
Mit seinen zahlreichen Funktionen zur Verarbeitung der Daten, mit denen wir arbeiten, hat sich Pandas als unverzichtbares Werkzeug für Data Scientists und Data Analysts etabliert - hier einige Pandas Best Practices:
In diesem Artikel wirst du einige eher unbekannte Pandas Best Practices sehen, die deine Arbeitsweise verändern können.
1. Eine Legende zu einem Dataframe hinzufügen
Ähnlich wie bei Grafiken, die mit Matplotlib oder Seaborn angezeigt werden, ist es möglich, durch eine Codezeile eine Legende zu einem Dataframe hinzuzufügen, wenn dieser angezeigt wird.
Wir beginnen damit, die benötigten Bibliotheken zu importieren:
import pandas as pd
import numpy as np
Als Nächstes erstellen wir einen Dataframe mit zufälligen Daten :
df = pd.DataFrame({'Age': np.random.randint(20, 80, size=5),
'Taille': np.random.randint(150, 190, size=5),
'Poids': np.random.randint(50, 100, size=5),
'Salaire': np.random.randint(1000, 4000, size=5)})
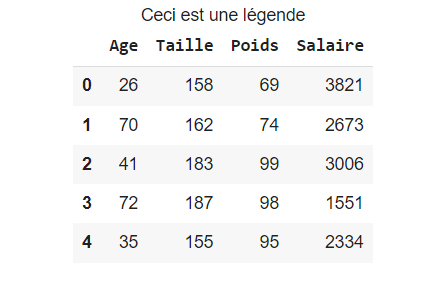
Schließlich fügst du mit der Funktion set_caption() die Legende zum Dataframe hinzu:
legende = "Ceci est une légende"
df.style.set_caption(legende)
2. Einen Fortschrittsbalken hinzufügen
Wenn du die Daten in deinem Dataframe verarbeitest, kann dies eine Weile dauern und du möchtest vielleicht den Fortschritt verfolgen. Um dies zu erreichen, kannst du einen Fortschrittsbalken anzeigen lassen, der sich mit dem Prozentsatz der abgeschlossenen Verarbeitung ändert.
Beginnen wir damit, die benötigten Bibliotheken zu importieren:
import pandas as pd
import time
from tqdm.notebook import tqdm
Wir initialisieren die Funktion tqdm, mit der wir den Fortschrittsbalken auf dem Notebook anzeigen können:
tqdm.pandas()
Als Nächstes erstellen wir einen Dataframe mit zufälligen Daten :
df = pd.DataFrame({'Age': np.random.randint(20, 80, size=5),
'Taille': np.random.randint(150, 190, size=5),
'Poids': np.random.randint(50, 100, size=5),
'Salaire': np.random.randint(1000, 4000, size=5)})
Du erstellst eine Funktion, die simuliert, dass die Verarbeitung eines Dataframes 0,5 Sekunden pro Zeile dauern würde:
def process_row(row):
tqdm.pandas(desc="Traitement en cours")
time.sleep(0.5)
Du wendest die Verarbeitung auf den Datenframe an, während du den Fortschrittsbalken anzeigst:
df.progress_apply(process_row, axis=1)
Wir zeigen eine Nachricht an, wenn die Verarbeitung abgeschlossen ist:
print("Traitement du DataFrame terminé.")

3. Ändere die Formatierung unseres Dataframes
Bei der Anzeige unseres Dataframes ist es möglich, Farben hinzuzufügen, die Anzahl der angezeigten Dezimalstellen festzulegen oder die den verschiedenen Spalten zugeordneten Einheiten hinzuzufügen. Hierzu können wir die Funktion style.format() von Pandas verwenden.
Wie zuvor importieren wir die benötigten Bibliotheken und erstellen den Datenframe, der verwendet werden soll:
import pandas as pd
import numpy as np
df = pd.DataFrame({'Age': np.random.randint(20, 80, size=10),
'Taille': np.random.randint(1500, 1900, size=10)/1000,
'Poids': np.random.randint(5000, 10000, size=10)/100,
'Salaire': np.random.randint(100000, 400000, size=10)/100})
Wir zeigen den Dataframe an, um die Standardansicht zu sehen :
df
Wir zeigen den Dataframe an, um die Standardansicht zu sehen :
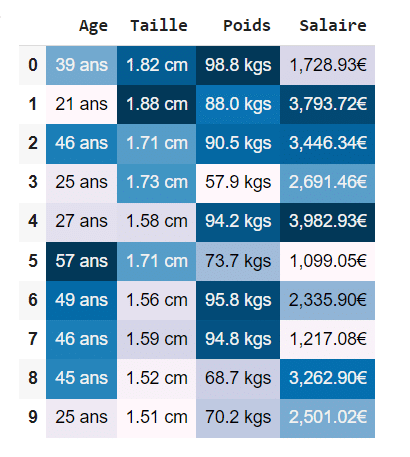
df.style.format({"Age": "{} ans",
"Taille": "{:.2f} cm",
"Poids": "{:.1f} kgs",
"Salaire":"{:,.2f}€"})\
.background_gradient()
Lass uns die verschiedenen Elemente dieser Bestellung aufschlüsseln:
"Salaire":"{:,.2f}€"
.2 gibt an, dass zwei Dezimalstellen beibehalten werden sollen.
f bedeutet, dass du eine Fließkommazahl (float) zurückgeben möchtest.
Das Komma nach dem Doppelpunkt bedeutet, dass man die Tausender durch Kommas trennen möchte.
background_gradient()
Hiermit kannst du die Kästchen der verschiedenen Spalten mit einem Farbverlauf einfärben, wobei die höchsten Werte die dunkelsten Farben haben.
Es ergibt sich folgendes Bild:
3. Ändere die Formatierung unseres Dataframes
Bei der Anzeige unseres Dataframes ist es möglich, Farben hinzuzufügen, die Anzahl der angezeigten Dezimalstellen festzulegen oder die den verschiedenen Spalten zugeordneten Einheiten hinzuzufügen. Hierzu können wir die Funktion style.format() von Pandas verwenden.
Wie zuvor importieren wir die benötigten Bibliotheken und erstellen den Datenframe, der verwendet werden soll:
import pandas as pd
import numpy as np
df = pd.DataFrame({'Age': np.random.randint(20, 80, size=10),
'Taille': np.random.randint(1500, 1900, size=10)/1000,
'Poids': np.random.randint(5000, 10000, size=10)/100,
'Salaire': np.random.randint(100000, 400000, size=10)/100})
Wir zeigen den Dataframe an, um die Standardansicht zu sehen :
df
Wir wenden nun eine Formatierung auf die Daten an:
df.style.format({"Age": "{} ans",
"Taille": "{:.2f} cm",
"Poids": "{:.1f} kgs",
"Salaire":"{:,.2f}€"})\
.background_gradient()
Lass uns die verschiedenen Elemente dieser Bestellung aufschlüsseln:
"Salaire":"{:,.2f}€"
background_gradient()
Hiermit kannst du die Kästchen der verschiedenen Spalten mit einem Farbverlauf einfärben, wobei die höchsten Werte die dunkelsten Farben haben.
Es ergibt sich folgendes Bild:
5. Kurven in einem Dataframe anzeigen
Es ist möglich, Kurven in einen Dataframe einzufügen.
Wir importieren die notwendigen Bibliotheken :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from base64 import b64encode
from io import BytesIO
from IPython.display import HTML
Dann fügen wir die folgende Zeile ein, damit Matplotlib Grafiken im Codefluss anzeigen kann:
%matplotlib inline
Anschließend wird ein Dataframe mit zufälligen Daten erstellt:
data = [('Euro', np.random.randint(40000, size=100)),
('Dollar', np.random.randint(5000, size=100)),
('Yen', np.random.randint(15000, size=100))]
df = pd.DataFrame(data, columns=['Devise', 'Cours'])
Als Nächstes werden wir eine Funktion definieren, um die Kurven zu erstellen, die wir anzeigen wollen:
# Wir konvertieren den Dataframe in eine Liste.
data = list(data)
# Wir erstellen den Graphen mit einer bestimmten Größe.
fig, ax = plt.subplots(1, 1, figsize=(5, 1))
# Wir zeigen die Daten an
ax.plot(data)
# Wir schließen die Grafik, damit sie nicht außerhalb der gewünschten Stellen angezeigt wird.
plt.close(fig)
# Wir speichern das Bild als png und speichern seine Binärdaten.
img = BytesIO()
fig.savefig(img, format='png')
encoded = b64encode(img.getvalue()).decode('utf-8')
# Wir geben das Bild codiert in HTML zurück.
return '<img decoding="async" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%200%200'%3E%3C/svg%3E" data-lazy-src="data:image/png;base64,{}"/><noscript><img decoding="async" src="data:image/png;base64,{}"/></noscript>'.format(encoded)
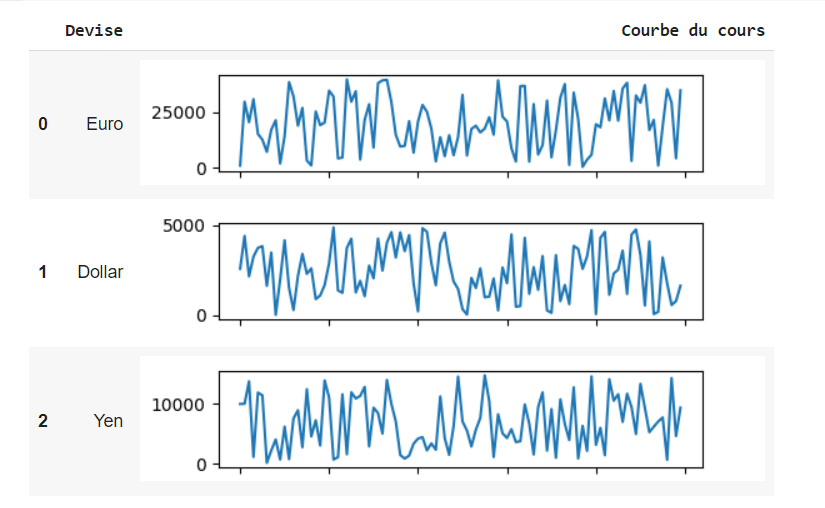
Schließlich zeigen wir den Dataframe mit den Kurven :
df['Courbe du cours'] = df['Cours'].apply(create_line)
HTML(df.drop(columns = ['Cours']).to_html(escape=False))
Mit den verschiedenen Pandas Best Practices, die in diesem Artikel vorgestellt werden, kannst du Informationen in deine Dataframes einfügen und so mehr relevante Daten herausholen, wenn du sie präsentieren musst!
Wenn du Data Frames von A bis Z beherrschen möchtest, schau dir unsere Ausbildung zum Data Scientist an!







