Fine Tuning vs. Prompt Engineering – Zwei Techniken zur Optimierung der KI

Fine Tuning vs. Prompt Engineering: GPT-4, PaLM 2, BARD… die Fortschritte im Bereich der künstlichen Intelligenz werden immer zahlreicher. Und vor allem werden sie für jeden zugänglich. Nicht nur Datenexperten, sondern auch Unternehmer, Marketingfachleute und sogar Studenten, die sich einen kleinen Anstoß wünschen. Die Nutzung dieser generativen KI-Lösungen ist jedoch nicht einfach. Durch ihre Demokratisierung […]
AI Fine Tuning: Alles über diese Spezialisierungstechnik von KIs

AI Fine Tuning ist eine Technik, mit der ein vortrainiertes Machine-Learning-Modell auf eine bestimmte Aufgabe spezialisiert werden kann. Hier erfährst du alles, was du über diese Technik im Herzen der künstlichen Intelligenz wissen musst! Machine Learning entwickelt sich schnell, sehr schnell. In den letzten Jahren ist das Design von vortrainierten Modellen in den Mittelpunkt des […]
Automated Prompt Engineering: Alles über die automatisierte Erstellung von Prompts für die KI

Automated Prompt Engineering ist ein neuer Ansatz, bei dem das Engineering und Schreiben von Prompts für Larger Language Models (LLM) wie GPT und andere generative KIs automatisiert wird. Erfahre alles, was du wissen musst! Mit dem Aufkommen von Tools wie ChatGPT und MidJourney löst die generative KI eine Revolution in einer Vielzahl von Branchen aus. […]
Proximal Policy Optimization: Alles über den von OpenAI entwickelten Algorithmus

Proximal Policy Optimization ist ein von OpenAI entwickelter Reinforcement-Learning-Algorithmus, der sich ideal für komplexe Umgebungen wie Videospiele oder Robotik eignet. Erfahre alles Wissenswerte über seine Geschichte, seine Funktionsweise und seine Verwendung! Im Bereich des maschinellen Lernens hat das Reinforcement Learning aufgrund seines Potenzials, komplexe Probleme zu lösen, in den letzten Jahren einen bemerkenswerten Aufschwung erlebt. […]
Apache Presto: Alles über diese SQL-Abfragemaschine

Die Fähigkeit, große Datenmengen effizient zu verwalten, ist zu einer unumgänglichen Notwendigkeit geworden. Apache Presto ist eine verteilte SQL-Abfragemaschine, die für Hochgeschwindigkeitsleistung bei riesigen Datenmengen entwickelt wurde, um diese Herausforderung zu meistern. Apache Presto wurde ursprünglich von Facebook entwickelt, um ihre eigenen Anforderungen an die Verarbeitung großer Datenmengen zu erfüllen. Apache Presto hat sich schnell […]
Power Query SDK: Alles, was man über dieses Entwicklerkit wissen muss

Das Power Query SDK ist das Entwicklerkit für Power Query, die Abfragemaschine von Microsoft, die unter anderem in Excel und Power BI zu finden ist. Es ermöglicht es, benutzerdefinierte Konnektoren für Datenquellen zu erstellen. Finde heraus, wozu es dient und wie du es verwenden kannst! Um den vollen Nutzen aus Daten und den darin enthaltenen […]
Wie findet man als Junior Data Scientist eine Stelle?

Hast du Angst, dass du als Junior Data Scientist keine Arbeit findest? Keine Panik! Entgegen der landläufigen Meinung ist dieser Status alles andere als ein Handicap und kann sogar zu deinem größten Trumpf werden. Finde heraus, wie du deine Chancen auf deinen Traumjob verbessern kannst! Es ist eine der größten Ängste, wenn man am Anfang […]
Dendrogramm: Alles über das hierarchische Clusterdiagramm

Ein Dendrogamma ist ein hierarchisches Gruppierungsdiagramm, mit dem Daten anhand ihrer Ähnlichkeiten in einer Baumstruktur angeordnet werden können. Hier erfahren Sie alles, was Sie darüber wissen müssen. Die Datenvisualisierung ist sehr nützlich, um Daten lesbar und relevant darzustellen. Es gibt eine Vielzahl von Techniken und Algorithmen, um Daten automatisch auf unterschiedliche Weise zu organisieren. Eine […]
Amazon S3: Alles Wissenswerte über den Speicherdienst von Amazon

Amazon S3, also der Speicherdienst von Amazon Web Services, wurde 2006 in den Vereinigten Staaten und ein Jahr später in Europa eingeführt. Nun ist er eine weltweite Referenz für Datenspeicherung im Internet. Er wird von vielen Unternehmen aller Branchen zum Hosten von Websites und mobilen Anwendungen sowie zum Archivieren, Backups und Wiederherstellung von Daten verwendet. […]
Bagging im Machine Learning: Was ist das?
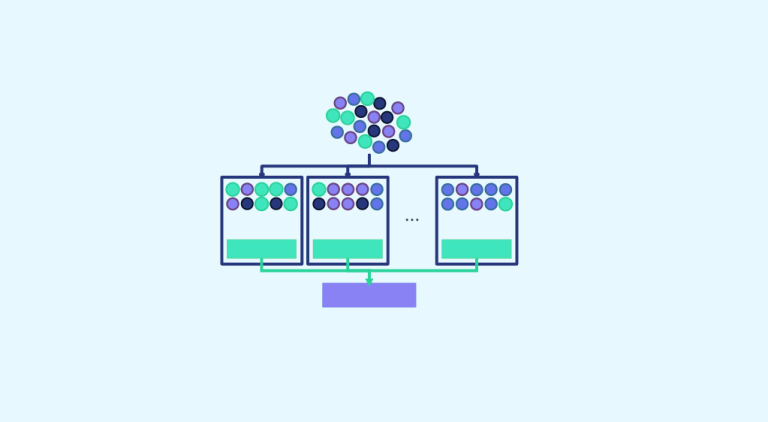
„Gemeinsam sind wir stärker“: Mit diesem Zitat könnte man Bootstrap aggregating (kurz Bagging genannt) definieren. Tatsächlich gehört diese Technik zu den Ensemblemethoden, bei denen eine Gruppe von Stichproben betrachtet wird, um die endgültige Entscheidung zu treffen. Nun schauen wir uns den Fall des Baggings genauer an. Zunächst ist es notwendig, dass wir mit Daten arbeiten. […]
Korrelation zwischen Variablen: Wie lässt sich die Abhängigkeit messen?

In der Data Science ist es von entscheidender Bedeutung, herauszufinden und zu quantifizieren, in welchem Ausmaß zwei Variablen miteinander verbunden sind. Diese Beziehungen können komplex sein und sind nicht unbedingt direkt sichtbar. Einige dieser Abhängigkeiten beeinträchtigen jedoch die Leistung von Machine-Learning-Algorithmen wie beispielsweise linearen Regressionen. Es ist daher unerlässlich, die eigenen Daten optimal vorzubereiten. Entdecke […]
Fibonacci Folge: Rekursion, Kryptographie und Goldener Schnitt

In der Welt der Mathematik ist die Bedeutung von Folgen und Reihen in der Analysis nicht mehr zu leugnen. Manchmal ist es schwierig, eine konkrete Anwendung für Konzepte zu finden, die in diesem Bereich erfunden (oder entdeckt?) wurden. Die Fibonacci Folge ist in vielen Bereichen der Natur zu finden und fasziniert Forscher immer wieder durch […]
