
The K-Nearest Neighbors (KNN) algorithm is a machine learning algorithm belonging to the class of simple and easy-to-implement supervised learning algorithms. It can be used to solve classification and regression problems. In this article, we will delve into the definition of this algorithm, how it works, and provide a practical programming application.
KNN : Definition
Before delving into the KNN algorithm, it’s essential to revisit the basics. What is a supervised learning algorithm?
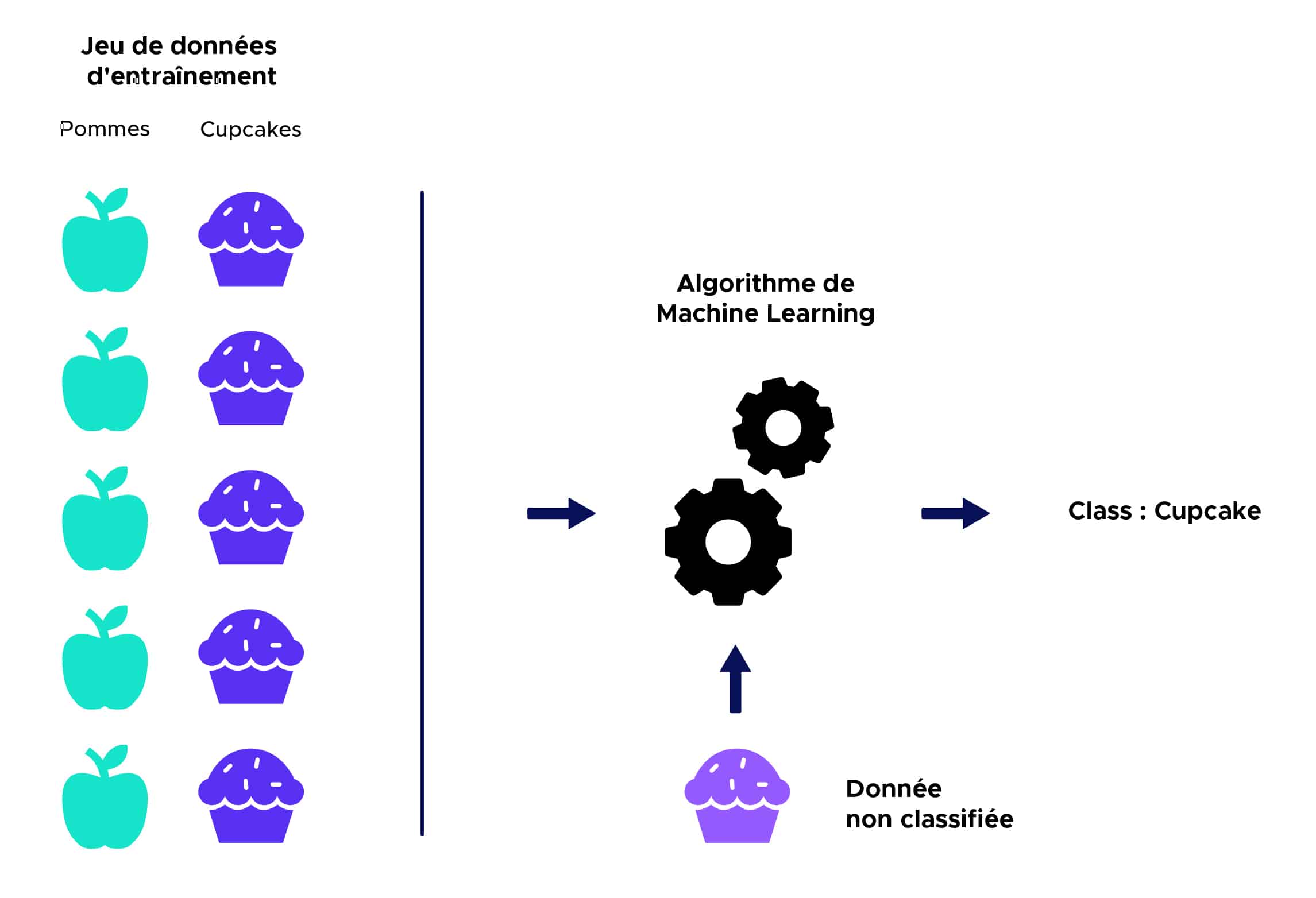
In supervised learning, an algorithm receives a dataset that is labeled with corresponding output values, on which it can train and establish a predictive model. This algorithm can then be used on new data to predict their corresponding output values.
Here’s a simplified illustration:
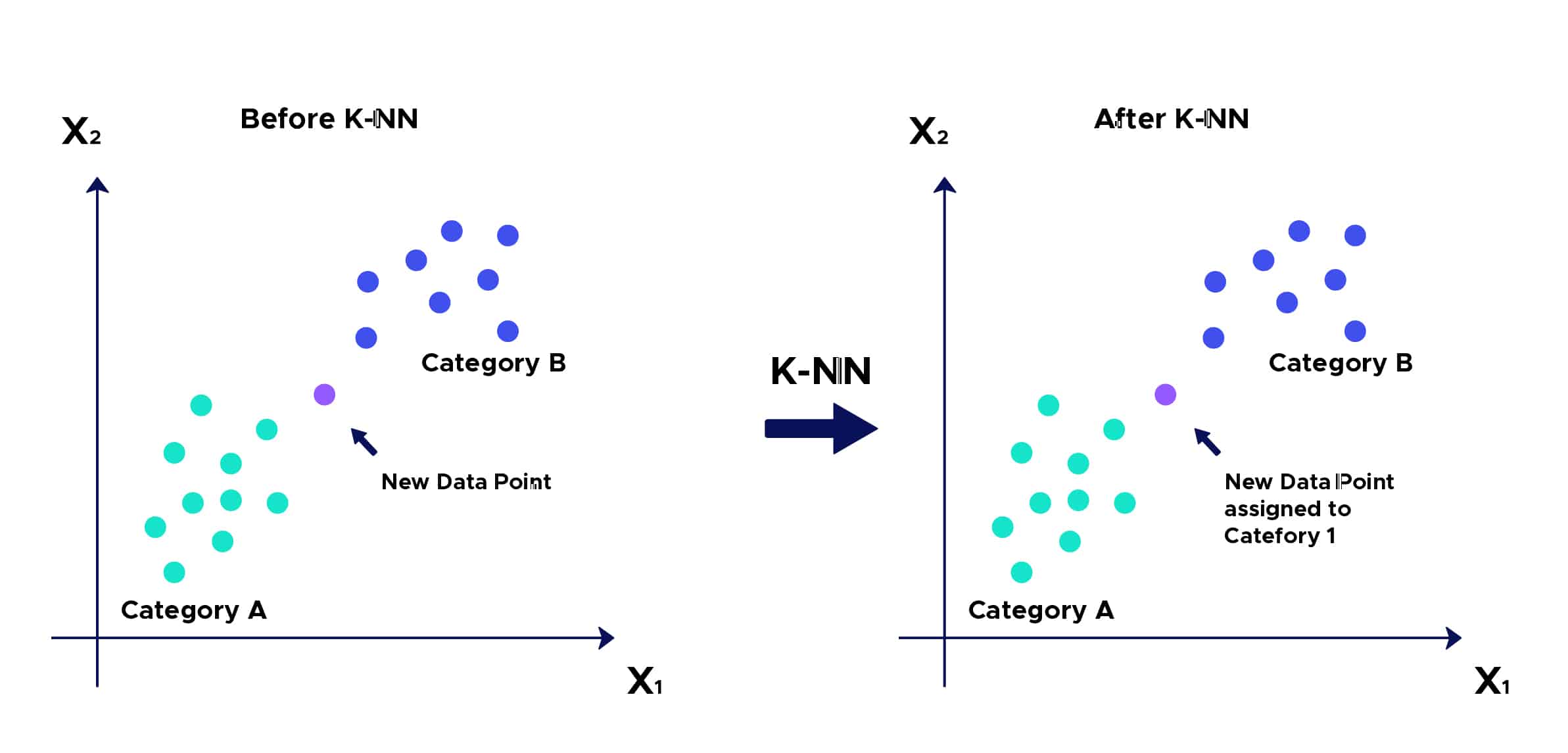
The intuition behind the K-Nearest Neighbors algorithm is one of the simplest among all supervised machine learning algorithms:
Step 1: Select the number K of neighbors.
Step 2: Calculate the distance…
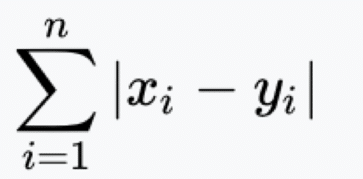
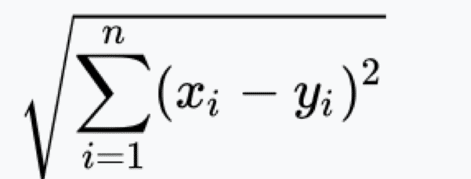
Step 3: Take the KNN – K nearest neighbors based on the calculated distance.
Step 4: Among these K neighbors, count the number of points belonging to each category.
Step 5: Assign the new point to the category most prevalent among these K neighbors.
Step 6: Our model is ready…
KNN : Use Case
We can now explore an example of using the K-Nearest Neighbors algorithm. Thanks to the Scikit-Learn library, we can import the `KNeighborsClassifier` function, which we will use on the IRIS dataset.
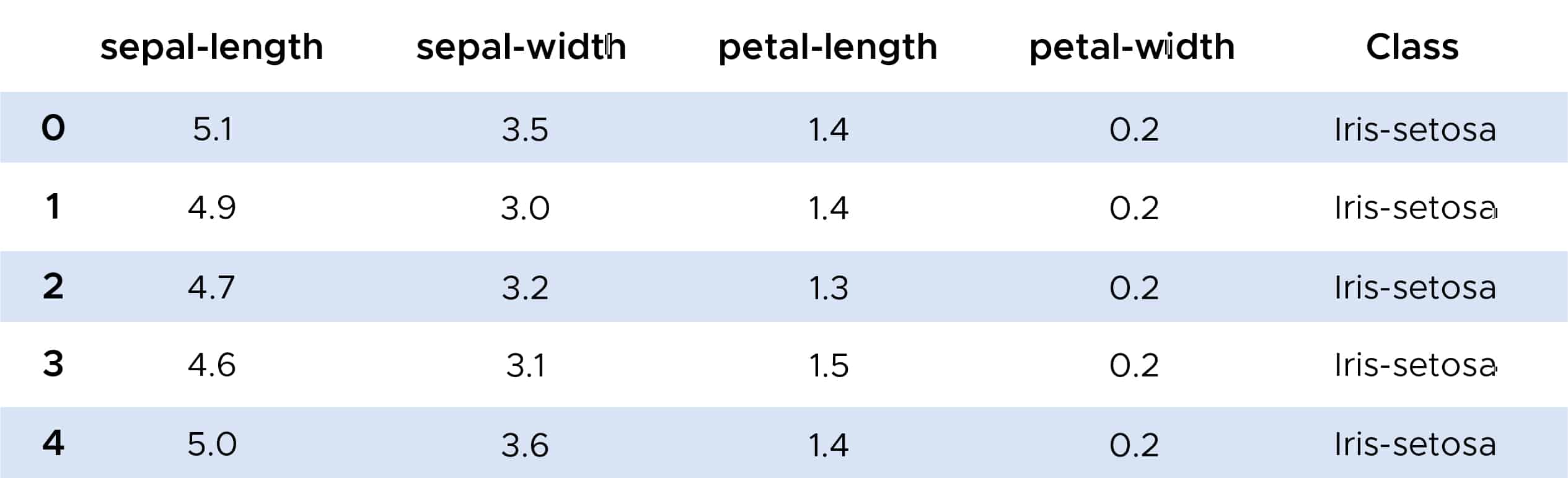
With the KNN algorithm, we achieve an excellent classification rate for plants, approaching 100%. We can also explore a method for choosing the best K for optimal classification. One approach is to create a graph of the K value and the corresponding error rate for the dataset…
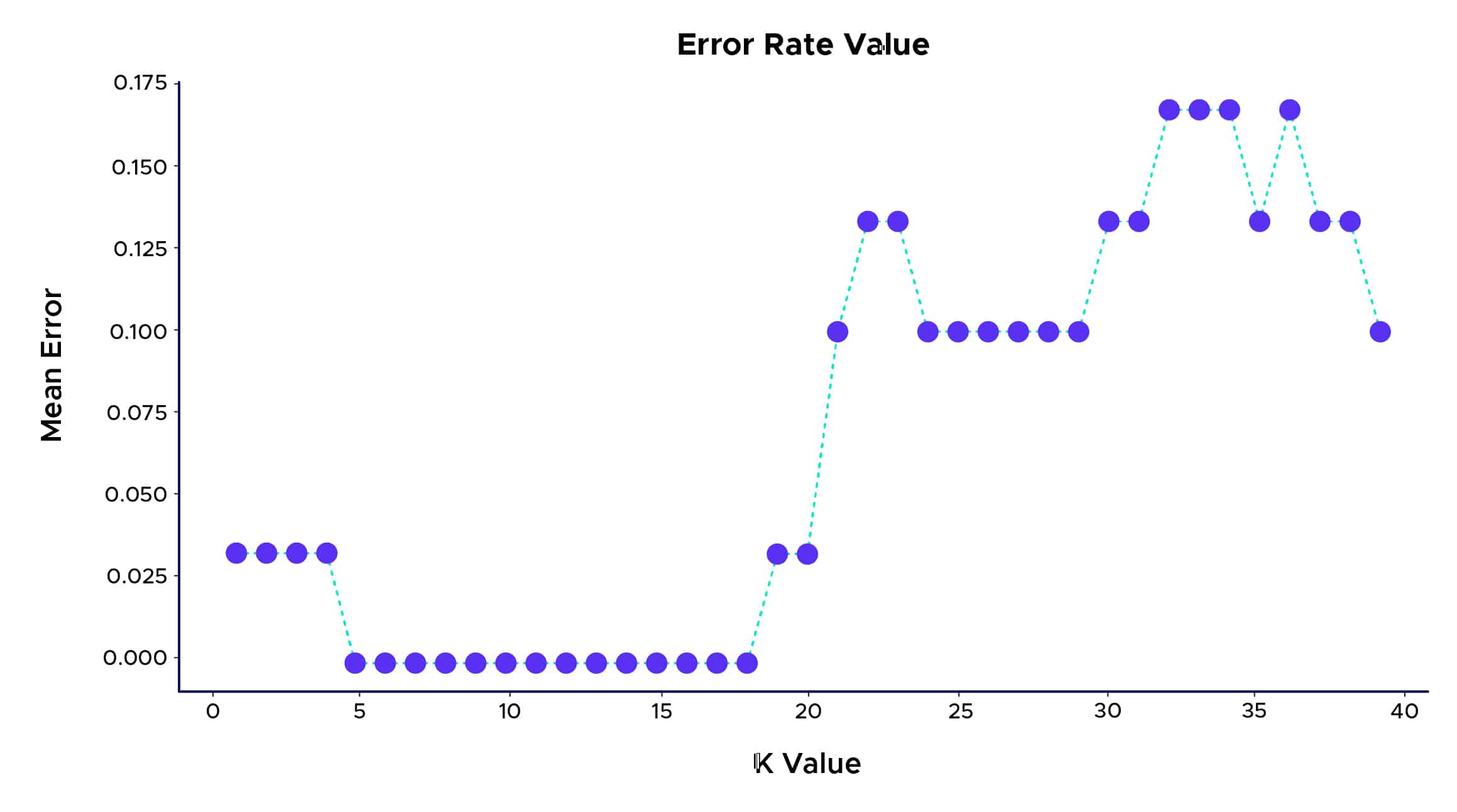
Therefore, we can see that the best prediction rate is achieved for a K value between 5 and 18. Beyond this range, we may observe a phenomenon called “Overfitting” or “Surapprentissage” in French. This occurs when the training data used to build a model fits the data too well but fails to make useful predictions for new data.
Some applications of KNN:
- Optical Character Recognition (OCR): KNN can be used in technologies that attempt to recognize handwritten text, images, and even videos.
- Credit Scoring: KNN matches an individual’s characteristics with existing groups of people to assign a credit score. The individual will receive the same score as those who share similar characteristics.
- Loan Approval: KNN is used to predict whether a bank should grant a loan to an individual. It assesses whether the given individual matches the criteria of those who have previously defaulted on loans or not.
Advantages:
1. The algorithm is simple and easy to implement.
2. There is no need to create a model, tune multiple parameters, or make additional assumptions.
3. The algorithm is versatile and can be used for both classification and regression tasks.
Disadvantages:
1. The algorithm becomes significantly slower as the number of observations and independent variables increases.
Being one of the simplest Machine Learning algorithms, it is highly implemented to develop intuitive and intelligent learning-based systems that can perform and make small decisions on their own.
This makes things even more practical for learning and development and helps almost all types of industries that could use smart systems, solutions, or services.
There are many other supervised or unsupervised clustering algorithms that may be more or less appropriate depending on the situation, such as K-means, hierarchical agglomerative clustering (CAH), DBSCAN (density-based spatial clustering of applications with noise), which you can find on our blog.








