AWS und Avalanche demokratisieren die Blockchain in Unternehmen

Die Blockchain-Technologie existiert seit 2008 und wurde von Satoshi Nakamoto entwickelt. Diese ermöglicht es, Informationen transparent, sicher und ohne zentrale Kontrollinstanz zu speichern und zu übertragen. Allerdings haben Unternehmen erst vor kurzem begonnen, sich für diese Technologie zu interessieren. Um diesen Bereich weiter auszubauen, wollen AWS und Avalanche einen Dienst anbieten, der die Verwaltung von […]
No Code: Das neue Eldorado?
Während sich die Data Science demokratisiert, zahlen Unternehmen und Regierungen Millionen in die digitale Umwandlung, um die Entwicklungszyklen von Anwendungen zu verkürzen. Auch in Frankreich fragen Unternehmen nach dem Potenzial von No Code. Um diese Fragen zu vereinen, hat Ksaar, ein führender französischer Anbieter von No-Code-Software, eine Umfrage unter 4.263 französischen Unternehmen durchgeführt, um ihre […]
Resampling: Eine Methode zum Datenabgleich
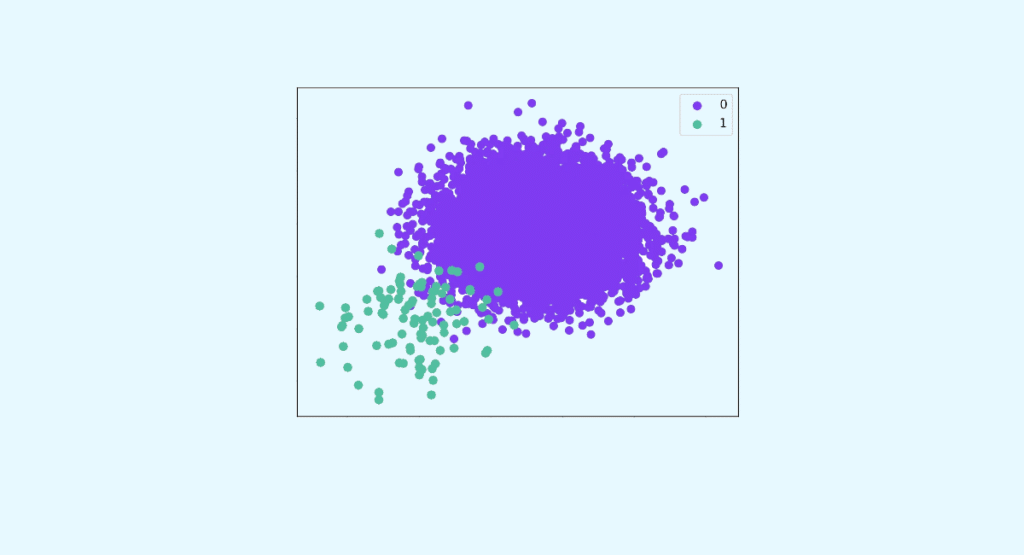
Unausgewogene Daten sind beim Machine Learning sehr häufig anzutreffen. Leider machen sie die vorausschauende Analyse komplexer. Um diese Datensätze auszugleichen, wurden verschiedene Methoden . Dazu gehört auch das Resampling. Wie geht man mit unausgewogenen Daten durch Resampling um? Unausgewogene Daten zeichnen sich durch Stichproben aus, bei denen eine starke Ungleichheit festzustellen ist. So liegt das […]
Data Science beschleunigt die Drive-Zustellung

Der Drive-In ist einer der wichtigsten Umsatzbringer für Fast-Food-Restaurants, aber die Bewältigung des Andrangs und die langen Wartezeiten beeinträchtigen das Kundenerlebnis. Die bestehenden Lösungen auf dem Markt, die auf Bodensensoren basieren, beschränken die Einzelhändler auf Konfigurationen, die nur auf das Drive-In ausgerichtet sind. Um die Wartezeiten der Kunden zu verkürzen und den Drive-In-Restaurants die Möglichkeit […]
Amazon SES: Was ist das? Wie nutzt man diesen Service?

In der heutigen digitalen Umgebung ist die Kommunikation per E-Mail für Unternehmen von entscheidender Bedeutung. Amazon SES (Simple Email Service) ist ein vielseitiger Cloud-Dienst von Amazon Web Services (AWS), der eine umfassende Lösung für den sicheren, zuverlässigen und skalierbaren Versand von E-Mails bietet. Egal, ob du Transaktionsnachrichten automatisieren, weltweite Marketingkampagnen durchführen oder zeitnahe Benachrichtigungen an […]
Data Science ermöglicht Zugang zu europäischen wissenschaftlichen Zeitschriften

Die Kosten für die Veröffentlichung oder den kostenpflichtigen Zugang zu wissenschaftlichen Zeitschriften stellen ein Hindernis für die Entwicklung der Forschung dar. Inspiriert vom Diamond Open Access Modell, das die Veröffentlichung und den kostenlosen Zugang zu institutionellen Dokumenten ermöglicht, leitet die Universität Göttingen in Deutschland das EU-Projekt Creating a Robust Accessible Federated Technology for Open Access […]
A.I. Künstliche Intelligenz kartographiert alle Bäume der Welt

Die Entwaldung ist ein großes Problem, das die Zerstörung vieler natürlicher Lebensräume verursacht und zur globalen Erwärmung beiträgt. Um bei der Erhaltung der Wälder zu helfen, haben Wissenschaftler der Universität Kopenhagen eine künstliche Intelligenz entwickelt, die den Baumbestand eines Landes genau quantifizieren kann. Wie funktioniert diese künstliche Intelligenz? Dieses Modell, das von Maurice Mugabowindekwe und […]
Rechenzentren im Weltraum – das Ziel des ASCEND-Projekts

Die Nutzung von Data Science stellt einen Wendepunkt für Geschäftsbereiche dar, die nach Wachstum streben. Datenzentren, die Daten speichern, verarbeiten und verbreiten, sind jedoch für 10 % des weltweiten Energieverbrauchs und 4 % der Treibhausgasemissionen verantwortlich. Um den digitalen Wandel zu unterstützen, hat die Europäische Kommission das ASCEND-Projekt ins Leben gerufen, in dessen Rahmen Rechenzentren […]
Data Visualization Tools: Gebe deinen Daten einen Sinn!

Data Visualization Tools ermöglicht es dir, deine Rohdaten in Form von Grafiken oder Infografiken darzustellen, um sie leichter verständlich zu machen. Mit dem Aufkommen von Big Data und der Vervielfachung der Datenquellen greifen Unternehmen immer häufiger auf Datenvisualisierung oder Data Visualization zurück. Diese visuellen Darstellungen erleichtern das Verständnis von Rohdaten und helfen so bei der […]
Amazon KI: Künstliche Intelligenz der nächsten Generation von AWS bereitgestellt

Amazon KI : Google und Microsoft konkurrieren seit einigen Monaten miteinander, und nun gesellt sich Amazon dazu. Am Donnerstag, den 13. April, wurde der AWS-Dienst um zwei neue Dienste erweitert, Bedrock und Titan, um mit den Lösungen von Microsoft und Google zu konkurrieren. Amazon KI: Worin bestehen diese neuen Dienste? Nach einer Ankündigung, dass AWS […]
KI in der Industrie: Eine europäische künstliche Intelligenz für Industrieroboter

Das EMERGE-Konsortium versucht, eine künstliche Intelligenz zu entwickeln, die in der Lage ist, ein kollaboratives Bewusstsein, eine Vorstellung von der Existenz, der Umwelt und gemeinsamen Zielen, zwischen Gruppen von individuellen Roboteragenten zu schaffen. Worin besteht diese künstliche Intelligenz? Was ist künstliche Intelligenz? Sie sind sich ihres eigenen Körpers, ihrer Umgebung, der anderen Person und des […]
Digital Analyst: Alles über diesen Beruf
In einer sich ständig verändernden digitalen Landschaft versuchen Unternehmen, die Auswirkungen ihrer Online-Strategien zu verstehen und zu maximieren. Hier kommt die entscheidende Rolle des Digital Analysts ins Spiel. In diesem Artikel erkunden wir seine Rolle, seine Hauptaufgaben und die Fähigkeiten, die du brauchst, um in diesem schnell wachsenden Bereich erfolgreich zu sein. Was ist ein […]
