
Im Oktober 2018 hat der Zweig für künstliche Intelligenz von Google (Google AI) ein vorprogrammiertes Deep-Learning-Modell namens BERT veröffentlicht. Dieses Modell kann mehrere NLP-Probleme lösen.
Natural Language Processing ist ein Teilbereich des Machine Learning, der Computerprogrammen die Fähigkeit verleihen soll, menschliche Sprache zu verstehen und zu verarbeiten.
Seit seiner Veröffentlichung hat BERT die Aufmerksamkeit der Data-Science-Community auf sich gezogen, da es „State-of-the-Art“ Ergebnisse liefert. BERT liefert derzeit die besten Ergebnisse für einen Großteil der NLP-Aufgaben. Google hat sogar behauptet, dass das Modell bei einigen Aufgaben die menschliche Leistung übertrifft, was ein großer Schritt für jeden Machine-Learning-Algorithmus ist.
Die Welt vor BERT:
Um zu verstehen, was BERT ist und was die innovative Idee hinter diesem Modell ist, werden wir uns auf eine typische NLP-Aufgabe stützen. Nehmen wir den folgenden Satz:
„Die Person geht in den Supermarkt und kauft eine ____ mit Schuhen. „
Hier ist das Ziel klar. Der Satz soll Satz vervollständigt werden. Die Antwort ist daher für einen Menschen offensichtlich, aber für einen Algorithmus jedoch weniger.
Pre-BERT-Modelle hätten diese Textsequenz von links nach rechts oder in Kombination von links nach rechts und von rechts nach links betrachtet. Dieser unidirektionale Ansatz funktioniert gut, um Sätze zu erstellen. Wir können das nächste Wort vorhersagen, es der Sequenz hinzufügen und dann das nächste Wort vorhersagen, bis wir einen vollständigen Satz erhalten. Hier würden pre-BERT-Modelle etwa 70% der Zeit das Wort (Paar) und den Rest der Zeit Wörter wie „Caddie“ oder „Koffer“ liefern.
BERT geht aber nicht auf diese Weise vor. BERT steht für Bidirectional Encoder Representations from Transformers. Dieses Modell arbeitet bidirektional, was zu einem besseren Verständnis des Textes führt.
Die BERT-Methode:
Nehmen wir dieselbe Aufgabe noch einmal und schauen wir uns an, was BERT macht. Anstatt das nächste Wort in einem Satz vorherzusagen, verwendet BERT eine neue Technik namens Masked LM (MLM). Er maskiert zufällig Wörter im Satz und versucht dann, sie vorherzusagen. Unter “Maskieren” versteht man, dass das Modell in beiden Richtungen schaut und den kompletten Kontext des Satzes (links und rechts) verwendet, um das maskierte Wort vorherzusagen. Im Gegensatz zu früheren Sprachmodellen berücksichtigt es das vorhergehende und das nachfolgende Wort gleichzeitig. Den bisherigen Modellen fehlte dieser „simultane“ Ansatz.
Wie funktioniert es technisch?
BERT ist ein Modell des Typs Transformer. Um zu funktionieren, führt ein Transformer eine kleine und konstante Anzahl von Schritten aus. Bei jedem Schritt wendet es einen Aufmerksamkeitsmechanismus an, um die Beziehungen zwischen den Wörtern im Satz zu verstehen, unabhängig von ihren jeweiligen Positionen. Nehmen wir ein einfaches Beispiel:
„Hast du eine neue Maus für deinen Computer? „
Um die Bedeutung des Wortes „Maus“, das Objekt und nicht das Tier, zu bestimmen, wird der Transformator auf das Wort „Computer“ achten und darauf basierend eine Entscheidung treffen.
Um dies zu ermöglichen, basiert sich BERT daher auf der Architektur von Transformern, d. h. bestehend aus einem Encoder, der den Text liest, und einem Decoder, der eine Vorhersage macht. BERT beschränkt sich auf einen Encoder, da sein Ziel darin besteht, ein Modell zur Darstellung von Sprache zu erstellen, das dann für NLP-Aufgaben verwendet werden kann. (Es ermöglicht das Verstehen von Sprache).
Wie wird es verwendet?
Vor der Verwendung von BERT ist es entscheidend, die folgenden Daten vorzubereiten:
- Tokenisierung von Wörtern und Hinzufügen von Satzanfangs- und Satzende-Tokens
- Marker an jedem Satz hinzugefügt, um sie zu unterscheiden
Ein Positionsmarker wird zu jedem Token (Wort) hinzugefügt, um seine Position anzuzeigen.
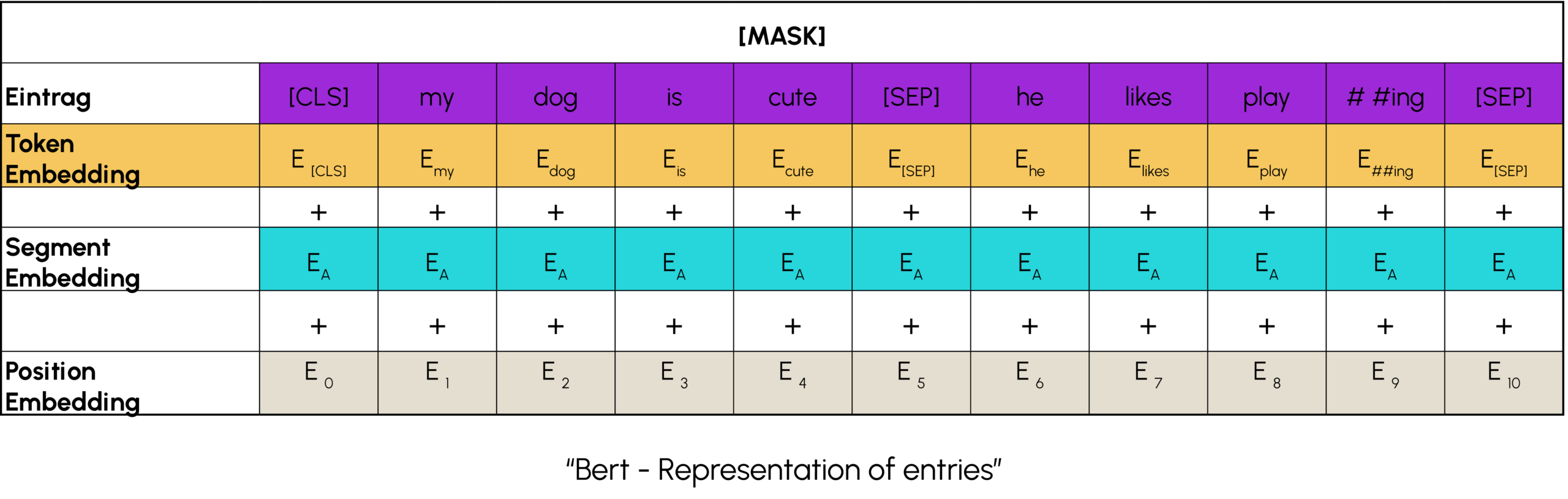
Danach muss man sein BERT-Modell auswählen. Es gibt verschiedene Typen in unterschiedlichen Größen. Es liegt am Benutzer, die Komplexität zu wählen, die für seine Aufgabe geeignet ist. Schließlich musst Du das Modell noch importieren und in Deine Architektur einbauen. Wenn Du diese Schritte erledigt hast, musst Du nur noch die Vorhersagen machen!
BERT ist ein sehr mächtiges Sprachrepräsentationsmodell, das einen Meilenstein in der maschinellen Sprachverarbeitung darstellt. Es hat unsere Fähigkeit, Transfer Learning in NLP zu betreiben, erheblich erweitert. Mit BERT kannst du zum Beispiel Tweets nach der Stimmung, die sie hervorrufen, klassifizieren oder einen virtuellen Assistenten erstellen, der Fragen intelligent beantworten kann.
Um besser zu verstehen, wie BERT und Transformers funktionieren, oder um Deep Learning und NLP zu entdecken und zu Deinem Beruf zu machen, nimm an unseren DataScientest Weiterbildungen teil.







