As far as future prospects are concerned, many hopes are pinned on unsupervised learning to improve cyber security or the identification of various diseases.
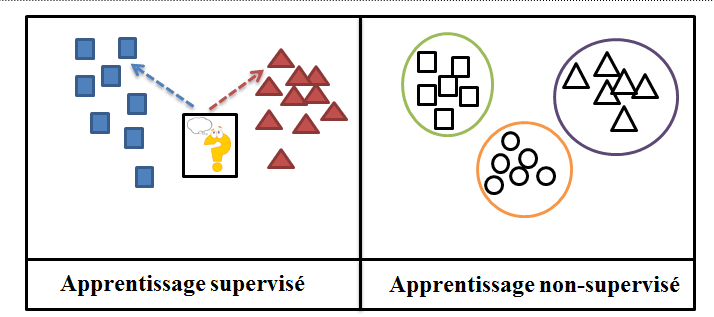
In terms of future prospects, unlike supervised learning, unsupervised learning is where the algorithm has to operate on unannotated examples. In this case, machine learning is entirely independent. The machine is fed data without being provided with examples of results.
Thus, in this learning situation, the answers we want to find are not present in the data provided: the algorithm uses unlabeled data. The machine is therefore expected to create the answers itself, through various analyses and classification of the data.
Unsupervised learning models are used in particular for :
- Data classification
- Approximate calculation of distribution density
- Dimension reduction
In this context, all the data collected are treated as random variables. Unlike machine learning, which must find a model from labeled data: f(X) Y, it uses only unlabeled data: there is no Y variable to predict.
The use of unsupervised learning can be grouped into clustering and association problems.
Unsupervised Learning & Clustering
A clustering problem is one in which the machine is expected to group together objects present in groups of data in the most accurate and efficient way possible. This technique, although sometimes difficult for humans to understand, is widely used in marketing to place different customers in groups, for example. An example of an algorithm often used in clustering is K-means.
Unsupervised Learning & Association
The association system is used to sort and group data that can be linked by certain characteristics. The aim is to find objects that are related to each other, but not identical. For example, if the algorithm is provided with numerous images of cats and cat accessories, then the unsupervised learning algorithm would not group all the cats together, but rather, for example, a ball of wool with a cat. An example of an algorithm often used in association is the A-priori algorithm.
Unsupervised learning is very often used in the field of speech recognition, as in the use of Siri or Alexa.
The latter is used to learn the phone owner’s vocal characteristics (language, tone of voice, etc.).
Similarly, some cell phones use it to automatically arrange photos. In fact, the phone is able to identify the same person in photos, or find similar places and arrange them according to these criteria.
How does Unsupervised Learning differ from supervised learning?
Although both types of learning are part of artificial intelligence, supervised learning involves learning a prediction function from labelled examples.
Supervised learning involves monitoring the machine’s learning by presenting it with examples of what it should do. Thus, the aim of supervised learning is to create algorithms capable of receiving data sets and performing statistical analysis to predict a result.
| Aspect | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Training Data | Labeled data with input-output pairs. | Unlabeled data; no explicit output labels. |
| Objective | Predict a target variable based on input. | Discover patterns, structures, or clusters in data. |
| Task Examples | Classification, Regression. | Clustering, Dimensionality Reduction. |
| Guidance | Model is guided by labeled examples. | No specific guidance from labeled data. |
| Training Process | Requires labeled data for training. | Learning from inherent data structures. |
| Performance Evaluation | Accuracy, Precision, Recall, F1 Score. | Silhouette Score, Davies-Bouldin Index. |
| Examples | Spam detection, Image recognition. | Customer segmentation, Anomaly detection. |
| Model Complexity | Often more complex models. | Simpler models, focused on data patterns. |
| Use of Validation Data | Used for tuning and validating models. | Limited use due to unsupervised nature. |
| Feedback Loop | Immediate feedback on correctness. | Less direct feedback due to lack of labels. |
| Common Algorithms | Linear Regression, Decision Trees, SVM. | K-Means, Hierarchical Clustering, PCA. |
Finally, it’s worth pointing out that there are other types of learning, such as semi-supervised learning, which is a mix of supervised and unsupervised learning.
Would you like to discover all the fields of application of supervised and unsupervised learning? Learn how to exploit them? Discover our training courses!









