Selenium Python: Was ist Web Scraping ?
Als Data Scientist, Data Engineer oder Data Analyst musst du mit Datensätzen umgehen, die in eine Anwendung, einen Machine-Learning-Algorithmus oder eine Datenanalyse einfließen.
In manchen Fällen kannst du bereits erstellte Datensätze verwenden, aber manchmal musst du den Datensatz auch selbst zusammenstellen oder einen Datensatz vervollständigen, indem du Informationen aus dem Internet abrufst.
Informationen manuell zu sammeln, z. B. durch Kopieren und Einfügen des Inhalts, der dich interessiert, auf jeder Seite, ist undenkbar, wenn die Menge der zu sammelnden Informationen groß ist. Glücklicherweise ist es möglich, das Sammeln von Inhalten im Internet mithilfe von Web Scraping zu automatisieren.
Web Scraping bezeichnet das automatische Abrufen von Daten und Inhalten aus dem Internet. Python verfügt über mehrere Bibliotheken, die das Web Scraping ermöglichen.
Unter diesen ist die Beautiful Soup Library wahrscheinlich die bekannteste und hat den Vorteil, dass sie einfach zu bedienen ist. Sie ist jedoch nicht in der Lage, Informationen abzurufen, die dynamisch über JavaScript in eine Webseite eingefügt werden. Heute werden wir uns mit dem Selenium-Framework beschäftigen, das unter anderem den Vorteil hat, dies zu ermöglichen.
Warum Selenium für Web Scraping verwenden?
Selenium ist ein Open-Source-Framework, das ursprünglich entwickelt wurde, um automatisierte Tests in verschiedenen Browsern (Chrome, Internet Explorer, Firefox, Safari,…) durchzuführen. Diese Bibliothek wird auch zum Web-Scraping verwendet, da sie es ermöglicht, zwischen Internetseiten zu navigieren und mit den Elementen der Seite wie ein echter Benutzer zu interagieren.
Auf diese Weise wird es möglich, dynamische Webseiten zu scrapen, d. h. Webseiten, die dem Benutzer je nach seinen Aktionen ein bestimmtes Ergebnis zurückgeben.
Im weiteren Verlauf dieses Artikels werden wir sehen, wie wir mit Selenium Nachrichtenartikel von der Euronews-Website abrufen und einen Dataframe erstellen können, der für ein Textmining-Projekt bereit ist.
Praxisbeispiel: Web Scraping von Zeitungsartikeln, die von Euronews abgerufen wurden
Um unser Web-Scraping-Skript und unsere Analyse zu implementieren, werden wir Jupyter Notebook verwenden. Zuerst musst du die verschiedenen Bibliotheken, die du für die Verwendung von Selenium benötigst, mit Hilfe von pip install auf deiner Python-Umgebung installieren.
„`
pip install selenium
pip install webdriver_manager
„`
Das Selenium-Modul bietet Zugang zu :
Auf den Selenium webdriver, eine wichtige Komponente, die unseren Code, hier in der Programmiersprache Python, interpretiert und mit dem Browser interagiert. Im Rahmen dieses Tutorials werden wir einen Webtreiber verwenden, der den Chrome-Browser steuert.
Auf die By-Methode, die es ermöglicht, mit dem DOM zu interagieren und Elemente auf der Webseite zu finden.
Das Modul WebDriver Manager sorgt für die Verwaltung (Download, Konfiguration und Wartung) der von Selenium WebDriver benötigten Treiber.
Importieren wir nun die benötigten Bibliotheken:
Es ist soweit, wir können mit dem Thema beginnen. Wir werden die Euronews-Artikel des Vortags scrapen.
Hier ist eine Beschreibung der verschiedenen Schritte, die wir durchführen werden:
Wir gehen auf die Archivseite der Artikel des Vortags.
Die Links aller Artikel, die am Vortag des aktuellen Datums erschienen sind, abrufen und in einer Liste speichern.
Iteriere die in unserer Liste enthaltenen Links und erstelle eine weitere Liste, die für jeden Artikel ein Wörterbuch mit :
- Titel des ArtikelsDas Datum, an dem er erschienen ist
- Die Autoren
- Die Absätze des Artikels
- Die Kategorie
- Der Link zu dem Artikel
- Eine schnelle visuelle Analyse unseres Textkorpus durchführen
Schritt 1: Verwende Selenium, um auf die Artikel des Vortags zuzugreifen.
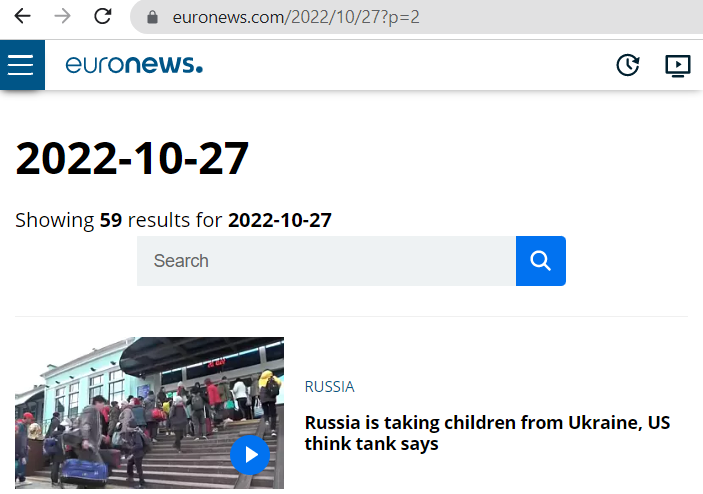
Zunächst wollen wir uns mit der Struktur der Url des euronews-Archivs beschäftigen. Um die Artikel eines bestimmten Tages abzurufen, hat die Url die Form: https://www.euronews.com/{years}/{month}/{days}.
Wir stellen auch fest, dass es eine Paginierung mit 30 Artikeln pro Seite gibt und dass es bei mehr als 30 Artikeln möglich ist, von einer Seite zur nächsten zu wechseln, indem man einen Query-Param in die Url einfügt: https://www.euronews.com/{years}/{month}/{days}?p={page}.
Foto zum Einfügen :
Um das Datum des Vortags abzurufen, verwenden wir die Bibliothek datetime und erstellen drei Variablen, die das Jahr, den Monat und den Tag enthalten.
Wir testen die Selenium-Bibliothek, indem wir einen Chrome Webdriver initialisieren. Der unten stehende Code ermöglicht es uns, mit Selenium automatisch alles auszuführen, was wir manuell tun würden: den Browser öffnen, die Euronews-Seite mit den Artikeln des Vortags aufrufen, auf die Schaltfläche zum Akzeptieren von Cookies klicken und auf der Seite scrollen.
Die Funktion scroll wurde in einer Zelle weiter oben im Notebook definiert:
Schritt 2: Links aus den Artikeln abrufen
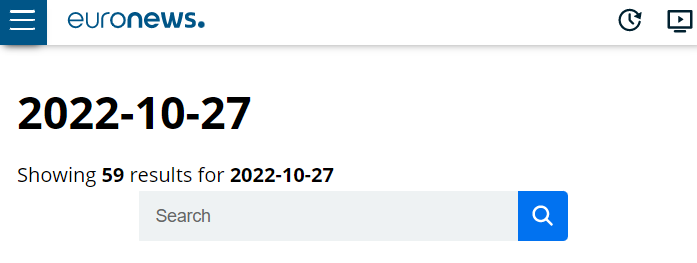
Wir stellen fest, dass die Anzahl der Artikel für einen bestimmten Tag auf der Webseite steht, damit wir wissen, von welcher Seite wir die Artikel abrufen müssen:
Unabhängig von den verwendeten Web-Scraping-Bibliotheken ist es notwendig, die Seite zu inspizieren, um die Elemente der Webseite zu identifizieren, die für uns von Interesse sind. Wir können dies über CSS-Selektoren tun.
Um eine Seite zu inspizieren, klicke mit der rechten Maustaste und dann auf „Inspizieren“ oder verwende den Shortcut Strg + Cmd + C unter macOS oder Strg + Shift + C unter Windows und Linux.
Mit der BY-Klasse von Selenium (die wir anstelle der .find_elements_by-Methode verwenden werden) haben wir die Wahl zwischen verschiedenen Arten von Eigenschaften, um ein Element auf einer Webseite zu lokalisieren, unter anderem:
- Die ID des Elements
- Der Name des Elements
- Der Name des Tags
- Seinen Xpath
- Seine Klasse
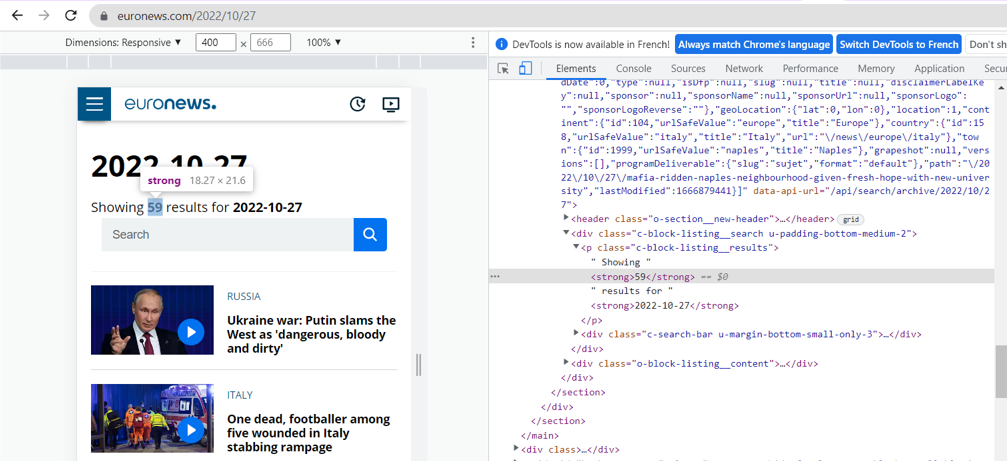
Nach der Inspektion sehen wir, dass sich der Elementzähler im ersten strong-Tag der Klasse „c-block-listing__results“ befindet.
Um das Element abzurufen, werden wir seinen XPath verwenden. Der XPath ist ein XML-Pfad, der es ermöglicht, durch die HTML-Struktur einer Seite zu navigieren und jedes Element auf dieser Seite zu finden.
Beim Webscraping ist es besonders nützlich, den XPath-Pfad eines Elements zu verwenden, wenn die Klasse des Elements nicht ausreicht, um es zu identifizieren, z. B. wenn wir ein Sub-Tag eines Elements einer bestimmten Klasse abrufen möchten.
Der Xpath eines HTML-Elements ist wie folgt strukturiert:
//tag_name_of_major_element[@attribute=“Value“]/tag_name_of_sub_element[index_of_the_sub_element]
Wo:
tag_name_of_major_element entspricht dem Haupt-Tag (div, img, p, b usw.).
attribute entspricht der Klasse oder id des Elements und value seinem Wert.
tag_name_of_sub_element entspricht dem Tag des Unter-Tags.
index_of_the_sub_element beginnt bei 1 und entspricht der Nummer des Sub-Tags. Dieser Index ist nur relevant, wenn es mehrere Unterelemente gibt, die im Haupttag enthalten sind.
Die Methode .text, ermöglicht uns den Zugriff auf den Wert des Textes des Elements, hier „57“.
Anhand der Anzahl der abgerufenen Artikel und der Paginierung auf 30, die wir beobachtet haben, berechnen wir die Anzahl der Seiten, die wir scrapen müssen, hier 2.
Wir werden nun die Links der verschiedenen Artikel abrufen. Beim Inspizieren fällt uns auf, dass die Links der Artikel die Klasse object__title__link haben. Wir rufen alle Elemente ab, die diese Klasse haben, und erstellen eine Liste, die für jedes Element den Wert des Attributs href (das den Link enthält) enthält, den wir mit der Methode get attribute abgerufen haben.
Schritt 3: Scraping des Inhalts jedes Artikels
Wir kommen nun zum entscheidenden Teil dieses Artikels: dem Scraping jedes einzelnen Artikels, der in der zuvor erstellten Artikelliste enthalten ist. Lass uns die Struktur der HTML-Seite inspizieren :
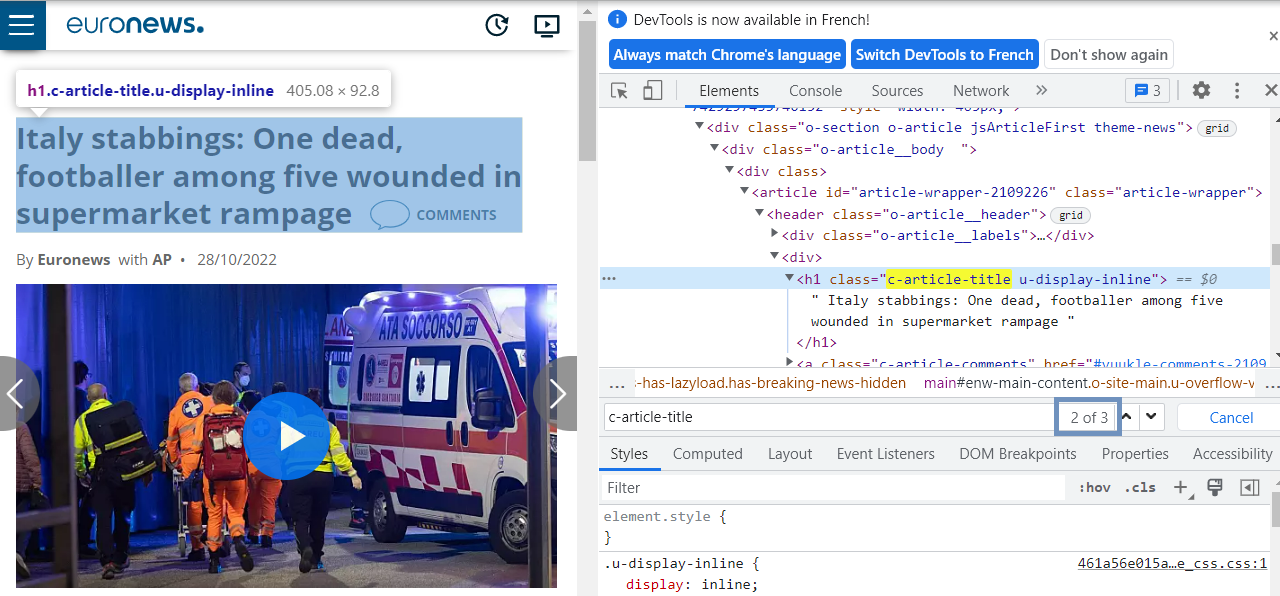
Es fällt auf, dass die uns interessierenden Kontextdaten wie Titel, Autor, Kategorie usw. immer an zweiter Stelle der Klassen stehen, die wir lokalisiert haben. An der ersten Position enthält das HTML nämlich Informationen über den vorherigen Artikel, die auf der Seite nicht angezeigt werden.
Mit dem folgenden Code können wir die Inhalte, die uns auf der Seite interessieren, abrufen:
Hier sind die verschiedenen Schritte des vorherigen Codes:
- Man greift auf jeden Artikel zu.
- Man ruft den Text der Kontextdaten des Artikels ab (Titel, Autoren, Kategorie, Veröffentlichungsdatum).
- Man ruft die Absätze des Artikels ab.
- Man erstellt ein Wörterbuch mit den abgerufenen Daten.
- Man fügt dieses Wörterbuch zu einer Liste mit dem Namen „list_of_articles“ hinzu.
Im Falle eines Fehlers speichert man den Link des Artikels in einer Liste „errors“.
NB: Es fällt auf, dass es sich bei den meisten fehlerhaften Artikeln um Videoartikel handelt, die eine andere html-Struktur haben. Im Rahmen dieses Artikels beschließen wir, die wenigen Fehlerfälle nicht zu behandeln.
Schritt 4: Schnelle Visualisierung
Bevor wir zum Schluss kommen, werden wir eine kurze Visualisierung der gescrappten Artikel durchführen. Dieser Schritt könnte zu den ersten Schritten eines Natural Processing Language (NLP)-Projekts gehören.
Zunächst importieren wir die für den weiteren Verlauf notwendigen Bibliotheken und erstellen dann einen Dataframe mithilfe der Wörterbuchliste list_of_articles.
Hier sind die ersten Zeilen des Dataframes :

Zunächst beschäftigen wir uns mit den verschiedenen Kategorien von Artikeln, indem wir mithilfe der Seaborn-Bibliothek die Anzahl der Artikel pro Kategorie anzeigen.
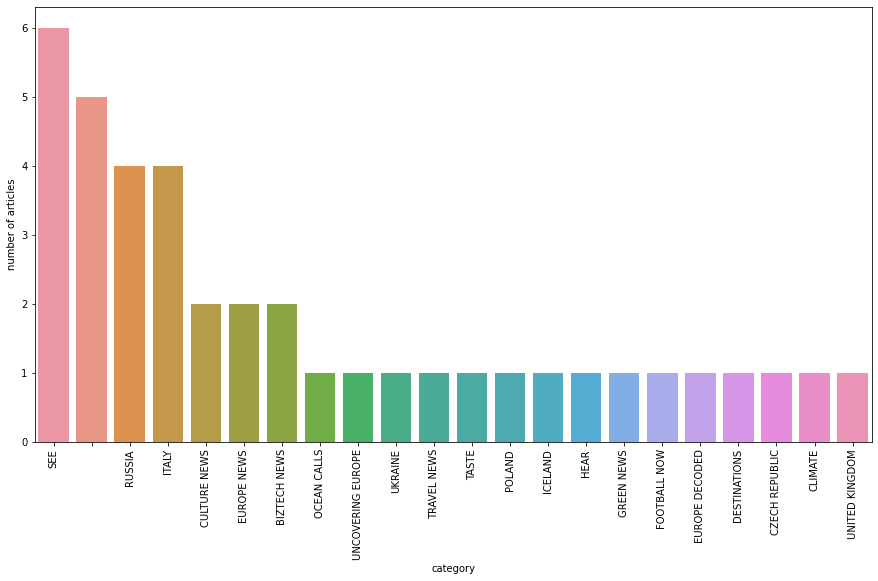
Bevor wir die Wortwolke anzeigen, entfernen wir die Stopwords mithilfe der Klasse stopwords aus dem Paket nltk.corpus.
Schließlich definieren wir eine Funktion, um eine Wortwolke mithilfe des Moduls wordcloud zu erstellen, das als Argument unsere Reihe mit den Artikeln nimmt.
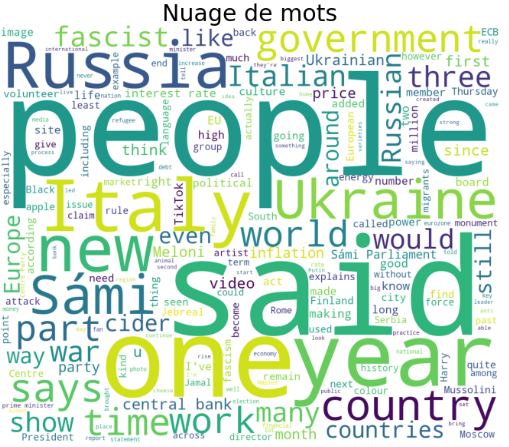
Hiermit sind wir am Ende dieses Tutorials angelangt, das dir gezeigt hat, wie Selenium dir beim Scraping von Daten im Internet helfen kann und dir die Gelegenheit gegeben hat, eine schnelle visuelle Analyse von Textdaten durchzuführen.
Wenn du mehr über die Hintergründe des Einsatzes von Web Scraping in den verschiedenen Datenberufen erfahren möchtest, kannst du dir gerne unseren Artikel zu diesem Thema ansehen oder dich über die Inhalte unserer verschiedenen Studiengänge informieren.







