Wenn du dich für Machine-Learning-Algorithmen interessierst, hast du bestimmt schon einmal irgendwo die Wörter „Boosting“ oder „Boost“ gesehen. Man findet sie in einer Vielzahl von Algorithmus-Wettbewerben und sie erzielen oft sehr gute Ergebnisse. Aber was genau ist Boosting?
In diesem Artikel lernst du den Unterschied zwischen einem Boosting- und einem Bagging-Algorithmus kennen. Danach wirst du die Funktionsweise der Boosting-Algorithmen AdaBoost, Gradient Boost und XGBoost verstehen.
Bagging, Boosting, was genau ist das?
Bagging
Um zu definieren, was Boosting ist, sollte zunächst definiert werden, was Bagging ist.
Bagging ist eine Technik in der künstlichen Intelligenz, bei der eine große Anzahl von Algorithmen mit geringer Einzelleistung zu einem viel effizienteren Algorithmus zusammengestellt wird. Die Algorithmen mit geringer Leistung werden als „weak learners“ bezeichnet und das resultierende Ergebnis als „strong learner“.
Die Idee hinter diesem Algorithmus ist, dass viele kleine Algorithmen effizienter sein können als ein großer Algorithmus.

Einfach gesagt, kann man sich diesen Prozess gedanklich als einen großen Wald aus kleinen Sträuchern verschiedener Arten vorstellen. Durch die Vielfalt der Bäume, aus denen der Wald besteht, ist er witterungsbeständiger als eine große, hundertjährige Eiche.
Die „weak leaners“ können unterschiedlicher Natur sein und unterschiedliche Leistungen erbringen, aber sie müssen voneinander unabhängig sein.
Die Zusammenstellung der „weak learners“ (Büsche) zu „strong learners“ (Wald) erfolgt durch Abstimmung. Das heißt, jeder „weak learner“ gibt eine Antwort (eine Stimme) ab und die Vorhersage des „strong learners“ ist der Durchschnitt aller abgegebenen Antworten.
Wenn du dich für Bagging interessierst, kannst du dir diesen Artikel ansehen, der die Funktionsweise des berühmtesten Bagging-Algorithmus vorstellt: den Random Forest.
Boosting
Die Boosting-Algorithmen basieren auf demselben Prinzip wie die Bagging-Algorithmen. Der Unterschied zeigt sich bei der Erstellung von „weak learners“.
Beim Boosting sind die Algorithmen nicht mehr unabhängig. Stattdessen wird jeder „weak learner“ geschult, um die Fehler der vorherigen „weak learner“ zu korrigieren.
Wenn wir also das Bild des Waldes aufgreifen, wurde hier jeder Strauch sorgfältig gepflanzt, um den Wald wetterfester zu machen.
In diesem Artikel werden wir die Funktionsweise der Algorithmen Adaboost, Gradient Boosting und XGBoost. Diese Algorithmen sind wahrscheinlich die bekanntesten Boosting-Algorithmen.
Was ist Adaboost?
Adaboost wurde erstmals von Yoav Freund und Robert Schapire verwendet und gewann 2003 den Gödel-Preis. Adaboost verwendet Entscheidungsbäume, deren Funktionsweise du in diesem Artikel detailliert nachlesen kannst.
Die „weak learners“ in AdaBoost sind normalerweise Entscheidungsbäume mit nur zwei Zweigen und zwei Blättern (auch als Stämme bezeichnet), aber es können auch andere Arten von Klassifizierern verwendet werden.
Hier sind die Schritte zum Aufbau des ersten „weak learners“, den wir w1 nennen werden:
- Jeder Zeile des Datasets wird die gleiche Gewichtung zugewiesen.
- Man trainiert w1 so, dass die Anzahl der richtigen Antworten maximiert wird.
- Man gibt w1 eine Note aufgrund seiner Leistung
Die Idee hinter der Benotung ist, dass wir wollen, dass ein guter „weak learner“ mehr Gehör findet als ein schlechter „weak learner“.
Die Bewertung wird uns helfen, bei der Endabstimmung zu entscheiden, welche Bedeutung wir welchem „weak learner“ beimessen sollen.
Außerdem möchten wir, dass die nächsten „weak learners“ die Fehler des vorherigen korrigieren können. Um dies zu erreichen, werden wir die Gewichtung der Zeilen, bei denen w1 falsch lag, erhöhen und die Gewichtung der Zeilen, bei denen w1 richtig lag, verringern.
Hier sind also die Schritte zum Aufbau der anderen „weak learners“:
- Die Gewichtung der Zeilen wird entsprechend den Fehlern des letzten „weak learners“ geändert.
- Workout eines „weak learner“, um die Anzahl der richtigen Antworten auf den Zeilen mit hohem Gewicht zu maximieren
- Man gibt diesem „weak learner“ je nach Leistung eine Note
Im Gegensatz zu w1 werden die nächsten „weak learners“ die den Zeilen zugewiesenen Gewichte berücksichtigen. Je höher die Gewichtung einer Zeile ist, desto wichtiger ist es, dass der „weak learner“ diese Zeile richtig einordnet und umgekehrt.
Wie bei w1 geben wir diesen „weak learners“ eine Note, die ihre Wichtigkeit bestimmt. Beachte, dass die Note von den Ergebnissen des „weak learner“ abhängt, indem die Gewichtung der Zeilen berücksichtigt wird.
Nachdem wir jeden „weak learner“ erstellt haben, ändern wir die Gewichtung der Zeilen. Jeder „weak learner“ korrigiert also die Fehler, die von seinen Vorgängern gemacht wurden, und hat eine Bewertung, die seine Ergebnisse widerspiegelt.
Um die Vorhersage von Adaboost zu einer Beobachtung abzufragen, musst du jeden „weak learner“ befragen und jede Antwort nach der Bewertung, die sie erhalten haben, gewichten. Die Vorhersage des „strong learner“ ist der Durchschnitt aller Antworten der „weak learner“.
Was ist Gradient Boosting?
Der Gradient Boosting-Algorithmus hat viele Gemeinsamkeiten mit Adaboost. Genau wie bei Adaboost handelt es sich um eine Reihe von „weak learners“, die nacheinander erstellt werden und einen „strong learner“ bilden. Darüber hinaus wird jeder „weak learner“ trainiert, um die Fehler der vorherigen „weak learners“ zu korrigieren. Dennoch haben im Gegensatz zu Adaboost alle „weak learners“ im Abstimmungssystem das gleiche Gewicht, unabhängig von ihrer Leistung.
Wir werden nun kurz auf die Funktionsweise des Algorithmus eingehen:
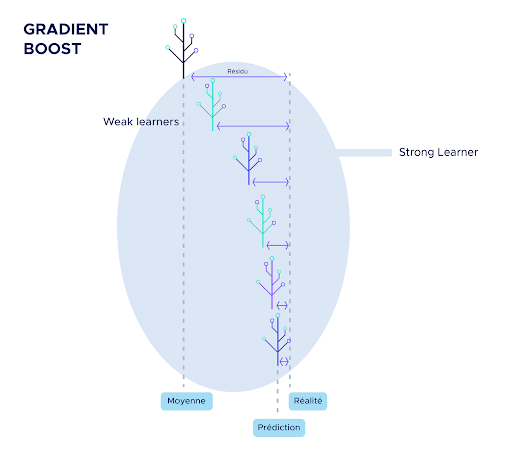
Der erste „weak learner“ (w1) ist sehr grundlegend, er ist einfach der Durchschnitt der Beobachtungen. Er ist also nicht sehr effizient, aber er wird als Grundlage für den Rest des Algorithmus dienen.
Anschließend berechnen wir die Abweichung zwischen diesem Mittelwert und der Realität, die wir als erstes Residuum bezeichnen. Im Allgemeinen bezeichnen wir hier die Abweichung zwischen der Vorhersage des Algorithmus, der gerade erstellt wird, und der Realität als Residuum.
Das Besondere an Gradient Boosting ist, dass es versucht, in jedem Schritt nicht die Daten selbst, sondern die Residuen vorherzusagen.
So wird der zweite „weak learner“ trainiert, um den ersten Rest vorherzusagen.
Die Vorhersagen des zweiten weak learners werden dann mit einem Faktor kleiner als 1 multipliziert.
Die Idee hinter der Multiplikation ist, dass viele kleine Schritte genauer sind als wenige große Schritte. Die Multiplikation verringert also die Größe der „Schritte“, um die Genauigkeit zu erhöhen. Das Ziel ist es, die Vorhersagen des Mittelwertmodells nach und nach von der Realität „wegzuziehen“.
Von diesem Zeitpunkt an folgt die Erstellung von Weak Learners immer dem gleichen Muster:
- Aus den letzten Vorhersagen werden die neuen Residuen (Abweichung zwischen Realität und Vorhersage) berechnet.
- Workout des neuen „weak learner“, um diese Residuen vorherzusagen
- Die Vorhersagen dieses „weak learner“ werden mit einem Faktor kleiner als 1 multipliziert.
- Man erhält neue Vorhersagen, die oft etwas besser sind als die vorherigen.
Um die Gradient Boosting-Vorhersage zu einer Beobachtung abzufragen, musst du einfach jeden „weak learner“ befragen. Die Vorhersage des „strong learner“ wird die Summe aller Antworten der „weak learner“ sein.
Was ist XGBoost?
XGBoost ist eigentlich eine besondere Version des Gradient Boost-Algorithmus. Es handelt sich nämlich um eine Ansammlung von „weak learners“, die die Residuen vorhersagen und die Fehler der vorherigen „weak learners“ korrigieren.
Die Besonderheit von XGBoost liegt in der Art der „weak learner“, die verwendet werden. Bei den „weak learners“ handelt es sich um Entscheidungsbäume. Bäume, die nicht gut genug sind, werden „gestutzt“, d. h. es werden ihnen Äste abgeschnitten, bis sie gut genug sind. Andernfalls werden sie komplett entfernt. Diese Methode wird als „pruning“ (Beschneiden) bezeichnet.
So stellt XGBoost sicher, dass nur gute Weak Learners behalten werden.
Darüber hinaus ist XGBoost computeroptimiert, um die verschiedenen Berechnungen, die für die Anwendung von Gradient Boosting notwendig sind, schnell zu machen.
Schließlich bietet XGBoost eine große Auswahl an Hyperparametern. Durch diese Vielfalt an Parametern ist es möglich, die Implementierung von Gradient Boosting vollständig zu kontrollieren.
Aus all diesen Gründen ist XGBoost oft der Siegeralgorithmus bei Kaggle-Wettbewerben. Er ist schnell, präzise und effizient und ermöglicht eine Flexibilität, die es beim Gradient Boosting noch nie gegeben hat.
Die vorgestellten Algorithmen gehören sicherlich zu den am häufigsten verwendeten, aber es gibt noch viele weitere. Zu sagen, dass XGBoost der beste Machine-Learning-Algorithmus ist, wäre eine starke Einschränkung. Er hat viele Vorteile, darunter eine verblüffende Benutzerfreundlichkeit und Vielseitigkeit. Dennoch gibt es für jedes Problem eine andere Lösung. Wenn du dir also einen Überblick über die verschiedenen Arten von Machine-Learning-Algorithmen verschaffen möchtest, dann schau dir diesen Artikel über Random Forest an.







