Die Sentiment Analyse ist eine Technik, die sich mit den sozialen Netzwerken stark entwickelt hat, in denen die Nutzer die Möglichkeit haben, sich massiv auszudrücken und ihre Gefühle ständig zu teilen. Die Gefühlsanalyse (oder sentiment analysis) zielt also darauf ab, den emotionalen Ton einer Rede zu bestimmen, indem sie sie in verschiedene Kategorien wie z. B. positiv, negativ oder neutral einteilt.
Sie ist bei einer Vielzahl von Akteuren beliebt, vom Politiker im Wahlkampf bis hin zu Unternehmen, die ein neues Produkt auf den Markt bringen wollen, um nur einige zu nennen.
Der Politiker möchte seine Beliebtheit bei den Wählern testen, während das Unternehmen herausfinden möchte, wie sein Produkt bei der Öffentlichkeit ankommt.
fig.: Beispielsatz, der analysiert werden soll
Aber was ist eigentlich Sentiment Analysis und wie nutzen Data Scientists Machine-Learning-Techniken, um den emotionalen Ton einer Rede zu entschlüsseln?
Wie funktioniert Sentiment Analysis?
Die Stimmungsanalyse (oder sentiment analysis) kommt bei der schriftlichen und mündlichen Kommunikation zum Einsatz. Data Scientists haben die Möglichkeit, Audio- oder Textdaten auszuwerten. Das Format der Daten bestimmt, welche Machine-Learning-Technik verwendet wird.
Wie analysiert man einen mündlich gesprochenen Satz?
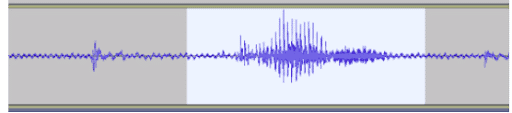
In diesem Fall sind die zu analysierenden Daten ein vom Gehirn erzeugtes elektrisches Signal, das Elektroenzephalogramm ( oder EEG) genannt wird. Im Großen und Ganzen sieht das so aus:
Abb.: Beispiel für ein elektrisches Signal, das vom Gehirn erzeugt wird [1].
Um diese Daten zu sammeln, die später analysiert werden, werden Elektroden auf dem Schädel angebracht. Wenn das Experiment an dir durchgeführt wird, würdest du ungefähr so aussehen:
Nachdem die Signale gesammelt wurden, müssen daraus Merkmale (im Englischen auch features genannt) extrahiert werden, die die im Signal enthaltene Information darstellen. Diese Merkmale sind ein Format, das für den Machine-Learning-Algorithmus, der die Signale klassifiziert, besser lesbar ist. Die Extraktion von Merkmalen erfolgt, indem verschiedene Transformationen wie Filter auf das elektrische Signal angewendet werden.
Sobald wir die Merkmale extrahiert haben, geben wir sie in unseren Algorithmus ein, z. B. in ein Neuronales Netzwerk (oder Neural Network), damit es die Signale in verschiedene Kategorien einteilen kann: positiv/negativ/neutral.
In Wirklichkeit wird diese Technik, ein Gehirnsignal zu sammeln, um es dann zu analysieren und daraus eine Polarität (positiv/negativ/neutral) abzuleiten, im Alltag kaum genutzt und vor allem in der Forschung eingesetzt, insbesondere von Forschern, die sich für Probleme interessieren, die Künstliche Intelligenz und Neurowissenschaften miteinander verknüpfen.
Wie wird ein auf Facebook geschriebener Kommentar klassifiziert?
Diese Methoden analysieren direkt die Wörter und müssen die kontextuellen und linguistischen Aspekte der Daten berücksichtigen.
Kurz gesagt, der zu analysierende Satz wird als eine Sequenz behandelt, die einen Kontext definiert und deren Wörter voneinander abhängig sind, d. h. sie werden im Hinblick auf die Wörter analysiert, die ihnen im Satz vorausgehen.
Um diese Sätze zu verarbeiten, verwenden Data Scientists rekurrente neuronale Netze (RNN), die auf die Verarbeitung von Sequenzen spezialisiert sind.
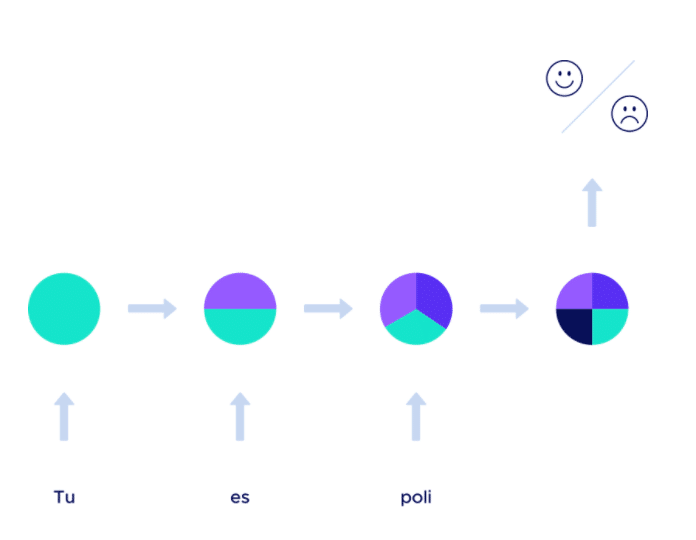
Eine (stark vereinfachte) RNN-Architektur für die Analyse von Gefühlen könnte daher wie folgt aussehen:
Abb.: Architektur eines RNN für die Analyse von Gefühlen
Wenn wir den Satz „Du bist höflich“ nehmen, sehen wir, dass das Wort „höflich“, wenn es vom Algorithmus analysiert wird, eine der beiden Klassen (in diesem Fall positiv) zurückgibt, und dass dieses Wort „höflich“ nach dem Wort „bist“ analysiert wurde (d. h. im Kontext des Wortes „bist“), das seinerseits nach dem Wort „du“ analysiert wurde (d. h. im Kontext des Wortes „du“).
Natürlich gibt es auch subtile Sätze, die für Maschinen komplex zu analysieren sind. „Dieses Parfüm riecht extrem gut, es macht süchtig“. Das Wort „extrem“ kann sowohl positiv als auch negativ konnotiert sein, während „süchtig“ in der Regel mit einem negativen Gefühl verbunden ist.
Obwohl die Technologie der rekurrenten neuronalen Netze (RNN) schon seit vielen Jahren existiert, ist es Wissenschaftlern erst vor kurzem gelungen, sehr vielversprechende Ergebnisse zu erzielen, vor allem dank der immer besser werdenden Rechenleistung. Diese Technologie wird daher immer regelmäßiger von Unternehmen eingesetzt, die von ihren Nutzern ein Feedback zu einem Produkt erhalten möchten, oder von allen anderen Personen, die Zugang zu einer großen Menge an Nachrichten haben, um daraus eine allgemeine Stimmung abzuleiten.
Hat dir dieser Artikel gefallen?
Du fragst dich, wie du Daten von einer Website abrufen kannst, um die Gefühle der Nutzer zu analysieren?
Melde Dich jetzt für unseren Newsletter an, um unsere Guides, Tutorials und die neuesten Entwicklungen im Bereich Data Science direkt per E-Mail zu erhalten.