
What is Snowflake?
Snowflake is a data warehouse designed entirely and natively for the cloud. It is available on Amazon Web Services and Microsoft Azure.
It is a columnar relational database with vectorized execution. In other words, it can handle the most demanding data analysis tasks.
Its architecture separates computation from storage, enabling scaling at any time, even when queries are running. Users pay only for the computing power they use.
Thanks to its adaptive optimization technology, Snowflake automatically achieves the best possible performance for each query. No need to manage configuration parameters manually.
What’s more, its multi-cluster, shared data architecture enables unlimited concurrency. This means that multiple computing clusters can operate simultaneously on the same data without degrading performance. The multi-cluster virtual data warehouse functionality automatically adapts performance according to concurrency requirements.
What are the main features?
Snowflake’s Data Warehouse Cloud supports most of the DDL and DML defined in SQL:1999 and the analytical extensions of SQL:2003. Connectivity includes connectors and drivers for Python, Spark, Node.js, Go, .Net, JDBC, ODBC, and the open-source extension dplyr-snowflakedb.
Virtual Warehouses can be controlled from the GUI or command lines. They can be created, resized, suspended, or deleted. Resizing can be performed while a query is running, without any downtime. This is particularly useful for speeding up queries.
The platform supports a wide variety of data and file formats. It is possible to load compressed files, or formats such as JSON, Avro, ORC, Parquet, and XML. S3 data sources and local files are also supported. Data can be securely shared with other Snowflake accounts.
Security features vary according to edition. The standard edition offers automatic encryption of all data, multi-factor authentication, and single sign-on.
The Enterprise Edition adds periodic re-keying of encrypted data. Finally, the Enterprise Edition for Sensitive Data adds HIPAA and PCI DSS compatibility. It’s also possible to choose where data is stored to comply with the RGPD more easily.
Snowflake architecture: How does it work?
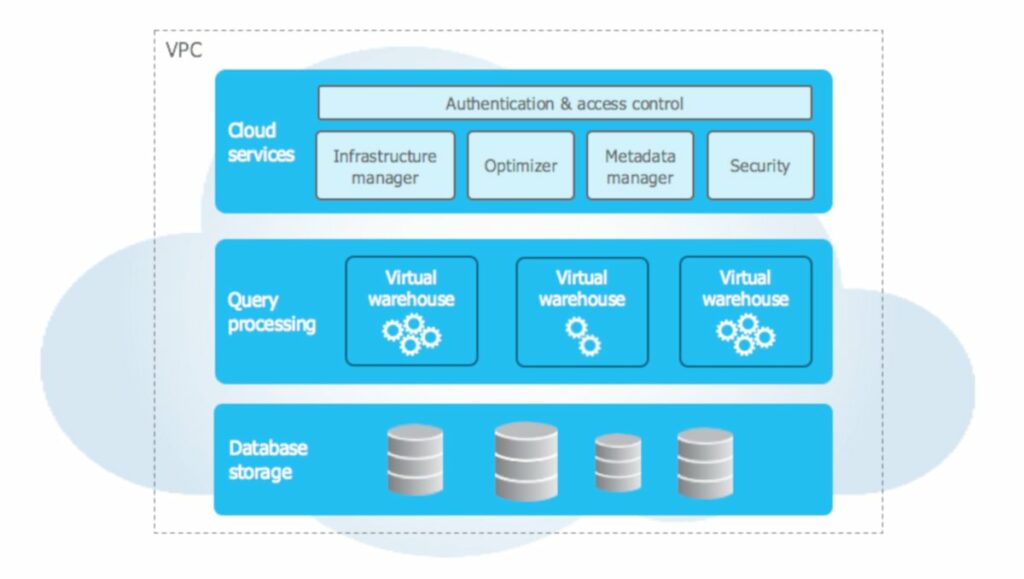
The Snowflake architecture is divided into virtual compute instances for computing, and a storage service for storing persistent data.
The central data repository is accessible from all the compute nodes in the data warehouse. Data processing is carried out by massively parallel computing clusters. Each cluster node stores a portion of the dataset locally.
When data is loaded onto Snowflake, it is reorganized in its compressed columnar format. Data can be accessed via SQL queries.
It’s a 100% Cloud platform, so running it on an on-premise or hosted private Cloud infrastructure is impossible. One advantage is that no installation or configuration is required, as the maintenance and tuning are handled by Snowflake.
Snowflake can be connected via its web interface, the SnowSQL CLI, ODBC, and JDBC drivers for applications such as Tableau, native connectors for programming languages, or third-party connectors for BI and ETL tools.
What are the advantages of Snowflake?
In the past, data was stored locally by companies. Data engineers and analysts exploited open-source software such as Apache Hadoop for data storage and analysis.
However, data engineers capable of developing and maintaining such a system are in short supply. Snowflake’s SaaS (software as a service) Data Warehouse addresses this shortage.
Users don’t need to worry about physical or virtual hardware and don’t need to install any software. The Snowflake teams handle updates and maintenance.
It’s also faster, easier to use, and more flexible than traditional data warehouses. What’s more, it’s not based on an existing software platform such as Hadoop.
It’s based on a brand-new SQL database engine, created by Snowflake with an architecture designed for the Cloud. So any software engineer with SQL knowledge can understand and use Snowflake.
What are the main Competitors and alternatives to Snowflake?
Snowflake’s main competitors include Amazon Redshift, Google BigQuery, and Microsoft Azure SQL Data Warehouse. These are the Data Warehouses offerings of the three leading Cloud providers.
Other rivals include Teradata, Oracle Exadata, MarkLogic, and SAP BW/4HANA. These solutions can be installed both in the cloud and on-site.
What sets Snowflake apart from its competitors?
At some point in the past, the cost of purchasing a cable TV service meant that infrastructure and content were included in a single package. Today, these elements are separate, and users have more control over what they use and how they pay for it.
Snowflake’s architecture allows similar flexibility with Big Data. This cloud computing tool dissociates storage and compute functions, meaning that companies with high storage demands less need for CPU cycles, or vice versa, don’t have to pay for an integrated package that forces them to pay for both. This point of differentiation is one of the factors that have enabled its co-founders (Marcin Zukowski, Benoît Dageville, and Thierry Cruanes) to save several organizations millions of dollars, while valuing their start-ups at several tens of billions of dollars today since raising funds in February 2020.
Users can increase or reduce capacity as needed, and pay Snowflake only for the workload they require. Storage is billed in terabytes stored per month. Computing is billed by the second. In fact, the Snowflake architecture consists of three layers, each independently scalable: storage, computing, and services.
Data storage layer
The database storage layer contains all data loaded into Snowflake, including structured and semi-structured data. Snowflake offers automatic management of storage tasks, from data organization to structuring and compression. What’s more, the operation of this data storage layer is entirely independent compared to the compute layer.
Calculation layer
The compute layer comprises virtual warehouses that perform the data processing tasks required for queries. Each virtual warehouse (or cluster) can access all the data in the storage layer, and then operate independently, so that the warehouses do not share or compete for compute resources. This enables automatic scaling without interruption, meaning that compute resources may or may not change during query execution, and therefore do not need to be redistributed or rebalanced in the data storage layer.
Cloud services layer
The cloud services layer uses ANSI SQL and coordinates the entire system. It eliminates the need for manual management and tuning of the data warehouse. Services in this layer include authentication, infrastructure, metadata management, query analysis, and optimization, as well as access control.
How do you learn to use it?
Snowflake offers many advantages, but it can be complex to use. With this in mind, the company offers several tutorials and videos to help you master the platform. Some are general and aimed at beginners, while others enable you to discover specific functionalities in greater detail.
You can also opt for Snowflake training. DataScientest offers you the opportunity to learn how to master the Cloud Data Warehouse through our Machine Learning Engineer training and our Data Engineer training.
You know all about Snowflake. Check out our complete blog post on Docker, another key Big Data tool, and our blog post on Machine Learning.








