Ein Random Forest ist eine Machine-Learning-Technik, die bei Data Scientists sehr beliebt ist, und das aus gutem Grund: Sie hat im Vergleich zu anderen Data-Algorithmen viele Vorteile.
Es ist eine einfach zu interpretierende, stabile Technik, die im Allgemeinen gute Akkuratesse aufweist und für Regressions- oder Klassifikationsaufgaben verwendet werden kann. Sie deckt daher einen Großteil der Probleme des Machine Learning ab.
In Random Forest steht zuerst das Wort „Forest“ (Wald). Das bedeutet, dass der Algorithmus auf Bäumen basiert, die als Entscheidungsbäume bezeichnet werden.
Was ist ein Entscheidungsbaum ?
Wie der Name schon sagt, hilft ein Entscheidungsbaum dem Data Scientist, eine Entscheidung zu treffen. Er stellt eine Reihe von Fragen (auch Tests genannt) und deren Antworten (ja/nein) führen zur endgültigen Entscheidung.
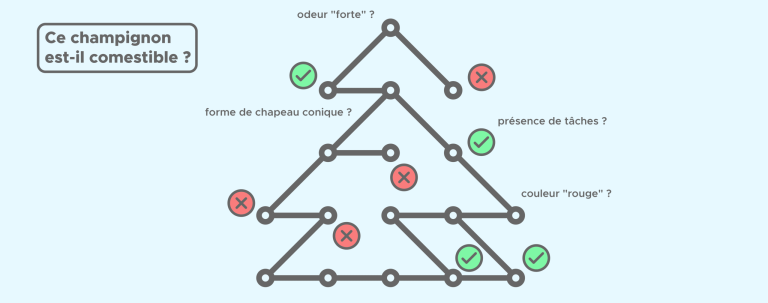
Nehmen wir ein Beispiel für eine binäre Klassifizierung: Ob ein Pilz essbar ist, wird anhand folgender Kriterien – oder Features auf Englisch – ermittelt: Farbe, Größe des Pilzes, Form des Hutes, Geruch, Größe des Stiels, Vorhandensein von Flecken etc
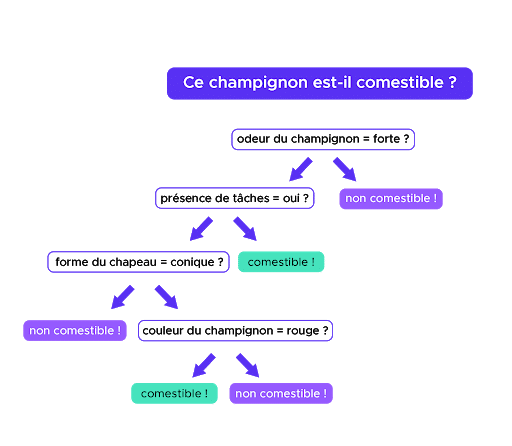

Im Baum entspricht jede Frage einem Knoten, d. h. einer Stelle, an der sich ein Zweig in zwei Zweige teilt. Je nachdem, wie die Antwort auf die Frage lautet, bewegen wir uns in Richtung des einen oder anderen Zweiges des Baumes, um schließlich zu einem Blatt des Baumes (oder Ende) zu gelangen, das die Antwort auf unsere Frage enthält.
Vielleicht fragst Du Dich, wie man die Reihenfolge der zu stellenden Fragen auswählt: Warum sollte man mit dieser oder jener Frage beginnen?
Bei jedem Knoten stellt sich der Algorithmus die Frage, welche Frage er stellen soll, d.h. ob er sich eher für den Geruch, die Form des Hutes oder die Größe des Pilzes interessieren soll. Er berechnet also für jedes Feature den Informationsgewinn, den wir erhalten würden, wenn wir dieses Feature auswählen würden. Wir wollen den Informationsgewinn maximieren. Der Baum wählt also die Frage aus und somit das Feature, das diesen Gewinn maximiert.
Der Wald, eine Kombination von Bäumen?
Random Forest ist eine sogenannte Ensemble-Methode, d. h. es werden Ergebnisse „zusammengesetzt“ oder kombiniert, um ein tolles Endergebnis zu erzielen.
Aber die Ergebnisse, wovon? Ganz einfach: die verschiedenen Entscheidungsbäume, aus denen sie zusammengesetzt sind.
Sie können aus mehreren Dutzend oder sogar Hunderten von Bäumen bestehen. Die Anzahl der Bäume ist ein Parameter, der normalerweise durch Kreuzvalidierung angepasst wird. Kurz gesagt ist die Kreuzvalidierung eine Technik zur Bewertung eines Machine-Learning-Algorithmus, bei der das Modell mit Teilen des Ausgangsdatensatzes trainiert und getestet wird.
Jeder Baum wird auf eine Teilmenge des Datasets trainiert und liefert ein Ergebnis (ja oder nein in unserem Pilzbeispiel). Die Ergebnisse aller Entscheidungsbäume werden dann zu einer endgültigen Antwort zusammengefasst. Der Baum „stimmt“ ab (ja oder nein) und die endgültige Antwort ist diejenige, die die Mehrheit der Stimmen erhalten hat.
Dies ist eine sogenannte Bagging-Methode :
- Wir teilen unser Dataset in mehrere zufällig zusammengestellte Teilmengen von Stichproben auf – daher das „Random“ in Random Forest.
- Man trainiert ein Modell auf jeder Teilmenge: Es gibt so viele Modelle wie Teilmengen.
- Wir kombinieren alle Ergebnisse der Modelle (z. B. mit einem Abstimmungssystem), was uns ein Endergebnis liefert.
Auf diese Weise baut man ein robustes Modell aus mehreren Modellen auf, die nicht unbedingt gleich robust sind.
Dieser Algorithmus ist aufgrund seiner Fähigkeit, die Ergebnisse seiner Bäume zu kombinieren, um ein zuverlässigeres Endergebnis zu erhalten, sehr beliebt. Aufgrund seiner Effektivität wird er in vielen Bereichen eingesetzt, z. B. im Telefonmarketing, um das Verhalten von Kunden vorherzusagen, oder im Finanzwesen für das Risikomanagement.
Möchtest Du eine Ausbildung in Machine Learning beginnen? Entdecke unsere Weiterbildungen zum Data Analyst, Data Scientist und Data Engineer!







