
In recent years, facial recognition technology has proliferated, finding increased use in various fields such as media, social networking, surveillance and security. Deep learning, or Deep Learning, enables the network to learn automatically from data.
Deep learning has proved highly effective for face recognition, with the ability to handle huge volumes of data and achieve high accuracy rates. Deep Learning’s ability to automatically extract information from images, such as facial features, colors and contrasts, is one of its main advantages for facial recognition, in other words, the neural network is able to learn the key properties of identification, leading to a reliable and accurate recognition system.
Data processing, the most important step in the process
Pre-processing is a crucial step before image data is fed into the facial recognition model. Depending on the properties of the available dataset and the particular requirements of the application, the required pre-processing steps may vary. However, they include a number of common operations.
For example, image scaling is used to set the image size for the entire sample set. By defining a resolution of 256 x 256 pixels, the model is guaranteed to process images of the same size, which can increase model performance.
We can also mention the normalization process, which will most likely help your model in its operation. To achieve this, image data can be transformed into a particular color space, or pixel values can be modified to have zero mean and unit variance (Gaussian distribution).
Aligning the face in photos also plays a major role, as model performance can be affected by the position of the face. Facial markers can be used for alignment, and the face can be cropped to a specified position using a bounding box.

Data augmentation: using various image modifications, such as flipping, rotating or cropping, data augmentation is a technique used to fictitiously improve the quantity of the dataset. This could help improve the resilience and generalizability of the model. Below, the human eye is fully capable of identifying that this is the same image that has undergone certain transformations. However, in the eyes of the machine, since the pixels have changed position, the image will be treated as a new sample.

We can also mention background suppression: model performance can be improved by removing background noise from the image. This can be achieved by separating the background from the foreground using image segmentation techniques such as thresholding or edge detection.
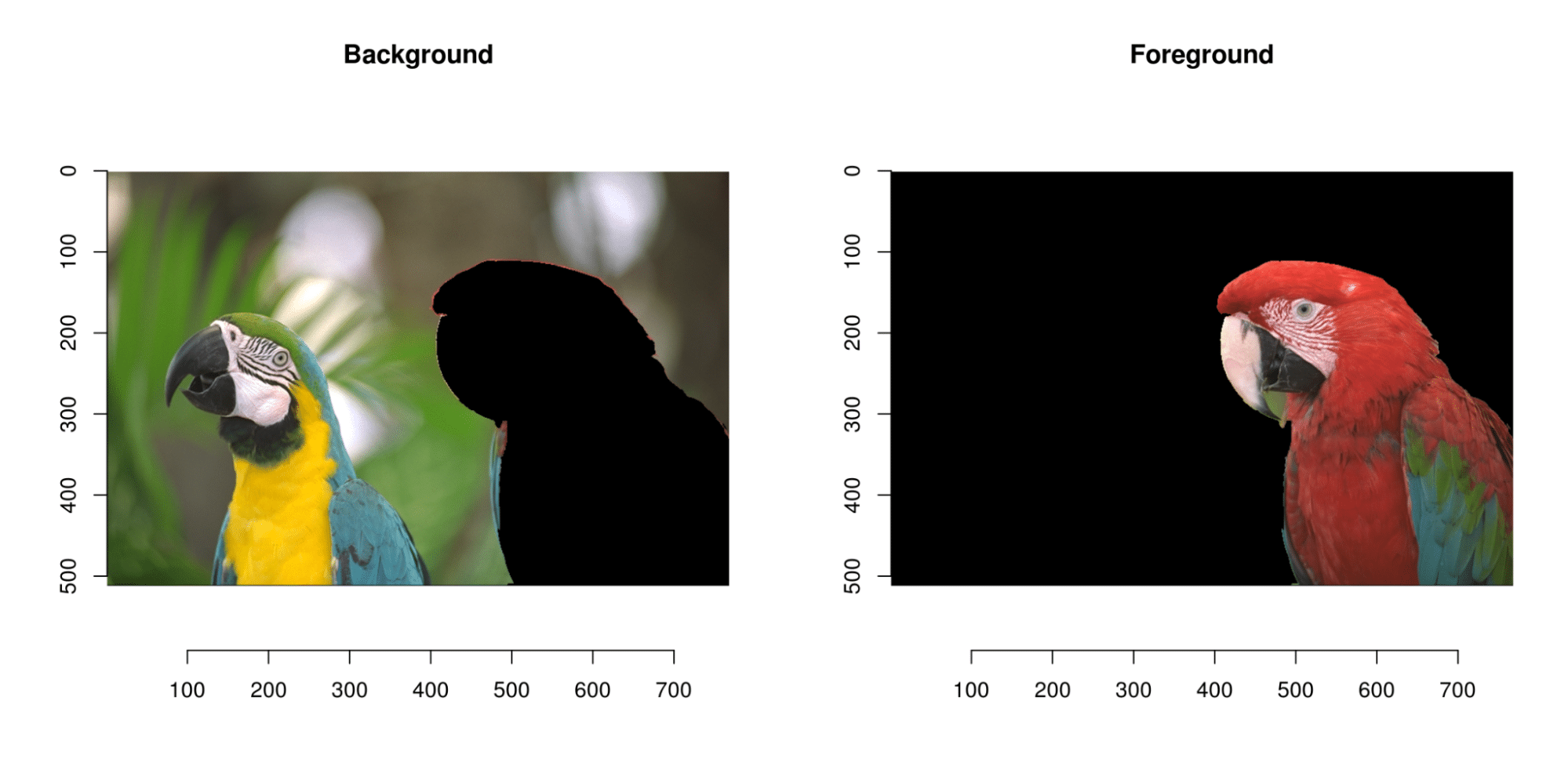
It’s important to bear in mind that the pre-processing procedures used depend on the characteristics of the dataset and the particular needs of the application.
As you can see, pre-processing is a crucial step in facial recognition work, as it prepares the image data for the model and improves the system’s effectiveness, speed and efficiency. Examples of common pre-processing techniques include image scaling, normalization, alignment, data augmentation, background removal and face detection.
Convolutional neural network (CNN) : Definition, features and operation
Convolutional neural networks are a type of deep learning architecture particularly well suited to image recognition tasks such as facial recognition.

In a CNN for facial recognition, the network is trained on a dataset of face and non-face images. The CNN learns to identify important features of a face, such as the shape of the eyes, nose and mouth, as well as the general geometry and texture of the face. These features are then used to identify a face in a new image.
The architecture of a CNN generally consists of several layers, each with a specific function. The first layer, called the input layer, receives the raw image data. Subsequent layers, called convolutional or hidden layers, use a set of filters to extract features from the image. These filters glide over the image (convolution stage), looking for specific patterns and features.
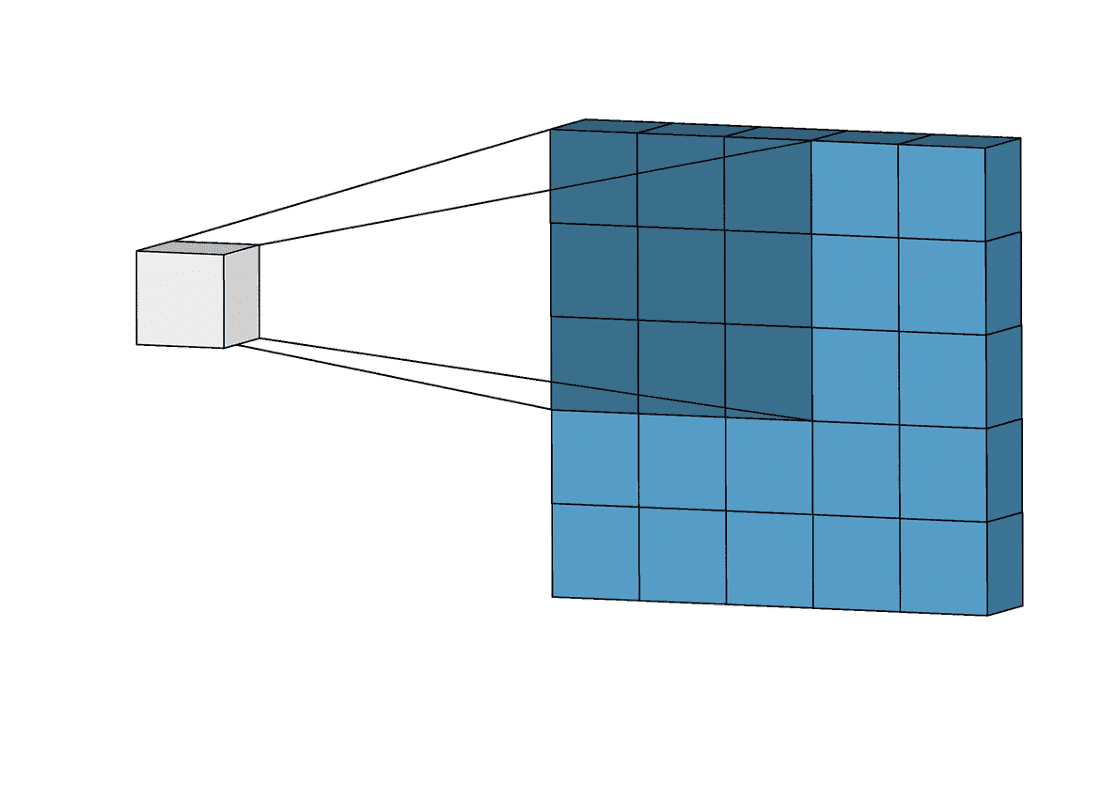
The resulting features are then passed through a non-linear activation function, such as a rectified linear unit (ReLU), which introduces non-linearity into the network and enables it to learn more complex patterns.
After the convolutional layers, the network includes pooling layers, which reduce the spatial resolution of the features learned by the network while retaining important information. This is done by taking the maximum or average of a small region of the feature map. Pooling layers make the network more robust to small changes in the position of the face in the image.
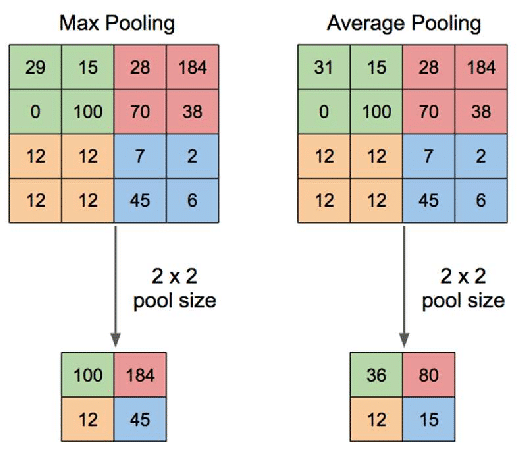
Finally, the features are passed through fully connected layers, which perform the classification task. These layers produce a probability for each possible class – in the case of facial recognition, a face or no face. This output is then compared with a threshold, to make the final decision. This threshold is used to decide how precise the decision should be. For example, if the threshold is 0.9, the model performs the face recognition task only when its performance in associating the image with a particular person is above this value.
It’s important to note that CNNs for facial recognition are trained with a large dataset of images of different individuals, enabling them to identify a wide range of people with high accuracy. However, a diverse dataset is necessary to avoid bias, as the performance of these models can be affected by the demographics of the individuals in the dataset.
What are the competing architectures to convolutional neural networks?
Several new Deep Learning Architectures have been developed for facial recognition in recent years. Here are just a few examples:
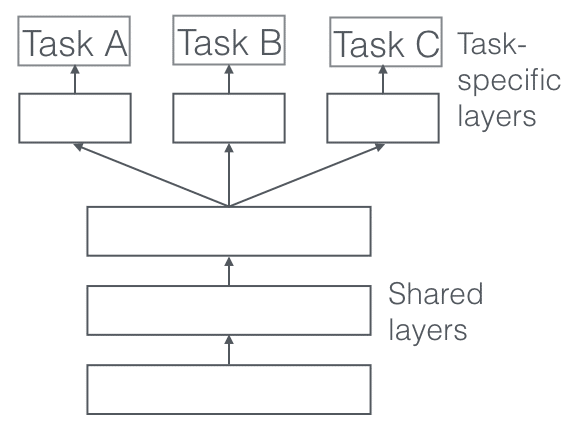
Multi-task learning (MTL) architectures: multi-task learning is a type of deep learning architecture capable of learning several tasks simultaneously, such as facial recognition and facial landmark detection. This can improve overall model performance and reduce the amount of data required for training.
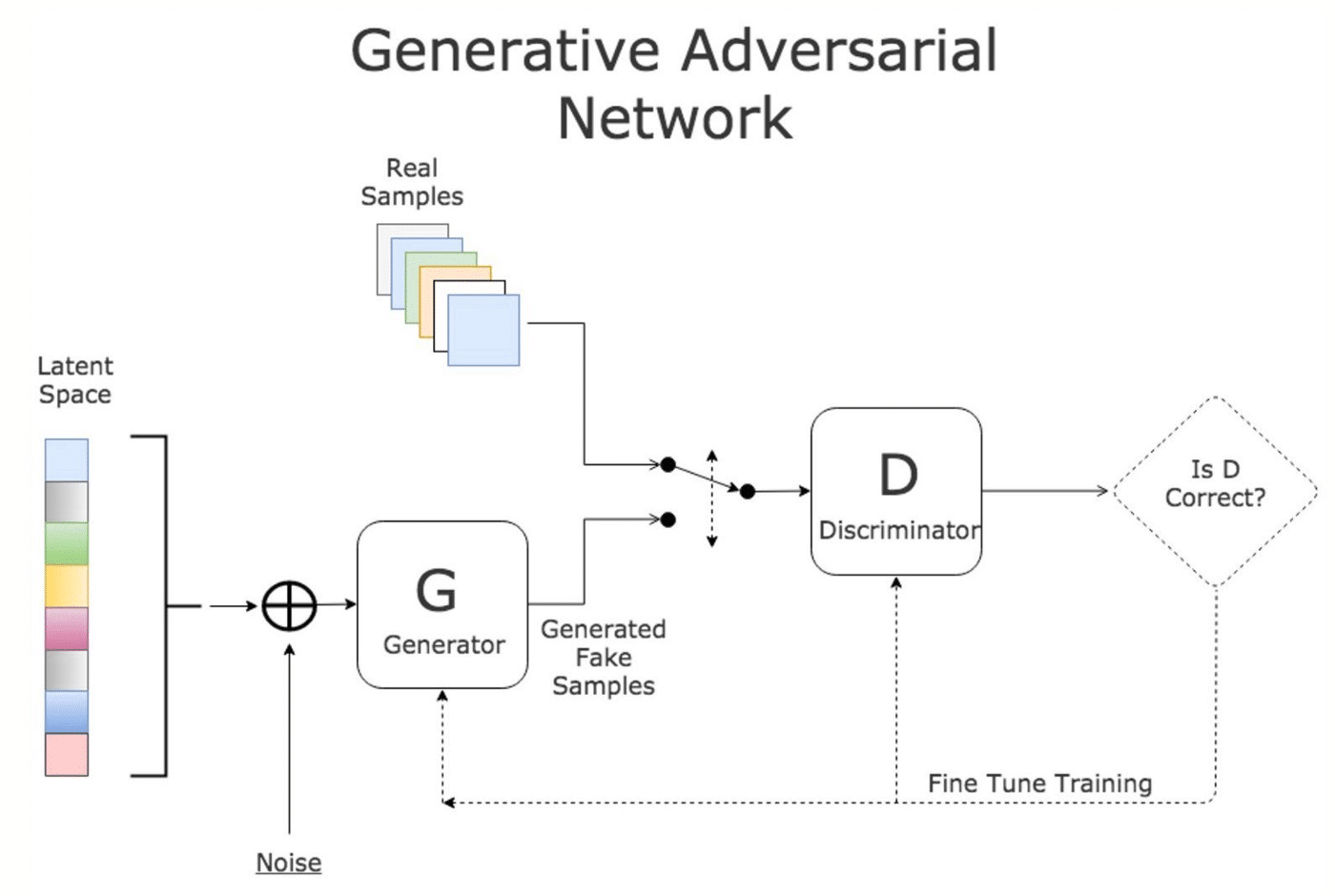
Generative Adversarial Networks (GANs): GANs are a type of deep learning architecture consisting of two networks: a generator and a discriminator. The generator creates new images similar to the training data, while the discriminator tries to distinguish between the generated images and the real ones. GANs have been used for facial recognition by training the generator to create images of faces that can fool the discriminator.
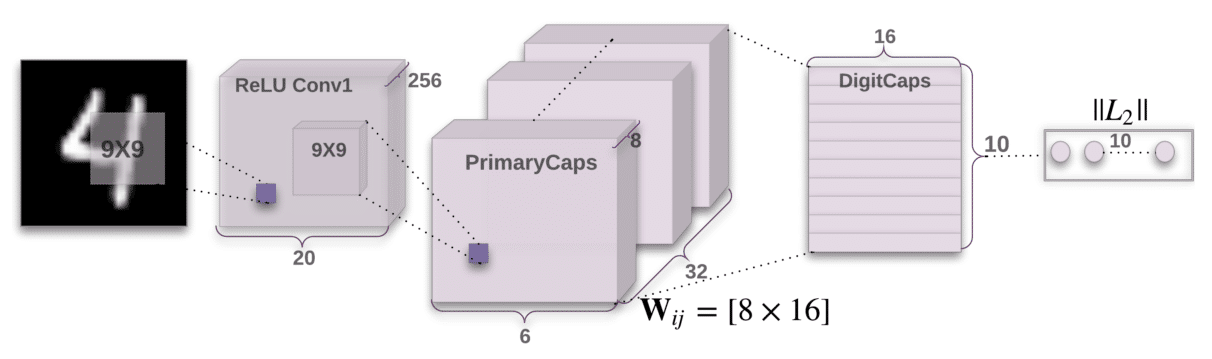
Capsule networks: capsule networks are a type of Deep Learning architecture designed to better capture the spatial relationships between parts of an image, such as the position of the eyes, nose and mouth on a face. This can improve the accuracy of facial recognition, particularly when dealing with faces that are partially obscured or from different angles.
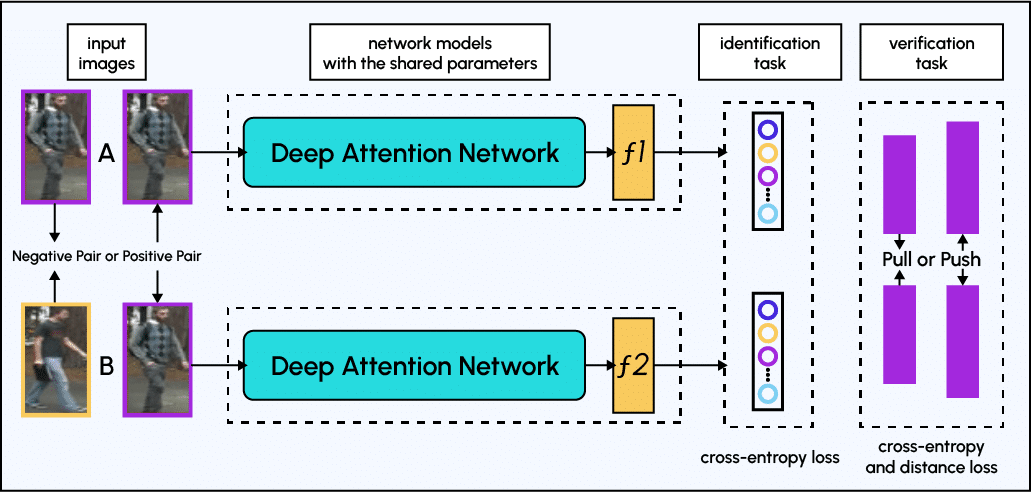
Attention-based models: attention-based models are deep learning architectures that use attention mechanisms to focus on the most informative regions of an image, such as the eyes, nose and mouth of a face. This can improve facial recognition performance, particularly when dealing with faces that are partially obscured or from different angles.
Lightweight architectures: lightweight architectures such as MobileNet, ShuffleNet and EfficientNet are designed to be less computationally intensive than traditional CNNs. This can make them more suitable for facial recognition on mobile devices and embedded systems with limited computing resources.

It’s important to note that these architectures are still being researched and improved, and that the best architecture for a specific use case depends on the characteristics of the dataset, the computational resources available and the specific requirements of the application.
Facial recognition and GDPR: Is it compatible?
Facial recognition technology raises major ethical and privacy issues, particularly when applied to Deep Learning. Indeed, the use of facial recognition raises questions about confidentiality and the possibility of data misuse. In addition, there are problems of bias in training data, which can lead to errors and bias towards specific groups.
For this reason, it is essential to have appropriate laws and policies in place to ensure the responsible use of this technology.
The General Data Protection Regulation (GDPR) is a European Union (EU) regulation that came into force on May 25, 2018. It replaces the 1995 European Data Protection Directive and strengthens European data protection laws. The GDPR regulates the collection, storage and use of personal data, including biometric data such as facial recognition.
Facial recognition technology, which uses algorithms to identify and match a person’s face, can process biometric data such as facial features, geometric patterns and even behavioral characteristics. This means that facial recognition technology falls within the scope of the GDPR, as it processes personal data.
Under the GDPR, organizations must obtain the explicit consent of individuals for the collection and processing of their personal data. Organizations must also inform individuals of the specific purposes for which their data will be used and how long it will be retained. They must also offer individuals the right to access, rectify or delete their personal data.
In addition, organizations using facial recognition technology must carry out a Data Protection Impact Assessment (DPIA) before deploying the technology. A DPIA (Data Protection Impact Assessment) is a process that helps organizations identify and mitigate the risks associated with processing personal data. This includes assessing the impact of the technology on the rights and freedoms of individuals, as well as evaluating the effectiveness of the measures put in place to protect personal data.








