
The origins of Apache Flink
Initially developed at the Technical University of Berlin, its first versions were released in 2011 and were designed to address complex data processing issues in a distributed, real-time environment.
Over the years, Flink has become a benchmark for a large number of companies, to the point of becoming one of the most popular open-source frameworks.
In 2014, Flink was accepted as an Apache Incubator project, and in 2015 became an Apache Top-Level project.
Since then, Flink has gone from strength to strength, boasting a very active community of developers and users.
💡Related articles:
The Flink ecosystem
The Apache Flink ecosystem is made up of several layers and levels of abstraction, as illustrated in the following figure:
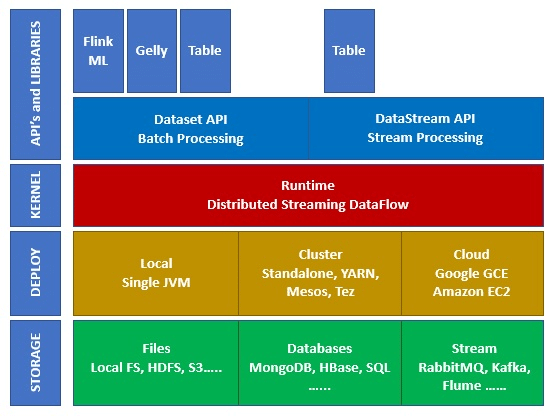
- Storage: Flink has several options for reading / writing data, such as HDFS (Hadoop), S3, local, Kafka, and many others.
- Deploy: Flink can be deployed locally, on clusters or in the cloud.
- Kernel: This is the execution layer, providing fault tolerance, distributed calculations, etc.
- API’s & Libraries: This is the highest-level layer of the Flink ecosystem. It includes the Datastream API, in charge of stream processing, the Dataset API, in charge of batch processing, and other libraries such as Flink ML (Machine Learning), Gelly (graph processing) and Table (for SQL).
How is Flink's architecture structured?
Flink is a distributed processing engine for stateful calculations on bounded or unlimited data streams. It has been designed to run in all common cluster environments, and to be able to perform calculations at very high speed, and at any scale.
All kinds of data can be streamed, from sensor readings (IoT) to event logs and even user activity on websites.
As we’ve just seen, the streams processed can be either bounded or unlimited, but what exactly does that mean?
- Unlimited streams have a beginning, but no defined end, which means that they provide data as it is generated. They must be processed continuously, i.e. immediately after ingestion. As a result, it is impossible to wait until the entire stream has arrived before processing it, but it will be necessary to process these streams in the order in which they arrive.
- Precise control of time and state enables Flink to run any type of application on these flows.
- Limited or bounded streams, on the other hand, have a defined beginning and end. Unlike unlimited streams, they can be processed after ingesting the entire data set to perform calculations. Ordered processing is therefore not necessary. Processing these streams is also known as batch-processing.
- These streams are processed internally using algorithms and calculations specially designed for fixed-size datasets.

It’s easy to see why Flink offers excellent performance when processing bounded or unlimited data sets.
What applications are linked to Flink via API's?
Apache Flink offers a rich set of APIs for transforming both batch and streaming data. These transformations are performed on distributed data, enabling developers to build an application that meets their needs. Here are the main APIs offered by Flink:
Datastream API:
This API is the main programming interface for stream processing.
It provides a high-level abstraction for stream manipulation, and offers native support for partitioning data for parallel processing.
Dataset API:
This API is a programming interface for batch processing. It also provides native support for large-scale parallel processing.
It is based on the MapReduce model, but offers more advanced capabilities, such as distributed state management, error handling and automatic optimization.
The API Table :
This API is a programming interface for relational data processing. It enables developers to create data processing programs based on tables and SQL queries, while taking advantage of the benefits offered by Flink.
It is compatible with other Flink APIs, making it easy to combine different interfaces to meet specific data processing needs.
Programs created with these APIs are easily scalable and resilient to failures thanks to Flink’s distributed architecture. They can be run on large-scale processing clusters, guaranteeing high performance and availability.
To note: There are also API's FlinkML for Machine Learning, Gelly for graph-oriented databases or CEP for Complex Event Processing.
Flink's key features
Apache Flink features the following key concepts:
- Parallelization enables Apache Flink to process data by distributing tasks over several processing nodes (slots) simultaneously. This dramatically reduces data processing time by fully exploiting the resources of the distributed environment. Tasks can be divided into several sub-tasks, which are then executed in parallel, increasing processing efficiency.
- Data partitioning involves dividing data into small groups, called “partitions”, which are then distributed across several processing nodes. Partitions can be distributed according to keys, values, or any other distribution criteria to enable them to be processed more efficiently, thus avoiding bottlenecks. This feature is a fundamental aspect of parallelization in Apache Flink.
- Apache Flink is designed to be fault-tolerant thanks to a checkpointing system, which means it can continue processing data even if one or more processing nodes fail. It can automatically detect failures and replicate data accordingly.

Comparing Flink and Spark Streaming
| Feature | Apache Flink | Spark Streaming |
|---|---|---|
| Real-time Processing | ✅ | ✅ |
| Stream Processing | ✅ Processing infinite streams with very low latency |
✅ Limited by batch size and associated latency |
| Batch Processing | ✅ | ❌ |
| Model | ✅ Based on operator transformations |
✅ Based on RDD transformations |
| Graphs | ✅ Using the Gelly API |
❌ Not supported |
| Languages | ✅ Python, Java, and Scala |
✅ Python, Java, and Scala |
| Fault Tolerance | ✅ Handles processing node failures |
✅ Tolerant to failures but less efficiently |
What are Flink's limitations?
As we’ve just seen, Flink is a very powerful tool for data processing. It does, however, have a few limitations that need to be taken into consideration:
- Resource requirements: It needs a lot of resources to run efficiently, especially for data storage and processing power.
- Complex to implement: It can be difficult to implement for developers with little experience in real-time data processing. The learning curve can be very steep.
- Documentation: Its documentation is comprehensive, but difficult to grasp depending on the reader’s experience.
- Ecosystem: Development has been rapid, but Flink is relatively new compared to other tools on the market. As a result, it may lack maturity in certain areas, or lack functionality.
- Upgrades: Code developed on earlier versions is not necessarily compatible after an API upgrade, which can be time-consuming to make compatible again.
Conclusion
In conclusion, Apache Flink is an extremely powerful and versatile data processing framework. It offers advanced features for stream and batch processing, and enables users to perform real-time data processing tasks efficiently and scalably.
Flink’s programming APIs are easy to use, offering great flexibility for developers, and its ability to handle large-scale workloads makes it a top choice for businesses and organizations of all sizes.
Although it has certain limitations, Flink continues to evolve rapidly to meet changing business needs.
Now that you know everything there is to know about Apache Flink, start a training course that will enable you to fully master this stream processing tool. Discover DataScientest!








