier to manipulate the DataFrame, consider changing the column names or eliminating some of them if you don’t use them.
Now that we’ve managed to obtain the data made available on the Worldometer site, and that it’s in DataFrame format, we can move on to the next steps and carry out our studies. We can then embark on the rest of the process (Phases 2, 3 and 4, see diagram in introduction). Depending on the nature of the data and the objectives to be achieved, different studies can be carried out: exploratory analysis, proposing a machine learning model, time series modeling, etc.
Beautiful Soup - Conclusion
We’ve just seen an example of how to retrieve data stored in a table, but it’s important to remember that different libraries and functions are used depending on the structure of the web page you want to scrape data from. The good news is that there are many examples available on the Internet, depending on the format of the page and the configuration of the data you want to scrape.
To sum up, web scraping enables you to navigate the Internet “intelligently”, making it a rich resource for any area of research or personal interest.
Datascientest’s Data Analyst training course enables you to familiarize yourself with and put into practice web scraping skills – and not just web scraping skills. If you’d like to learn more about data analysis and gain technical skills related to the subject, don’t hesitate to sign up for the Data Analyst training course.








