
Before you can put a Machine Learning model into production, you first have to determine the most suitable model, select the optimal parameters, etc. These are redundant operations that will apply to different projects. Wouldn't it be simpler to automate these processes? That's where TPOT comes in.
What is TPOT?
TPOT is an extremely useful library for automating the process of selecting the best Machine Learning model and corresponding hyperparameters, saving you time and optimizing your results. Instead of manually testing different models and configurations for each new dataset, TPOT can explore a multitude of Machine Learning pipelines and determine the one most suitable for your specific dataset using genetic programming.
In summary, TPOT simplifies the search for the optimal model and parameters by automating the process, which can significantly speed up the development of Machine Learning models and help you achieve better performance in your data analysis tasks.
Why use TPOT?
Automatic Machine Learning (AutoML) tools address a simple problem: how to make the creation and training of models less time-consuming?
AutoML, as the name suggests, automates a large part of the model creation process without sacrificing quality, allowing Data Scientists to focus on analysis. Its pipeline consists of several processes that help build a high-performing Machine Learning model (feature engineering, model generation, hyperparameter optimization).
To clarify, in Machine Learning, a pipeline encodes and automates the workflow that transforms and correlates data into a model that can be analyzed. The data loading into the model is entirely automated.
A pipeline can also be used to separate the workflow of a model into different independent and reusable parts, simplifying its creation and avoiding task repetition.
A good pipeline enhances the efficiency and scalability of building and deploying Machine Learning models.
Additionally, TPOT offers great flexibility as it can be adapted for neural network models with PyTorch. TPOT also supports the use of Dask for parallel training, further enhancing its capabilities.
How does TPOT work?
TPOT, or Tree-based Pipeline Optimization, uses a structure based on binary decision trees to represent a pipeline model. This includes data preparation, algorithm modeling, hyperparameter settings and model selection.
Below is an example of a pipeline showing the elements automated by TPOT:
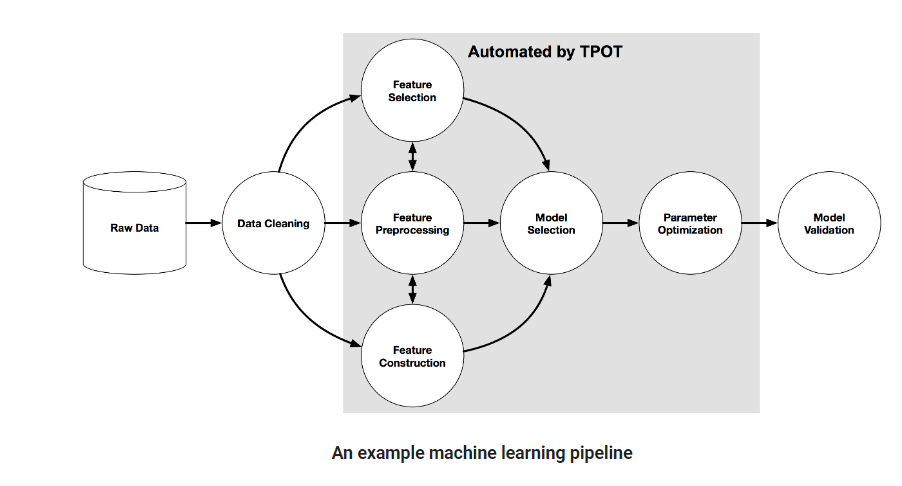
By combining stochastic search algorithms like genetic programming and a flexible expression tree representation, TPOT automatically designs and optimizes features, Machine Learning models, and hyperparameters. The goal is to maximize the accuracy of supervised classification on your dataset.
It’s essential to note that finding the most optimized pipeline may require letting TPOT work for a certain amount of time. Running TPOT for just a few minutes may not be sufficient to discover the best model for your dataset.
Depending on the size of your dataset, TPOT can take several hours or even days to complete its search. For a comprehensive and effective search, it’s recommended to run multiple instances concurrently for several hours.
Since TPOT’s optimization algorithm is stochastic, meaning it involves partial randomization, it’s possible that two runs may recommend different pipelines for the same dataset.
In such cases, either the pipelines may not match due to limited runtime or they may have very similar performance scores.
Find the best pipeline with TPOT
Now that we understand what TPOT is and its significance, let’s see how to set it up and use it. As a reminder, TPOT is based on scikit-learn, which makes its code familiar if you have already worked with this library.
- Start by importing the TPOT modules and any other modules you need to define your model: ‘pip install tpot’.
- During the data transformation step, it’s crucial to rename the target variable and give it the name ‘class’.
TPOT only handles data in numeric format, so you will need to apply the necessary transformations to the explanatory variables. - After splitting your dataset into a training set and a test set, you can define your TPOT Classifier and its parameters.
- To apply TPOT to your dataset, simply use the .fit() method.
- Once the computation is complete, you will see the best pipeline for your dataset in the output. You can then use the .score() method to measure the performance of the model chosen by TPOT.
Below is an example of how to create a pipeline using TPOT:
# For classification
from tpot import TPOTClassifier
# For regression
from tpot import TPOTRegressor
from sklearn.model_selection import train_test_split
# Setting up TPOTClassifier
tpot_classification = TPOTClassifier(verbosity=2, max_time_mins=2, max_eval_time_mins=0.04, population_size=40)
# Setting up TPOTRegressor
tpot_regression = TPOTRegressor(generations=5, population_size=50, scoring=’neg_mean_absolute_error’, cv=cv, verbosity=2, random_state=1, n_jobs=-1)
# Applying TPOT to our training dataset
tpot_classification.fit(X_train, y_train)
tpot_regression.fit(X_train, y_train)
# Calculating the accuracy score
tpot.score(X_test, y_test)
# Extracting the code generated by TPOT to modify the created pipeline
tpot.export(‘tpot_titanic_pipeline.py’)
This code demonstrates how to use TPOT for both classification and regression tasks. You can customize the parameters according to your dataset and requirements. Once TPOT is applied to your data, it will generate the best pipeline, which you can further modify if needed.
Conclusion
TPOT is a very useful tool for finding a first optimized model. It will certainly be necessary to rework the resulting pipeline before sending it into production. However, for initial results, this tool is more than sufficient and will save you a considerable amount of time.








