Das Sammeln von Daten ist der erste Schritt zur Erstellung eines Modells für Machine Learning. Daher ist es entscheidend, ein Datenbankmodell auszuwählen, das die Eigenschaften bietet, die deine Anwendung am meisten benötigt.
Relationale und NoSQL-Datenbanken sind die beiden am häufigsten verwendeten Systemfamilien. Sie unterscheiden sich in ihrer Struktur, der von ihnen bereitgestellten Datenspeicherung und ihrer Zugänglichkeit. In diesem Artikel werden wir jede ihrer spezifischen Eigenschaften betrachten.
Relationale Datenbanken:
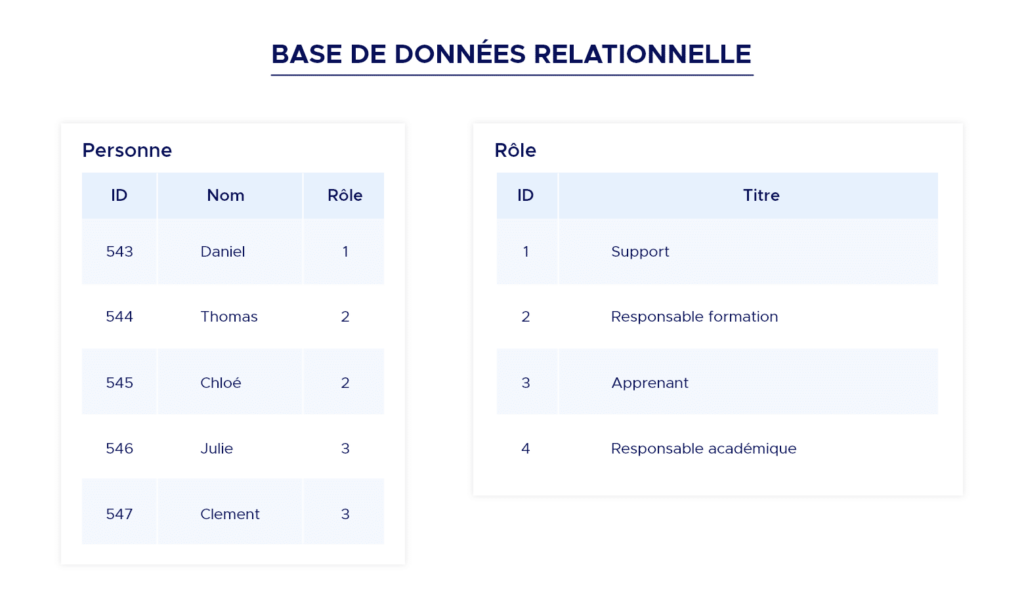
Sie sind der älteste Typ von Datenbanken für allgemeine Zwecke, der auch heute noch weit verbreitet ist. In relationalen Datenbanken werden Daten mithilfe von Tabellen organisiert. Tabellen sind Strukturen, die den darin enthaltenen Datensätzen ein Schema aufzwingen.
Jede Spalte in einer Tabelle hat einen Namen und einen Datentyp. Jede Zeile steht für einen Datensatz in der Tabelle, der Werte für jede der Spalten enthält.
Die Sprache SQL, wurde entwickelt, um auf die in diesem Format gespeicherten Daten zuzugreifen und um die ACID-Eigenschaften zu gewährleisten. Sie eignen sich oft für regelmäßige und vorhersehbare Daten. Da sie auf einem Schema basieren, kann es schwieriger sein, die Struktur der Daten zu ändern, wenn sie einmal im System sind.
Insgesamt sind relationale Datenbanken für viele Anwendungen eine solide Wahl, da Anwendungen oft gut geordnete und strukturierte Daten erzeugen.
NoSQL-Datenbank
Die nächsten Typen, die wir uns ansehen werden, gehören zur Familie der NoSQL-Datenbanken: hochleistungsfähige Alternativen für Daten, die nicht in das relationale Modell passen.
Sie zeichnen sich durch ihre Benutzerfreundlichkeit, Skalierbarkeit, Ausfallsicherheit und Verfügbarkeit aus.
Dokumentorientierte Datenbank
Gute Wahl für eine schnelle Entwicklung, da du die Eigenschaften der Daten, die du speichern möchtest, jederzeit ändern kannst, ohne die bestehenden Strukturen oder Daten zu verändern.
Jedes Dokument ist eigenständig und hat sein eigenes Organisationssystem. Wenn du deine Datenstruktur noch nicht festgelegt hast, könnte dieses Modell ein guter Ausgangspunkt sein.
Sei jedoch vorsichtig, denn Flexibilität bedeutet, dass du für die Aufrechterhaltung der Konsistenz verantwortlich bist, was äußerst schwierig sein kann.
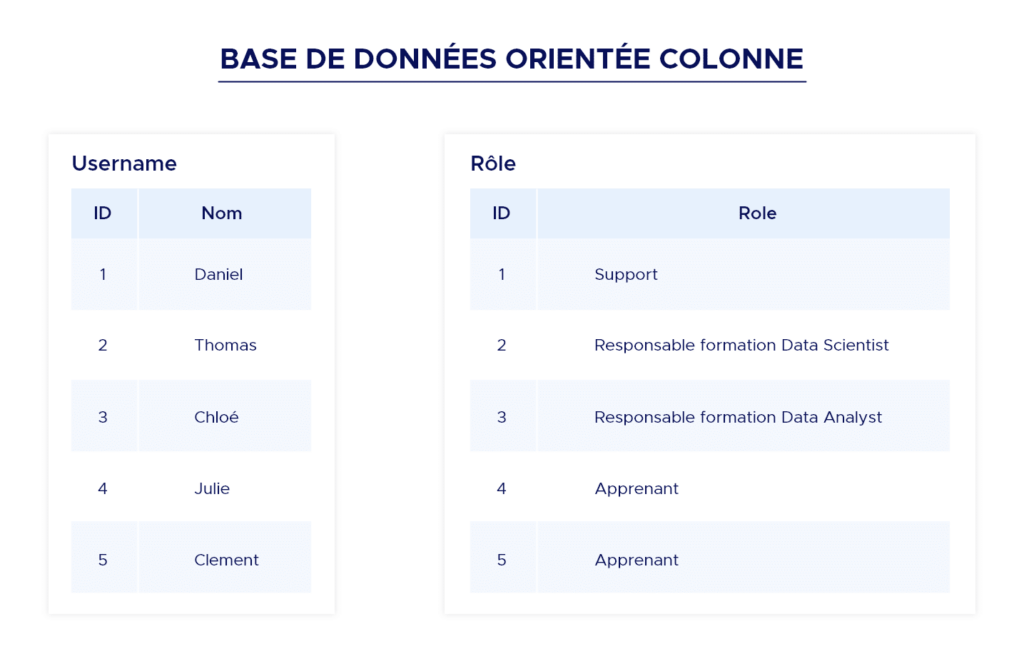
Spaltenorientierte Datenbank
Nützlich für Anwendungen, die eine hohe Leistung für den Online-Betrieb und eine hohe Skalierbarkeit erfordern. Da alle Daten und Metadaten eines Eintrags mit einem einzigen Zeilenbezeichner zugänglich sind, sind keine rechenintensiven Joinings nötig, um Informationen zu finden und abzurufen.
Sie funktionieren jedoch nicht in allen Fällen gut. Wenn du hochrelationale Daten hast, die Joins erfordern, ist dies nicht das richtige Modell, das du verwenden solltest.
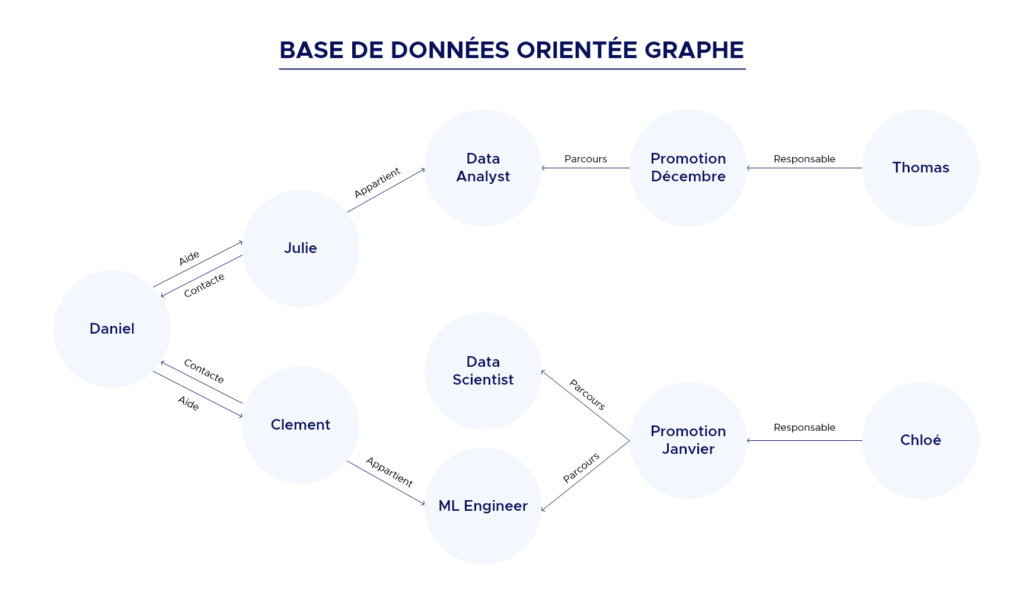
Graphisch orientierte Datenbank
Sie sind besonders nützlich, wenn du mit Daten arbeitest, deren Verbindungen sehr wichtig sind.
Wenn du z. B. in einer relationalen Datenbank nach der Verbindung zwischen zwei Nutzern eines sozialen Netzwerks suchst, ist es wahrscheinlich, dass du mehrere Tabellen verbinden musst und daher ziemlich ressourcenintensiv ist. Dieselbe Abfrage wäre in einer grafischen Datenbank, die direkt Verbindungen zueinander herstellt, einfach.
Das Ziel von Grafikdatenbanken ist es, die Arbeit mit dieser Art von Daten intuitiv und leistungsfähig zu machen.
Die Wahl der richtigen Datenbank hängt nicht nur von der Wahl der Typologie ab, sondern auch vom Verständnis des CAP-Theorems.
Im nächsten Artikel werden wir uns mit dem CAP-Theorem beschäftigen, damit du alle Waffen hast, um dein Data-Projekt zu beginnen.
Was wäre, wenn dein Data-Projekt mit einem von Experten entwickelten und von der Sorbonne zertifizierten Kurs in Data Science beginnen würde?
Melde Dich jetzt für unseren Newsletter an, um unsere Guides, Tutorials und die neuesten Entwicklungen im Bereich Data Science direkt per E-Mail zu erhalten.