If machine learning allows organizations to be more efficient and make the best decisions, it is essential for data science experts to master various artificial intelligence algorithms. There are dozens of these algorithms, each serving a specific purpose. In this article, we will precisely examine the different classification algorithms.
What is a classification algorithm?
Definition
First and foremost, it’s important to understand what an algorithm is: a set of operations followed in a specific order to solve a problem or provide new solutions, just like the learning process in an artificial intelligence system.
This is precisely the role of classification algorithms used in machine learning. They allow software to learn autonomously from various datasets.
The idea is to classify the different elements of a dataset into several categories. These categories group the data based on their similarities. Since the data share common characteristics, it becomes easier to predict their behavior.
For example, in an e-commerce store, users who visit the site multiple times are more likely to make a purchase than those who never return. The classification algorithm thus segments users into different categories, enabling the company to tailor its communication.
These various learning models can be used for data analysis and predictive analysis.
Supervised classification
Classification algorithms are part of supervised learning methods, meaning that predictions are made based on historical data.
In contrast to unsupervised learning, where there are no predefined classes, in supervised learning, categories are established based on common attributes, and then predictions are made.
Within supervised algorithms, there is a distinction between classification and prediction (or regression) algorithms. In the case of regression, the goal is to predict new data based on a specific real value, rather than a category.

What are the main classification models?
There are many supervised learning algorithms based on classification. We have compiled the main ones in this non-exhaustive list.*
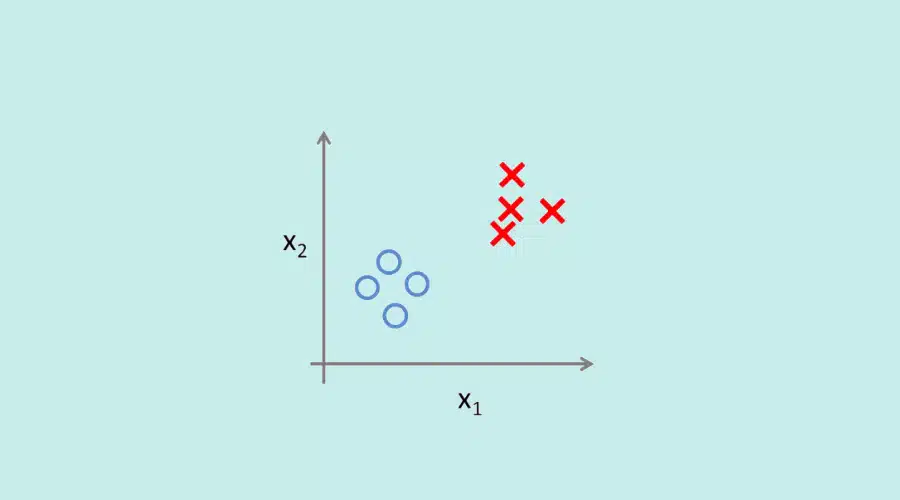
The support vector machine (SVM)
This algorithm is considered a linear classifier. Its role is to separate datasets using lines (called hyperplanes). To do this, the algorithm must maximize the distances between the separating line and the different samples on either side. The samples closest to the line are called support vectors.
The idea is to find the optimal hyperplane, the one that perfectly distinguishes the two classes to minimize classification errors. This allows for clear separation of data to easily identify simple classes, such as large and small cities. When dealing with more complex data, like an individual’s genetic material, it is not as straightforward to identify different categories. In such cases, this algorithm may not be the most relevant choice.
SVM is often found in the finance sector, where it’s used for comparing current and future performance, return on investment, and more.
Important to note: While this algorithm is primarily used for data classification, it can also be applied in regression tasks.
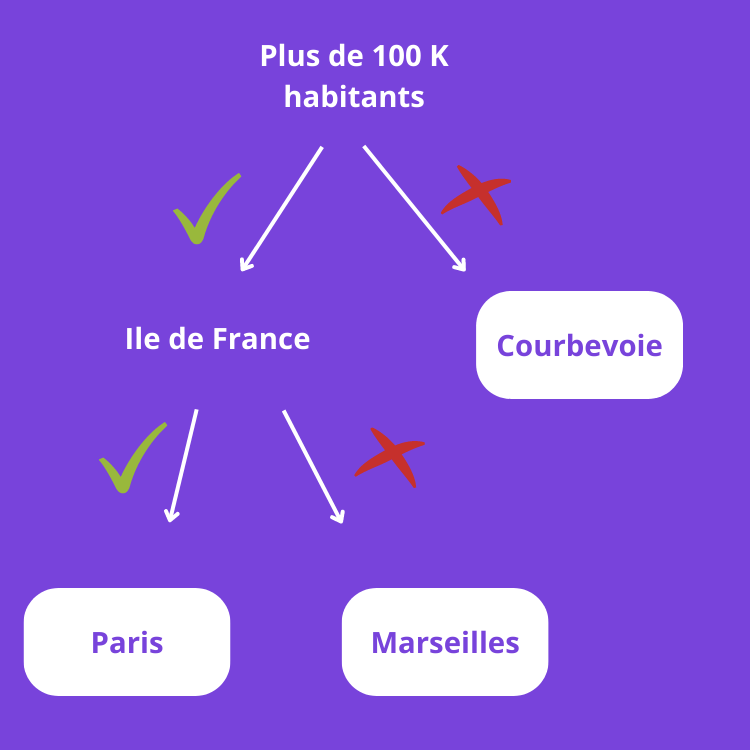
Les arbres de décision
A decision tree is an algorithm that classifies various data into branches. It starts from a root where each data point takes a certain direction based on its behavior. This then allows predicting response variables.
Similar to trees, the intersections are called nodes, and their endpoints are called leaves. The nodes represent the rules for separating the data into different categories, and the leaves are the actual information.
Here’s a very simple example:
| More than 100,000 inhabitants | City in Ile-de-France | |
|---|---|---|
| Paris | Yes | Yes |
| Courbevoie | No | Yes |
| Marseille | Yes | No |
This classification algorithm is very easy to understand, even for non-experts in data. However, when it deals with large volumes of data, it can become more challenging to handle.
It is used for tasks such as predicting changes in interest rates, forecasting market reactions to changes, and more.
K-means distribution
This classification algorithm sorts data into different groups based on their characteristics.
To do this, it establishes a reference average within a dataset, allowing it to define a typical profile.
The advantage of the K-means algorithm is its precision, even when handling large volumes of data quickly.
Due to its efficiency, K-means finds numerous applications, such as search engines providing relevant results based on user expectations, businesses predicting the behavior of prospects or users, IT managers analyzing system and network performance, and more.
The naive Bayesian classifier
This algorithm is based on Bayes’ theorem and conditional probabilities.
It relies on labeled datasets and associates them with other unlabeled data to classify them.
The Naive Bayesian classifier is primarily used in natural language processing, which means it helps machines better understand human language.
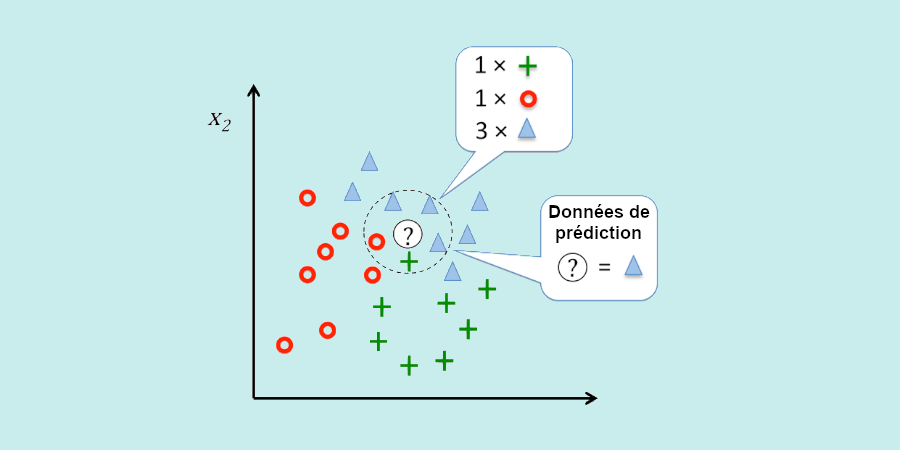
Le KNN (K-nearest neighbors)
K-nearest neighbors (KNN) can be used as both a regression and a classification algorithm, but it is often used in the latter case.
The idea is to classify variables in a dataset by analyzing their similarities. To do this, KNN uses a graph and calculates the distance between different data points. Those that are closest are assigned to the same category.
Linear regression
This is one of the most commonly used classification algorithms. The idea is to perform simple correlations between inputs and outputs. This helps explain how a change in one variable can affect the other.
The simplicity of this model is what makes it popular among data scientists. It requires few parameters, is easy to represent on a graph, and is easy to explain to decision-makers.
In this regard, it is often used in the business domain to forecast sales numbers or, more broadly, to anticipate risks.
Important to note: Unlike logistic regression, which predicts the category of the dependent variable based on the independent variable, linear regression deals with independent variables.
Perceptron
This is one of the simplest and oldest algorithms, as it was invented by Frank Rosenblatt in 1957.
More specifically, it’s a binary classification algorithm. It compares the sum of multiple input signals. If the sum exceeds a certain threshold or not, the Perceptron reaches a conclusion based on a predefined rule. This rule is called the Perceptron Learning Rule, which allows the neural network to learn automatically.
This algorithm is very useful for detecting trends in input data.
Beyond these various classification algorithms, there are still others that allow you to classify data.
How can I find out about machine learning algorithms?
Essential for machine learning, classification algorithms are tools mastered by data scientists and data analysts. To understand them, it is necessary to undergo specialized training in data. This is precisely what our courses at DataScientest offer.








