
Amazon EMR (Elastic MapReduce) is a data processing service managed by Amazon Web Service (AWS). It enables the management of large amounts of data, in the petabyte range, using popular tools such as Apache Hadoop, Hive, Spark and HBase, to name but a few.
Amazon EMR has been designed to offer great flexibility and scalability, enabling users to achieve very fast results using powerful, highly configurable calculation clusters.
Understanding how Amazon EMR works
Amazon EMR works by creating data processing clusters that are configured to meet the specific needs of each task. These clusters are created according to the computing and storage resources required.
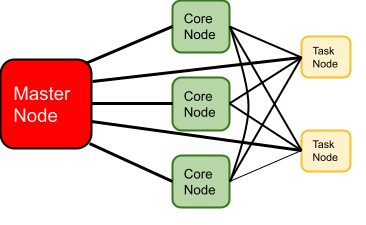
A cluster is made up of nodes of different types:
- Master Node: manages the cluster and its resources. As the primary node, it orchestrates data processing tasks.
- It also stores cluster metadata and provides a command line interface (CLI) and a Web interface for interacting with the cluster.
- Core nodes: managed by the primary node, they coordinate data storage in a file system such as HDFS. In addition, they execute parallel processing tasks.
- Task nodes: these are optional and are used to increase the capacity of data-parallel processing tasks, such as MapReduce or Spark jobs. However, they do not store data on the HDFS.
To provide processing and storage capacity, EMR uses EC2 (Elastic Compute Cloud) instances. These instances are virtual machines that can be highly configured and adapted as required.
When the EMR cluster is created, the necessary tools are automatically installed on each node of the cluster (tools such as Hadoop, Spark or Hive come to mind). Scheduling and execution of processing tasks are handled by managers such as YARN (the best-known) or Mesos.
As AWS services integrate particularly well with each other, data sources such as Amazon S3, RDS or DynamoDB can be used to enable processing by EMR. In the same spirit of integration, Amazon Cloudwatch is used to monitor cluster performance and availability.
Is Amazon EMR complicated to implement?
Installing and implementing Amazon EMR is a relatively straightforward process that can be completed in just a few steps. The prerequisite is, of course, an AWS account.
Une fois connecté à votre compte, il vous suffit de sélectionner le service EMR.
Choose the highlighted “Create a cluster” button
Then follow the steps to create a cluster according to your needs. Here’s a summary of EC2 instance types:
| Instance Class | Instance Family | Recommended Use |
|---|---|---|
| General Purpose | M4, M5 | Batch Processing |
| Compute Optimized | C5,C4 | Machine Learning |
| Memory Optimized | X1,X4 | Interactive Analysis |
| Storage Optimized | D2, I3 | Large-Scale HDFS |

Once the cluster has been created, all that’s left to do is run and deploy data processing applications. Beware, however, of pricing.
Price list
The costs associated with using Amazon EMR may vary from region to region. In addition, AWS EMR charges both for its own instance and for EC2 instances. Billing is per second, with a minimum charge of one minute. Find out more about Amazon’s pricing policy for this service.
Case studies
Let’s take a look at two case studies where AWS EMR provides the answer to data processing problems.

An online platform for restaurant reviews (among others), they turned to EMR for large-scale, real-time comment processing and analysis. Thanks to its use, Yelp can now obtain detailed analyses of trends. As the company’s needs fluctuate greatly, Yelp can now adapt its processing capacity to meet them.

As a real estate company (based in the USA), they have opted to use EMR to deploy real estate forecasting algorithms on a very large scale. This enables them to process real estate data quickly and efficiently, providing their customers with more accurate price trends, as well as monitoring variations in this highly volatile market in real time.
Conclusion
As you will have gathered from this article, Amazon EMR is a powerful and flexible cloud solution for large-scale data processing. Thanks to its ease of use and ability to integrate with other AWS services, it’s a first choice solution for companies needing high-performance data analysis to make the right decisions and adapt to changing market needs.
💡Related articles:








