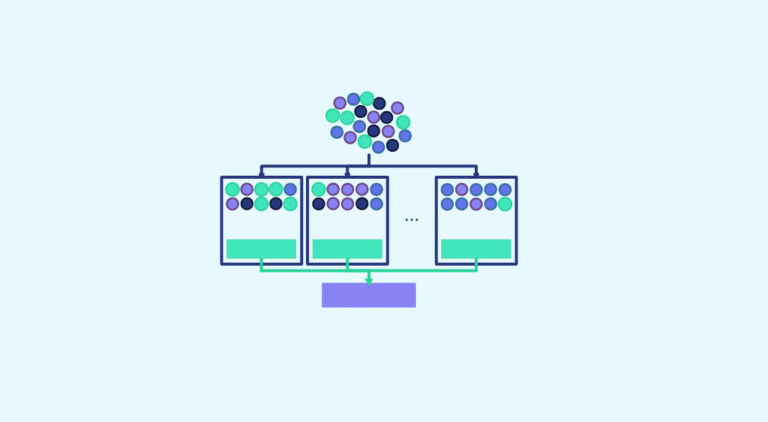
Bagging Machine Learning: "Together we're stronger" - bagging could be symbolised by this quote. In fact, this technique is one of the ensemble methods, which consists of considering a set of models in order to make the final decision. Let's take a closer look at bagging.
First of all, we need to work on the data. We’re not going to provide all our models with the same data, because we want our models to be independent. The problem is that we can’t partition the dataset. For a large number of models, our models would not be sufficiently trained and would produce mediocre results.
The solution to our problems: bootstrapping
To overcome this problem, we create a bootstrap dataset. With this method, we create a new dataset from the initial dataset. The new dataset is the same size as the initial one. Let n be the sample size and let E_1 be the initial dataset and E_2 the bootstrapped dataset.
From E_1, we will randomly select an individual and place it in E_2. We will repeat this step until E_2 is of size n. It’s important to note that the elements chosen are always in E_1, so we can select the same element several times. It is this feature that allows us to produce different data.
Let’s take a look at a concrete example, using the same notation as above.
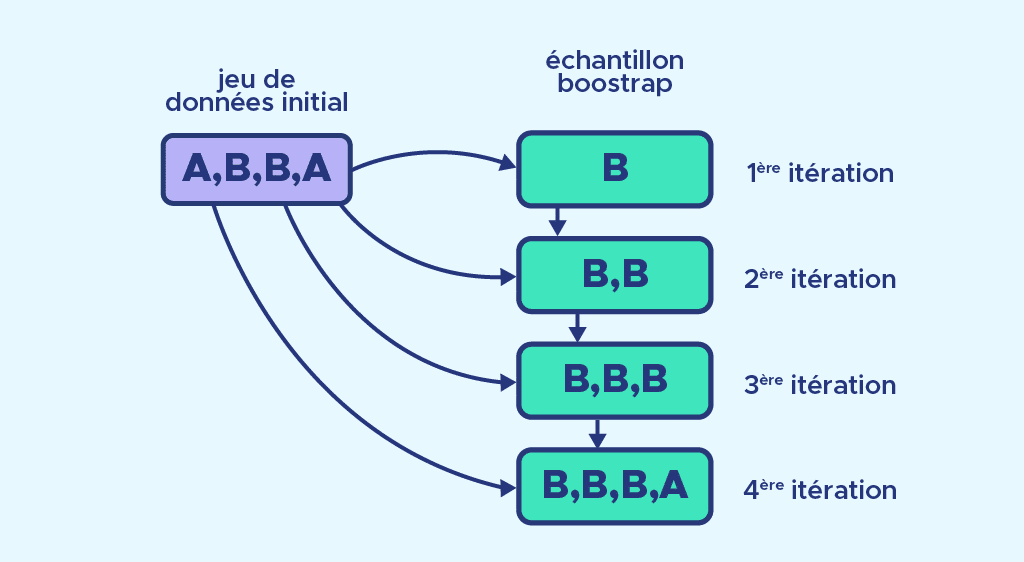
Here E_1 is made up of 2 elements called A and 2 elements called B, E_2 is empty and n=4.
On the first iteration, we randomly select an element from E_1 and place B in E_2.
This process is repeated until E_2 has 4 elements.
Finally, E_2 is made up of 3 elements B and one element A. An element B has been selected 3 times.Now that we’ve seen what the bootstrap is, we decide to make 3 bootstrap samples*. For each sample, we’ll assign a different model. Decision trees are commonly used. We train each model and make our predictions.
*the choice of 3 is arbitrary
What can we do now with 3 predictions?
We need a single value for our problem, and that’s where we do data aggregation. For classification models, we will apply a voting system and for regression models, we will average the predicted value. Referring to the initial quote, we build a final model from several models.
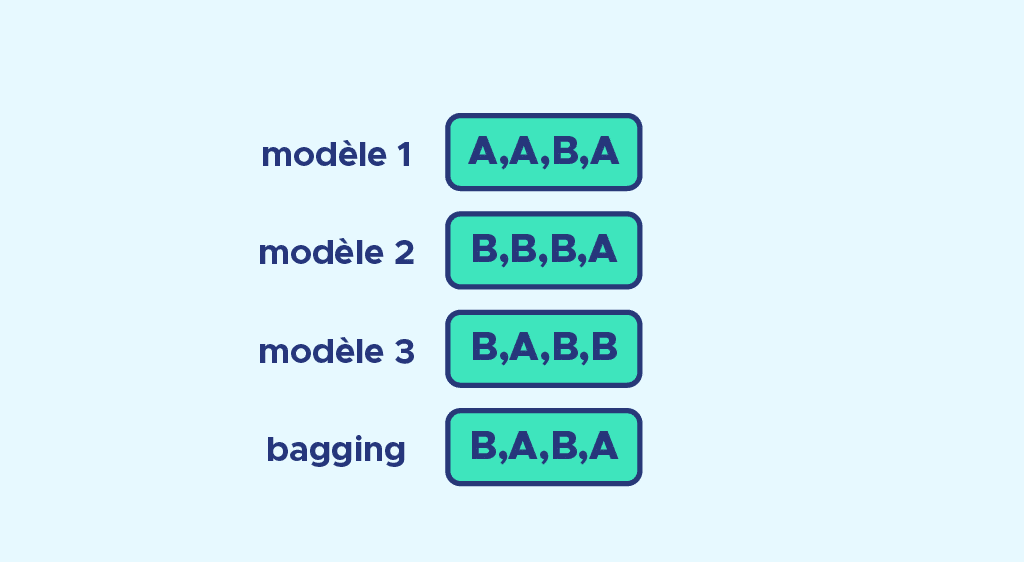
We can see an example of a voting system where we have to predict A or B, with the example below:
To understand what bagging is, we can remember that it is a combination of bootstrapping and aggregating. A famous bagging algorithm is the random forest, which you can find here. You can also find out more about another well-known aggregation technique, boosting, in this article.
Bagging = Bootstrap + aggregating
One of the advantages of this method is that it can reduce variance. Even if the models are not trained on the same data set, the bootstrap samples share common tuples, which produces bias. This bias reduces the variance.
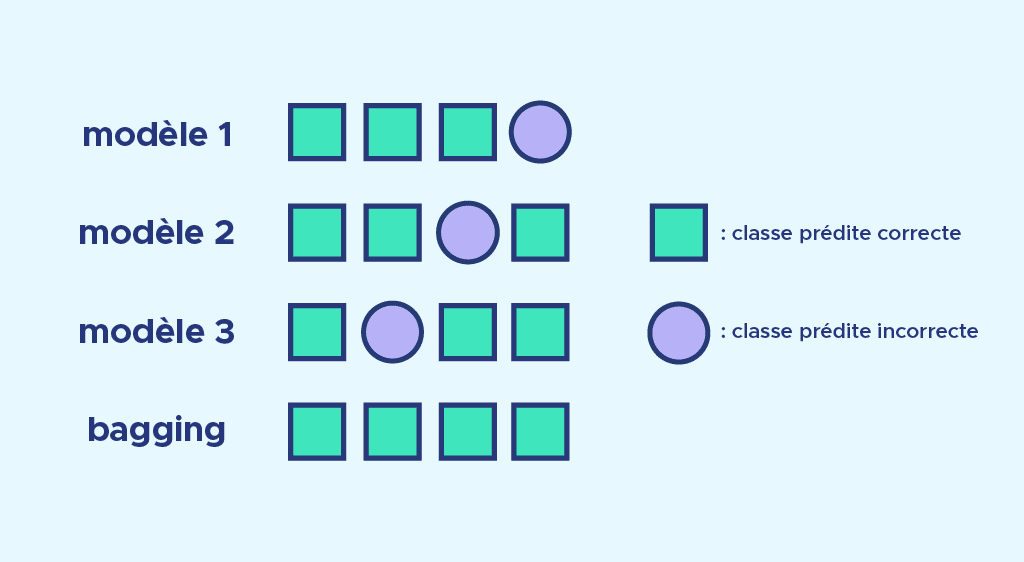
A second advantage is to correct prediction errors. Let’s look at the image below. Each model makes a classification prediction error, but each error is corrected by the voting system.
We have seen how Bagging in Machine Learning fits in with ensemble techniques. As stated in the introduction, we use several models whose predictions we aggregate to obtain a final prediction. To calibrate our different models, we create different data sets by bootstrapping on the initial sample.
If you want to put this into practice, don’t hesitate to sign up for our Data Scientist training course.








