OLAP-Würfel: Multidimensionale Analyse ist die Fähigkeit, Daten zu analysieren, die in mehreren Dimensionen zusammengefasst wurden. In diesem Artikel lernst du das Stern- und das Schneeflockenmuster kennen, die beliebtesten Modelle für multidimensionale Daten. Am Ende des Artikels findest du eine Tabelle, in der die beiden Modelle miteinander verglichen werden.
Was ist ein OLAP-Würfel?
OLAP-Würfel, für Online Analytical Processing, werden verwendet, um n-dimensionale Daten darzustellen. Die Daten werden entlang mehrerer multidimensionaler Analyseachsen wie Zeit, Ort … strukturiert.
Eine Zelle ist der Schnittpunkt verschiedener Dimensionen. Die Berechnung jeder Zelle wird beim Laden durchgeführt. Dadurch ist die Antwortzeit unabhängig von der Anfrage stabil.
Die Cubes sind so konzipiert, dass sie von allen Mitarbeitern des Unternehmens genutzt werden können und in der Lage sind, Millionen von Datensätzen auf einmal zu melden.

Stern- und Schneeflockenschemata sind die beliebtesten multidimensionalen Datenmodelle. Zwar gibt es entscheidende Unterschiede zwischen diesen beiden Technologien, aber beide verwenden Faktentabellen und Dimensionstabellen, um ein Schema zu erstellen und aufzubauen.
Diese Datenbankmodelle werden häufig verwendet, um die Analyseanforderungen von unternehmenseigenen Datenlagern – Data Warehouses – zu erfüllen.
Wir wollen zunächst den Unterschied zwischen diesen beiden Tabellen untersuchen und uns dann mit den Datenmodellen beschäftigen.
Fakten- und Maßtabelle
Die Faktentabelle und die Dimensionstabelle werden zur Erstellung von Datenschemata verwendet. Der Datensatz einer Faktentabelle ist eine Kombination von Attributen aus verschiedenen Dimensionstabellen. Die Faktentabelle ermöglicht es dem Nutzer, die verschiedenen Geschäftsbereiche zu analysieren, aus denen sich das Unternehmen zusammensetzt: Handel, Personalwesen, Supportabteilung…
Dies wird dir helfen, Entscheidungen zu treffen, um die verschiedenen Aktivitäten, die um das Unternehmen kreisen, zu verbessern.
Hier sind einige Dinge, die du beachten solltest:
- Die Faktentabelle enthält Messwerte zu den Attributen einer Dimensionstabelle.
- Die Faktentabelle enthält im Vergleich zur Dimensionstabelle mehr Datensätze und weniger Attribute.
- Die Faktentabelle nimmt vertikal an Größe zu, während die Dimensionstabelle horizontal wächst.
- Jede Dimensionstabelle enthält einen Primärschlüssel zur Identifizierung jedes Datensatzes in der Tabelle, während die Faktentabelle einen verketteten Schlüssel enthält, der eine Kombination aus allen Primärschlüsseln aller Dimensionstabellen ist.
- Die Dimensionstabelle muss vor der Erstellung der Faktentabelle gespeichert werden.
- Ein Schema enthält weniger Faktentabellen, aber mehr Dimensionstabellen.
- Die Attribute von Faktentabellen sind sowohl numerisch als auch textuell, während Dimensionstabellen nur textuelle Attribute haben.
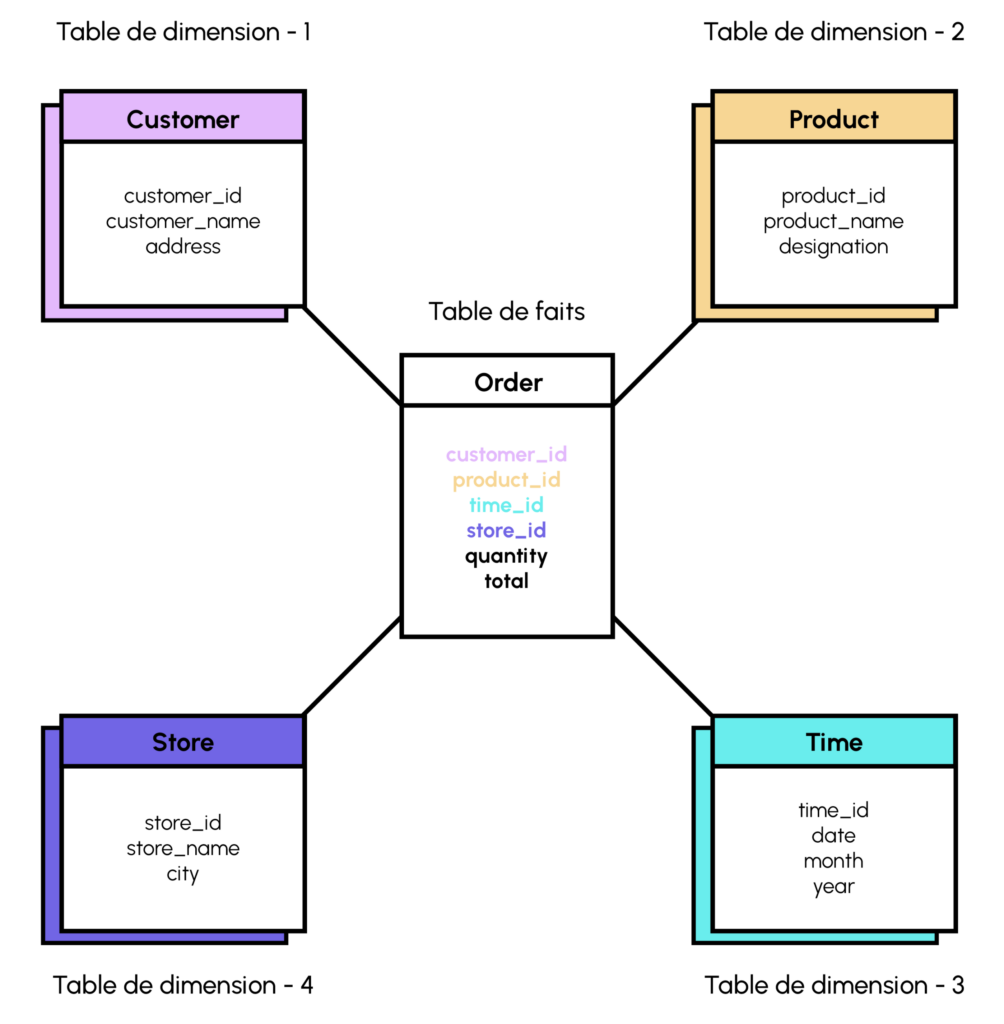
Definition des Sternschemas

Das Sternschema ist das gängigste und am weitesten verbreitete Architekturmodell für die Entwicklung von Data Warehouses, in denen die Daten in Fakten und Dimensionen organisiert sind.
Das Schema ahmt einen Stern nach, wobei eine Dimensionstabelle in einem gespreizten Muster dargestellt wird, das die zentrale Faktentabelle umgibt. Die Dimensionstabelle ist über den Primär- und den Fremdschlüssel mit den Faktentabellen verbunden.
Die Einfachheit ist einer der attraktiven Aspekte des Sternschemas, die wichtigsten Rechtfertigungen für seine Verwendung sind seine Leistungsfähigkeit und seine leichte Verständlichkeit.
Definition des Schneeflockenschemas
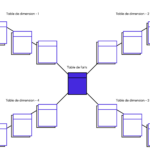
Das Schneeflockenschema ist ein Typ des Sternschemas, das die hierarchische Form der Dimensionstabellen beinhaltet. In diesem Schema gibt es eine Faktentabelle, die aus verschiedenen Dimensions- und Subdimensionstabellen besteht, die durch Primär- und Fremdschlüssel mit der Faktentabelle verbunden sind.
Es ist eine Erweiterung des Sternschemas mit zusätzlichen Funktionen. Im Gegensatz zum Sternschema sind die Dimensionstabellen des Schneeflockenschemas in mehreren zugehörigen Tabellen normalisiert. Das Schneeflockenschema wurde entwickelt, um Anfragen nach einer Dimension mit komplexen Beziehungen zwischen ihren Ebenen zu beantworten.
Dieser Schematyp eignet sich für Dimensionen, deren Ebenen durch n-zu-n- und 1-zu-n-Beziehungen verbunden sind.
Dieser Schematyp verwendet eine Normalisierung, die die Daten in Tabellen aufteilt. Durch die Aufteilung werden Redundanzen reduziert und Speicherlecks vermieden. Ein Schneeflockenschema ist leichter zu warten, aber komplexer zu entwerfen und zu verstehen als ein Sternschema.
Es kann auch die Effizienz der Navigation verringern, da mehr Joins benötigt werden, um eine Abfrage auszuführen.
Stern- oder Schneeflockenschema: Welches soll man wählen?
Integrität der Daten
Der Hauptunterschied zwischen den beiden Modellen relationaler Datenbanken ist die Normalisierung. Die Dimensionstabellen des Sternschemas sind nicht normalisiert, was bedeutet, dass das Geschäftsmodell relativ mehr Speicherplatz für die Speicherung der Dimensionstabellen benötigt.
Dadurch entstehen mehr redundante Datensätze, die zu Inkonsistenzen führen können. Das Flockenschema hingegen minimiert die Datenredundanz, da die Dimensionstabellen standardisiert sind. Dimensionen werden durch referenzielle Integrität bewahrt, was bedeutet, dass Beziehungen unabhängig zwischen Datenspeichern aufrechterhalten werden können.
Leistung der Abfrage
Das Sternschema hat weniger Fugen zwischen der Dimensions- und der Faktentabelle als das Schneeflockenschema, was eine geringere Komplexität der Abfragen bedeutet.
Da die Dimensionen in einem Sternschema über eine zentrale Faktentabelle verknüpft sind, sind die Join-Pfade klar, was schnelle Antwortzeiten bei Abfragen und damit eine bessere Leistung bedeutet. Das Snowflake-Schema hat eine höhere Anzahl von Joins, was die Antwortzeiten von Abfragen verlängert, sie komplexer macht und damit die Leistung gefährdet.
So, ich hoffe, du hast jetzt eine klare Vorstellung von den Unterschieden und Vorteilen der einzelnen Modelle für multidimensionale Daten. Ich habe dir am Ende dieses Artikels ein Geschenk versprochen, und hier ist es: eine Übersichtstabelle zum Speichern, damit du immer auf dem Laufenden bist!
Vergleichstabelle der beiden Schemata
| Merkmal | Star Schema | Snowflake Schema |
|---|---|---|
| Datennormalisierung | Denormalisiert – Weniger Normalisierung, alle Dimensionen sind direkt mit der Faktentabelle verbunden. | Normalisiert – Die Dimensionen können in separate Tabellen aufgeteilt werden. |
| Dimensionstabelle | Separate Dimensionstabellen für jede Dimension. | Möglicherweise aufgeteilte Dimensionstabellen mit Hierarchien und Unterdimensionen. |
| Leistung | Bessere Leistung durch denormalisierte Daten und weniger Joins. | Möglicherweise etwas schlechtere Leistung aufgrund zusätzlicher Joins. |
| Speicherplatz | Höherer Speicherplatzbedarf aufgrund von Redundanz in den Dimensionstabellen. | Geringerer Speicherplatzbedarf aufgrund der Normalisierung und gemeinsamer Werte in den Dimensionstabellen. |
| Komplexität | Einfacheres und leichter verständliches Design. | Möglicherweise etwas komplexer durch zusätzliche Joins. |
| Datenintegrität | Einfachere Wartung und Datenintegrität. | Möglicherweise anspruchsvollere Datenintegrität bei Verwendung von Unterdimensionen. |
| Abfrageleistung | In der Regel schnellere Abfrageleistung durch direkte Verbindung mit der Faktentabelle. | Möglicherweise etwas langsamere Abfrageleistung durch zusätzliche Joins. |
| Datenaufbereitung | Einfacheres Laden und Aufbereiten von Daten. | Möglicherweise komplexeres Laden und Aufbereiten von Daten aufgrund von Normalisierung. |
Interessierst du dich für multidimensionale Datenarchitekturen?
Du möchtest lernen, wie man mit Tools zur Verwaltung großer Datenbanken umgeht,
dann besuche unsere Weiterbildung zum Data Engineer!







