
Für den Menschen ist das visuelle Verständnis oft einfacher als das Textverständnis, da unser Gehirn visuelle Informationen schneller und effizienter verarbeiten kann. Aus diesem Grund konnten wir das Aufkommen von grafischen Datenbanken beobachten, die die Sprache Cypher anstelle des traditionellen SQL verwenden.
Visuelle Datenbanken bieten einen viel schnelleren und intuitiveren Weg, Daten zu modellieren und abzufragen. Die Sprache wurde größtenteils von Andrés Taylor, einem Mitarbeiter, der an Neo4j arbeitete, erfunden. Bei der Entwicklung der Sprache wurde die Stärke und Fähigkeit von SQL im Auge behalten, während die Benutzer die Ergebnisse ihrer Abfragen visuell sehen können.
Cypher ist eine grafische Sprache, die aufgrund ihrer Ähnlichkeit mit anderen Sprachen und ihrer Intuitivität sehr leicht zu erlernen ist. Für ein Unternehmen ist es wichtig, das richtige Werkzeug zu wählen, das sowohl einfach zu bedienen als auch leistungsstark ist, um den Anforderungen bei der Weiterentwicklung von Anwendungen gerecht zu werden. Aus diesem Grund wird Neo4j von großen Unternehmen wie Michelin, NASA, Crédit Agricole und Volvo eingesetzt. Erfahre in diesem Artikel mehr über die Stärke dieser Sprache.
💡Auch interessant:
| MySQL Relationale Datenbanksoftware |
| SQL Tutorial |
| Apache Cassandra noSQL BDD |
| SQL Joins |
| SQL Count Tutorial |
Wie funktioniert Cypher ?
Cypher wurde speziell für die Arbeit mit Graphendatenbanken entwickelt. Das Vokabular und die verwendete Syntax sind optimiert, um den Benutzern zu helfen, zu verstehen, wie ihre Abfrage funktioniert und wie die Ergebnisse erzeugt werden.
Wie die SQL-Sprache sind auch Entitäten und Beziehungen in Cypher vorhanden, aber in einer anderen Form: Entitäten werden durch Knoten dargestellt, während Beziehungen die Form von Kanten haben. Indem diese Elemente grafisch dargestellt werden, können die Nutzer die Beziehungen und Verbindungen zwischen den Elementen eines komplexen Systems visualisieren. Dies macht die Sprache sehr intuitiv für Nutzer, um die Datenstruktur von Graphen zu verstehen und Cypher-Abfragen effizienter zu formulieren.

Was sind die Unterschiede zwischen Cypher und SQL?
SQL gibt es schon lange, es ist eine mächtige Sprache, aber es gibt einige Dinge, die man besser mit Cypher machen kann. Wir werden uns nun den Unterschied zwischen SQL-Abfragen und Cypher ansehen. Die Syntax von Cypher ähnelt der einer klassischen SQL-Abfragesprache, unterscheidet sich aber in einigen Punkten. Wir nehmen als Beispiel eine Abfrage, die als Ergebnis nur Personen zurückgibt, die nach 1998 geboren wurden.
SQL-Abfrage:
SELECT person.name
FROM person
WHERE personne.birthdate > 1998;
Cypher Abfrage:
MATCH (person:Person)
WHERE person.birthdate > 1998
RETURN person.name;
Wie du sehen kannst, beginnen Cypher-Abfragen immer mit dem Schlüsselwort „MATCH“ anstelle von „SELECT“ in der SQL-Sprache, gefolgt von einer „WHERE“-Klausel, um die Ergebnisse zu filtern, und schließlich „RETURN“, um die zurückzugebenden Daten zu spezifizieren.
Der Unterschied zwischen den beiden Sprachen für Datenbanken zeigt sich in den Beziehungen zwischen den Entitäten.
In Cypher ist eine Beziehung eine Kante, die zwei Knoten in einem Graphen verbindet. Beziehungen werden durch Bindestriche ( – ) zwischen den Knoten dargestellt. Jede Beziehung kann eine Richtung haben, die durch einen Pfeil ( -> oder <- ) dargestellt wird. Dieser gibt die Richtung an, in der die Beziehung durchlaufen werden kann. Zum Beispiel kann die Beziehung „LOVES“ dargestellt werden durch:
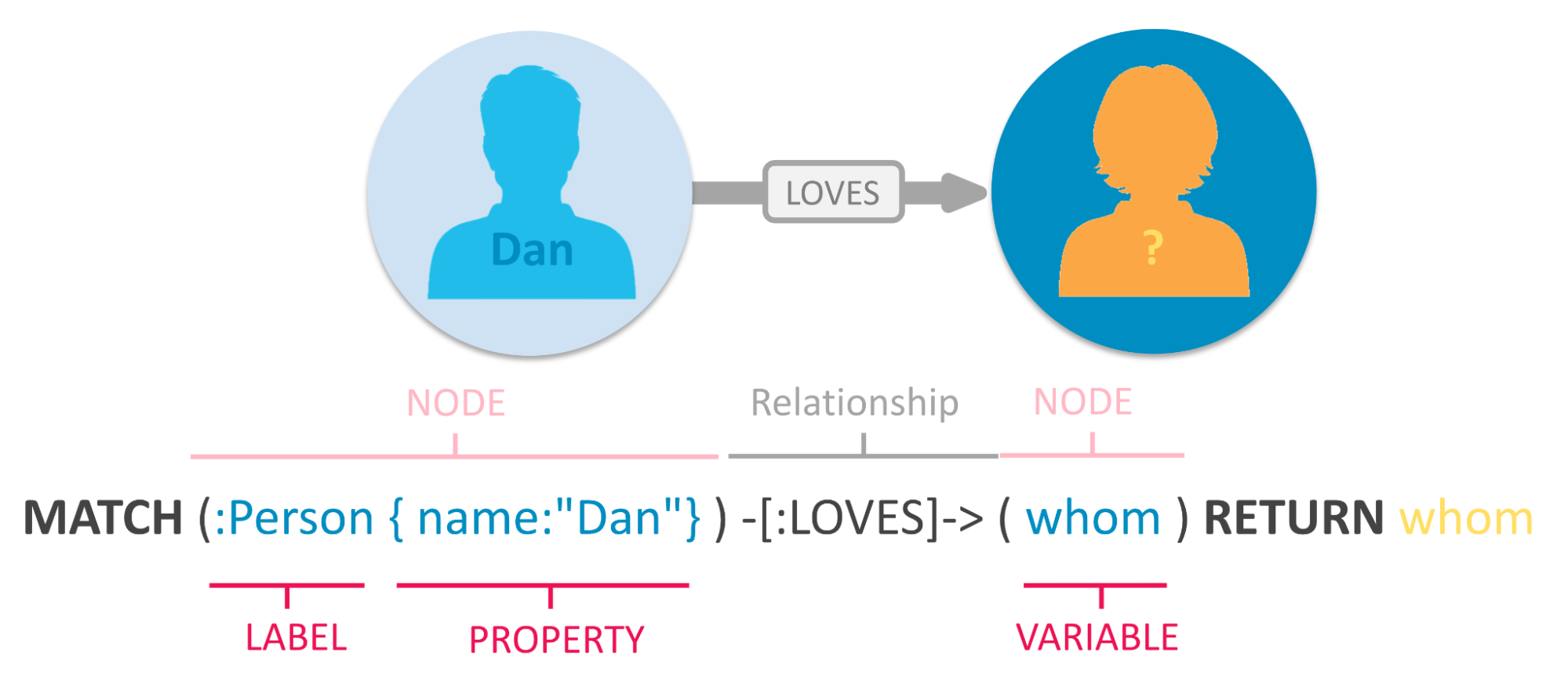
Wir können sehen, dass es eine Beziehung „LOVES“ gibt, die von Knoten 1 ausgeht und auf Knoten 2 zeigt. Es ist auch möglich, Beziehungen oder Knoten Eigenschaften hinzuzufügen, um zusätzliche Informationen zu speichern. Eigenschaften werden durch geschweifte Klammern dargestellt und können nach der Beziehung hinzugefügt werden. In diesem Beispiel suchen wir nach Personen, die von einer Person mit dem Namen „Dan“ geliebt werden.
Mithilfe der Beziehungen in Cypher ist es einfacher und intuitiver, Abfragen an die Datenbank zu stellen. Lass uns ein paar Abfragen schreiben, um eine Datenbank zu füttern. Anders als bei SQL ist es nicht notwendig, das Schema vorher zu definieren. Es sind unsere Abfragen zum Einfügen von Daten, die die Architektur unserer Datenbank definieren. Zuerst erstellen wir einige Knoten, die Personen in unserer Datenbank repräsentieren:
CREATE (:Person {name: 'Daniel', age: 40})
CREATE (:Person {name: 'Julia', age: 25})
CREATE (:Person {name: Bob'', age: 35})
Nachdem wir diese Knoten zu unserer Datenbank hinzugefügt haben, die eine Person mit einem Namen und einem Alter darstellt, können wir Beziehungen zwischen ihnen herstellen. Im Gegensatz zu SQL können wir unsere Knoten sehr einfach miteinander verknüpfen. Wenn wir zum Beispiel wollen, dass Daniel in Julia verliebt und mit Bob befreundet ist, können wir das mit Cypher mit den folgenden Abfragen erreichen:
MATCH (daniel:Person {name: 'Daniel'}), (julia:Person {name: 'Julia'})
CREATE (daniel)-[:LOVES]->(julia)
MATCH (daniel:Person {name: 'Daniel'}), (bob:Person {name: 'Bob'})
CREATE (daniel)-[:FRIEND]->(bob)
Im Gegensatz dazu müssten wir mit SQL zuerst drei Entitäten (Person, Friendship und Love) erstellen und dann die Werte in die Tabellen einfügen, um sie zu verbinden.
Sobald die Daten hinzugefügt sind, können wir sehen, dass es einfacher ist, Abfragen mit Cypher als mit SQL zu machen. Wenn wir Daniels Freunde sehen wollen, ist es möglich, dies mit den folgenden Befehlen für beide Sprachen zu tun:
Requête SQL :
SELECT p.name
FROM Person p
JOIN Friendship f ON p.id = f.id
WHERE f.name = ‘Daniel’;
Requête Cypher :
MATCH (daniel:Person {name: 'Daniel'})-[:FRIEND]->(friend)
RETURN friend.name
Wir können sehen, dass Cypher-Abfragen viel kürzer sind als SQL-Anweisungen und deutlich einfacher zu verstehen.
Fazit
Cypher ist eine leistungsfähige Sprache, die es Entwicklern ermöglicht, komplexe Abfragen in graphenorientierten Datenbanken durchzuführen. Seine klare und prägnante Syntax macht es auch zu einer ausgezeichneten Wahl für Benutzer, die mit grafischen Datenbanken nicht vertraut sind und lernen möchten, mit ihnen zu interagieren. Die Beherrschung von Neo4j und Cypher ist zusammen mit SQL, MongoDB, Elasticsearch und Cassandra Teil des Datenbankmoduls des Data Engineer-Kurses von DataScientest.







