In his research paper published in March 2021, Yann LeCun, Vice President and Chief Scientist of Artificial Intelligence at Facebook, describes self-supervised learning as "one of the most promising ways to build machines with basic knowledge, or 'common sense', to tackle tasks that far exceed the capabilities of today's AI".
This method, seen as “the dark matter of intelligence”, automatically labels data. As such, it looks very promising at a time when having labeled data is proving costly.
How does self-supervised learning work?
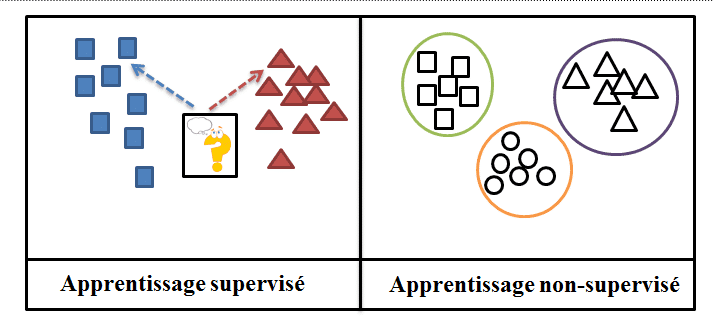
Self-supervised learning is based on an artificial neural network and can be considered halfway between supervised and unsupervised learning. It has the major advantage of processing unlabeled data and automatically generating the associated labels, without human intervention.
This method works by masking part of the training data and training the model to identify this hidden data. This is done by analyzing the structure and characteristics of the unmasked data. This labeled data is then used for the supervised learning stage.
How does it differ from supervised and unsupervised learning, and what are its advantages?
Supervised learning methods have predefined labels. Often, these labels have been assigned by human intervention.
However, this labeling work is often time-consuming and costly, and labeled data is therefore rare. What’s more, machine learning algorithms often require massive amounts of data before they can deliver accurate results.
In certain fields, such as medicine, this labeling work requires specific knowledge, making the task all the more complex. By offering an alternative to this redundant work, self-supervised learning puts itself at the top of the table.
Other methods can also get round the problem of data labeling, notably semi-supervised learning, which works mainly with unlabeled data to which a small proportion of labeled data is added.
Self-supervised learning can be likened to a sub-category of unsupervised learning, since both approaches work with unlabeled datasets. However, unsupervised learning differs in its aim, focusing exclusively on data clustering and dimension reduction. In contrast, the ultimate goal of self-supervised learning is to predict a classified output.
Another advantage of self-supervised learning lies in a deeper understanding of the data and its component patterns and structures. This makes it easy to generalize the representations learned.
Self-supervised learning in natural language processing
In the case of Natural Language Processing (NLP), we use self-supervised learning to train the model on sentences from which words have been randomly omitted. It must then predict these removed words.
This method, applied to NLP, has proved effective and highly relevant. For example, the wav2vec and BERT models developed respectively by Facebook and Google AI are among the most revolutionary in NLP. Wav2vec has proved its worth in the field of Automatic Speech Recognition (ASR).
In this way, certain parts of audios are masked and the model is trained to predict these parts. BERT, an acronym for Bidirectional Encoder Representations from Transformers, is a Deep Learning model that currently offers the best results for most NLP tasks.
Unlike previous models, which scan text one-dimensionally to predict the next word, the BERT algorithm hides words randomly in the sentence and tries to predict them. To do this, it uses the full context of the sentence, both left and right.
From NLP to Computer Vision
After proving its worth in natural language processing, self-supervised learning has also made its mark in Computer Vision.
Facebook AI has presented a new model based on self-supervised learning, applied to Computer Vision named SEER (for SElf-supERvised). It was trained on a billion unlabeled Instagram images. The model achieved a record accuracy rate of 84.2% on the ImageNet image database.
In Computer Vision, self-supervised learning has also been widely used for image colorization, 3D rotation and context filling.
What are the limits of self-supervised learning?
Model building can be more computationally intensive. Indeed, since self-supervised learning automatically generates the labels associated with the data, it adds extra computation time compared to a learning model with labels.
Self-supervised learning is useful when we have an unlabeled dataset and need to assign them manually. However, this method can generate errors during labeling, leading to inaccurate results.
What are the limits of self-supervised learning?
Model building can be more computationally intensive. Indeed, since self-supervised learning automatically generates the labels associated with the data, it adds extra computation time compared to a learning model with labels.
Self-supervised learning is useful when we have an unlabeled dataset and need to assign them manually. However, this method can generate errors during labeling, leading to inaccurate results.
Conclusion
Self-supervised learning is a further step towards artificial intelligence with “common sense”. By working with unlabeled data, this method solves the long and tedious task of labeling data. It opens up revolutionary new approaches in many areas of artificial intelligence, such as NLP and Computer Vision.
If you’d like to find out more about Machine Learning and Deep Learning algorithms, take a look at our range of training courses for data-related professions.