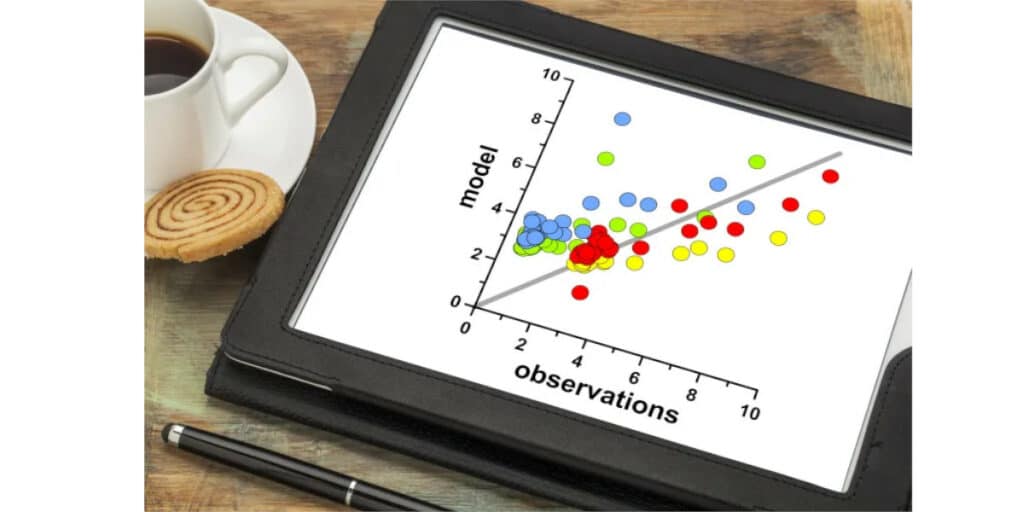
Die Visualisierung von Daten in der Welt der Datenwissenschaft ist heutzutage das Herzstück der Machine-Learning-Pipeline. Die Datenvisualisierung ist somit einer der Schritte in der Datenwissenschaft, der direkt nach dem Sammeln, Bereinigen und Normalisieren der Daten stattfindet. Eine der am häufigsten verwendeten Grafiken ist heutzutage der Scatter-Plot. Mithilfe von Scatterplots können wir Daten analysieren und die Wechselwirkungen zwischen Variablen erkennen.
Was genau ist ein Scatter Plot?
Scatterplots, auch Scattergram, Scattergraph oder Scatterchart genannt, sind eine Art Punktwolkendiagramm, das darstellt, wie eine Variable von einer anderen beeinflusst wird. Die vertikale Achse oder Ordinatenachse wird verwendet, um eine der Variablen darzustellen, und eine horizontale Achse oder Abszissenachse für die andere Variable.
Im Gegensatz zu Pie-Charts, die eher für kategoriale Variablen geeignet sind, werden Scatter-Plots häufig verwendet, um eine Korrelation zwischen quantitativen Variablen darzustellen, die miteinander verbunden zu sein scheinen. Beispielsweise kann die Durchschnittstemperatur eines Tages die Anzahl der in einem Supermarkt verkauften Flaschen mit kaltem Wasser beeinflussen.
So kann man durch die Darstellung dieser Punkte ableiten, ob die Beziehung zwischen der Durchschnittstemperatur eines Tages und der Anzahl der verkauften Flaschen frischen Wassers eher linear oder nicht linear, stark oder schwach oder positiv oder negativ ist.
Welche Anwendungen gibt es für den Scatter Plot?
1. Analyse der Beziehungen zwischen Variablen
- Starke / schwache Beziehung
Die Stärke eines Scatter-Plots wird anhand der Streuung seiner Punkte beurteilt. Wenn die Punkte sehr breit gestreut sind, ist der Zusammenhang zwischen den Variablen schwach. Wenn die Punkte um eine Gerade herum konzentriert sind, ist der Zusammenhang zwischen den Variablen stark.
- Positive / negative Beziehung
Eine wichtige Komponente einer Punktwolke ist die Richtung der Beziehung zwischen den Variablen. Man spricht von einer positiven Korrelation, wenn die x- und y-Koordinaten gleichzeitig ansteigen. Wenn du dir das Alter eines Kindes und seine Körpergröße ansiehst, wirst du feststellen, dass das Kind mit zunehmendem Alter auch größer wird. Es handelt sich um eine positive Beziehung zwischen den Variablen.
Im umgekehrten Fall, wenn die Werte auf der x-Achse steigen und die Werte auf der y-Achse sinken (oder umgekehrt), dann kann man daraus schließen, dass die Beziehung negativ ist. Wenn du dir z. B. das Alter eines Autos und seinen Wert ansiehst, wirst du feststellen, dass das Auto mit zunehmendem Alter an Wert verliert. Es handelt sich hierbei um eine negative Korrelation.
- Lineare / nichtlineare Beziehung
Die Form der Punktwolke lässt uns auf die Linearität der Daten schließen. Wenn die Punktwolke einer geraden Linie ähnelt, ist die Beziehung linear. Daraus lässt sich ableiten, dass eine Variable ungefähr gleich schnell ansteigt, wenn sich die andere Variable um eine Einheit ändert. Wenn das Scatterplot die Form einer Kurve oder einer anderen Form hat, wird die Beziehung zwischen den Variablen als nichtlinear bezeichnet.
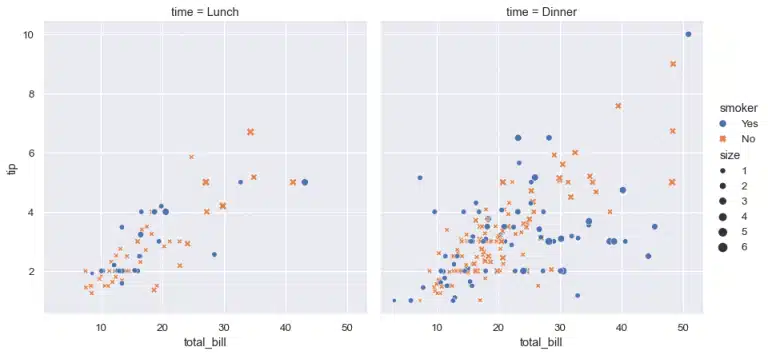
2. Cluster und Ausreißer identifizieren
Lass uns zunächst Cluster und Outlier definieren.
- Cluster
Ein Cluster in der Data Science ist eine Unterpopulation eines größeren Datensatzes, in dem jeder Datenpunkt näher an einem Zentroid (Zentrum eines Clusters) liegt als an den Zentroiden im Datensatz. Clustering ist nach wie vor eine der am häufigsten verwendeten Methoden des unüberwachten Lernens. Es kann für eine Vielzahl von Anwendungen eingesetzt werden, u. a. für die Segmentierung von Kunden, die Analyse sozialer Netzwerke oder Empfehlungssysteme.
- Outlier
Ein Ausreißer in der Datenwissenschaft ist eine Beobachtung, die sich von anderen Beobachtungen unterscheidet. Bei der Erhebung von Daten kann es vorkommen, dass der Datensatz Extremwerte enthält, die außerhalb des erwarteten Datenbereichs liegen. Diese Werte werden als Ausreißer bezeichnet.
Im Gegensatz zu den Pie-Charts, die uns nicht erlauben, Cluster und Ausreißer zu identifizieren, erlauben uns die Scatter-Plots, unsere Daten besser zu analysieren, um das richtige Preprocessing zu starten und den am besten geeigneten Machine-Learning-Algorithmus für unser Problem auszuwählen.
3. Lineare Regression anwenden
Regressionsmodelle untersuchen die Beziehung zwischen einer abhängigen Variablen (Ziel) und einer oder mehreren unabhängigen Variablen (Prädiktor). Hier sind einige der häufigsten Regressionsmodelle:
- Lineare Regression: Die lineare Regression hat die Form einer geraden Linie und stellt eine lineare Beziehung zwischen dem Ziel (Y) und dem Prädiktor (X) her.
- Polynomiale Regression: Die polynomiale Regression hat die Form einer Kurve und stellt eine nichtlineare Beziehung zwischen dem Ziel (Y) und dem Prädiktor (X) her.
Trotz ihrer Einfachheit ist die lineare Regression ein unglaublich mächtiges Werkzeug zur Analyse von Daten, die eine lineare Form haben. Dieser Algorithmus gehört zur Familie der überwachten Machine-Learning-Algorithmen.
Eine lineare Regression hat die Gleichung y = mx+b. Die Variable x wird als unabhängige oder erklärende Variable bezeichnet. Die Variable y wird als die abhängige oder zu erklärende Variable bezeichnet.
Die Scatter-Plots können leicht durch eine einfache lineare Regression ergänzt werden, indem unsere Parameter m und b berechnet werden, um eine Regressionsgerade durch unsere Daten zu legen. Diese Berechnung der Parameter erfolgt über die folgenden Beziehungen:
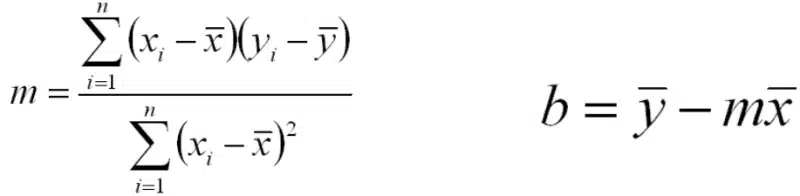
Die Gleichung für die lineare Regression stellt sicher, dass der Abstand zwischen jedem Datenpunkt und der Regressionsgeraden minimiert wird. Allerdings musst du die folgenden Punkte überprüfen:
- Die Beziehung zwischen den Daten sollte linear sein: Die Punktwolke sollte eine gerade Linie bilden, anstatt einer Kurve oder einer anderen Form.
- Die Additivitätshypothese muss überprüft werden. Das bedeutet, dass die Änderung in einem Merkmal der Zielvariable nicht von den Werten der anderen Merkmale abhängt. Nehmen wir als Beispiel ein Modell zur Prognose des Umsatzes eines Unternehmens mit zwei Merkmalen: die Anzahl der verkauften Stifte und die Anzahl der verkauften Hefte. Wenn das Unternehmen mehr Stifte verkauft, steigt der Umsatz mit Stiften, und das ist unabhängig von der Anzahl der verkauften Hefte. Wenn die Kunden, die Stifte kaufen, jedoch keine Hefte mehr kaufen, ist die Additivitätshypothese nicht mehr erfüllt, da in diesem Fall der mit den Heften erzielte Umsatz vom Kauf der Stifte abhängt.
- Die Features dürfen nicht korreliert sein. Das heißt, dass die Beobachtungen der Zielvariable nicht mit den vorherigen Beobachtungen zusammenhängen und die folgenden nicht beeinflussen.
Fehler sind unabhängig und identisch nach der Normalverteilung verteilt.
Welche Probleme gibt es mit Scatter Plots?
1. Unkorrelierte Daten
In dem Fall, dass wir keine Korrelationen oder Verbindungen zwischen unseren Daten haben, sind die Datenpunkte überall verstreut und es kann keine Interpretation abgeleitet werden. Mit anderen Worten: Die Tatsache, dass wir den Wert einer Variablen kennen, gibt uns keine Vorstellung davon, was der Wert der anderen Variablen sein könnte. Wenn wir einen Scatterplot von zwei Variablen haben, deren Korrelation null ist, wird das Diagramm keinen klaren Trend aufweisen. Zum Beispiel ist die Korrelation zwischen der Menge an Kaffee, die eine Person konsumiert, und ihrem IQ-Wert gleich null. Mit anderen Worten: Die Tatsache, dass wir wissen, wie viel Kaffee eine Person trinkt, sagt nichts über ihren IQ-Wert aus.
2. Große Datenmenge
Bei großen Datensätzen können sich die Punkte des Scatterplots überlappen und sich gegenseitig verdecken. Dies wird als Overplotting bezeichnet und verdeckt die Trends und Beziehungen zwischen unseren beiden Variablen, was die Analyse erschwert. Es gibt also verschiedene Lösungen für dieses Problem:
- Wenn du die Füllfarbe der Punkte, die unsere Daten repräsentieren, entfernst oder ihre Größe reduzierst, lässt sich der Plot leichter analysieren und zeigt, wie sich die Punkte überlappen.
- Eine andere einfache Technik, die sich oft als nützlich erweist, besteht darin, die Form von Datenpunkten, die genug Platz einnehmen, wie z. B. Kreise oder Quadrate, in eine Form zu ändern, die nicht so viel Platz einnimmt, wie z. B. Kreuze.
- Die Anzahl der Beobachtungen zu reduzieren, wird ebenfalls oft verwendet. Hierfür gibt es zwei Methoden:
- Daten filtern: Hier geht es darum, nicht benötigte Daten zu löschen, um die Anzahl der Daten zu reduzieren und die Lesbarkeit zu verbessern.
- Die Daten auf mehrere Graphen zu verteilen, kann auch eine gute Lösung sein, wenn du keine Informationen verlieren willst.
Abschließend lässt sich sagen, dass Pie-Charts eine hervorragende Alternative im Fall von kategorialen Variablen sein können. So gibt es verschiedene Bibliotheken für die Analyse und Visualisierung von Daten mit Python, z. B. Matplotlib, Seaborn oder auch Plotly !
Bist du bereit, deinen Scatter Plot zu zeichnen? Erfahre mehr über die Analyse und Visualisierung von Scatter Plots sowie weitere Grafiken zur Datenvisualisierung auf DataScientest.







