
Facial Attribute Editing refers to the set of methods used to modify one or more attributes of a given face. Before the advent of Deep Learning, this task was tedious, as it was carried out by hand, pixel by pixel. Recently, however, new algorithms have been developed to automate this task. Here, we take a closer look at the AttGAN model, one of these neural network-based algorithms. This algorithm takes as parameters the face we want to modify and a binary attribute vector, and returns the modified face with the desired attributes. Examples of how it works are shown below:
1- AttGAN architecture
To obtain a modified face consistent with the original, the model was built to follow 3 rules.
- Firstly, the new face must resemble the basic one (excluding attributes).
- Secondly, it must also be visually realistic, i.e. the attributes created must respect size and position constraints.
- Finally, it must have the required attributes. The AttGAN architecture can therefore be broken down into 3 main parts.
Firstly, unsupervised learning by reconstruction in latent space is used to preserve non-attribute face details. This task is performed by an Auto Encoder. If you’d like to know more about how an Auto Encoder works, an article on the subject is available on the blog.
The Decoder part of this Auto Encoder is then used to train a Generative Adversarial Network (GAN) to obtain a visually realistic modified face. Similarly, if you’d like to find out more about GAN, there’s also an article available on our blog.
Finally, to check that the new face obtained does indeed possess the new attributes requested, a classification constraint is applied to the generated image and the attributes detected are compared with the attributes requested.
This architecture can be illustrated with the image below, which shows an iteration of AttGAN training:
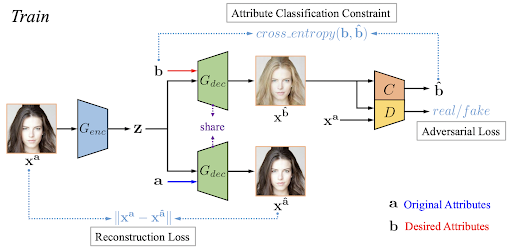
In this diagram, the image on the left is the original image and vector a contains its attributes (woman, young, brunette, …). Vector b, on the other hand, designates the desired attribute vector (woman, young, blonde, …).
The Auto Encoder is trained to minimize the Loss reconstruction, which is simply the norm of the difference between the original image and the reconstructed image. As far as the GAN is concerned, its aim is to generate a new image with the desired attributes b and to trick the D discriminator so that this image strongly resembles the original image. Constraint classification is simply achieved by detecting the attribute vector whose loss function is a Cross Entropy.
So, to put it simply, during its training phase, AttGAN will learn what each attribute corresponds to, based on its training database.
Let’s now take a look at what happens during the Test phase, when we want to modify a face:

Once the Decoder/Generator part is trained, to transform an image, we use the Encoder part to encode the image in latent space while specifying the desired new attributes, and the Generator simply generates a new image thanks to all the rules it has learned during its training phase.
2 - Database used to train AttGAN
The database used by the creators of this algorithm is CelebA. It lists over 200,000 faces of 10,177 different celebrities, annotated with 40 attributes in the form of binary vectors that specify whether the attribute is present (1) or not (0). These 40 attributes can range from simple hair color to the presence or absence of make-up on the face.

To speed up training of the algorithm, only 13 of these 40 attributes were used: bald, bangs, black hair, blond hair, chestnut hair, thick eyebrows, glasses, male, open mouth, moustache, beard, pale skin, young.
3- Results and comparison with other attribute editing algorithms
Here are the results obtained after training the neural network over 50 epochs, which corresponds roughly to one day:

The first two images in each line represent the original image and the image reconstructed by the Auto Encoder, and the following images are the images generated by modifying just one attribute at a time out of the 13 in the order stated above.
Firstly, we can see that the faces generated are consistent with the original faces.
In addition, the requested attributes are found, even if some are difficult to generate.
Finally, the attributes generated are visually realistic.
This is due to the 3 rules we imposed in the architecture during training.
However, some attributes appear more natural than others. This is the case with mouth opening and hair color. Conversely, the attributes “bald” and “glasses” are more difficult to achieve. We can therefore conclude that the modifications that consist in adding or removing material are those that have been trained the least.
Let’s now compare this model with other types of neural networks performing the same task:

Here, we compare the AttGAN with two other models whose architecture is a little different: VAE / GAN and IcGAN. We’re interested in the reconstruction of the original image, as well as a few attributes for each model. We note that AttGAN is the only model capable of reconstructing the original face almost perfectly, whereas the others modify it slightly.
We can therefore deduce that, even if the other attribute editing models do carry out the modification, they don’t respect the basic principle of preserving the details of the face outside the attribute.
4- Conclusion
In this article, we looked in detail at AttGAN, a neural network model for editing attributes on faces. We described its 3-part architecture, which enables us to obtain images that are highly consistent with the original ones. We then compared this model with other neural networks also used for attribute editing, and found it to be the most successful AttGAN yet.
If you enjoyed this article and would like to discover other Deep Learning methods, I invite you to join our Deep Learning expert course.








