
L’apprentissage semi-supervisé est une technique d’apprentissage automatique qui utilise à la fois des données labellisées et des données non labellisées. Découvrez ci-dessous comment fonctionne cette méthode d’apprentissage.
De nos jours, avec l’essor du Deep Learning, nous sommes amenés à analyser des images, des audios et des textes avec des modèles qui nécessitent un grand nombre de paramètres, rendant ainsi ces modèles sujets à l’overfitting. De plus, les données que nous récoltons dans la réalité ne sont pas toujours labellisées. De ce fait, il serait désirable d’utiliser des méthodes de régularisation qui exploitent des données non labellisées pour réduire l’overfitting dans l’apprentissage semi-supervisé.
Qu'est-ce que l'apprentissage semi-supervisé ?
L’apprentissage semi-supervisé est une technique d’apprentissage automatique qui consiste à partir d’un jeu de données constitué en majorité de données non labellisées et en minorité de données labellisées. Il se situe entre l’apprentissage supervisé qui utilise des données labellisées et l’apprentissage non supervisé qui utilise des données non labellisées. Il existe de nos jours plusieurs méthodes qui ont été développées par des grands chercheurs pour résoudre des problèmes d’apprentissage semi-supervisé notamment les méthodes de régularisation de consistance parmi lesquelles l’algorithme FixMatch développé par Sohn et al. et de l’algorithme The Mean Teacher développé par Antti Tarvainen et Harri Valpola de The Curious AI Company que nous allons présenter par la suite. Ces méthodes ont obtenu des performances remarquables sur des problèmes de classification avec des jeux de données comme CIFAR-10 par rapport à ce qui était connu auparavant dans l’état de l’art. Nous allons par la suite expliquer chacune de ces méthodes.
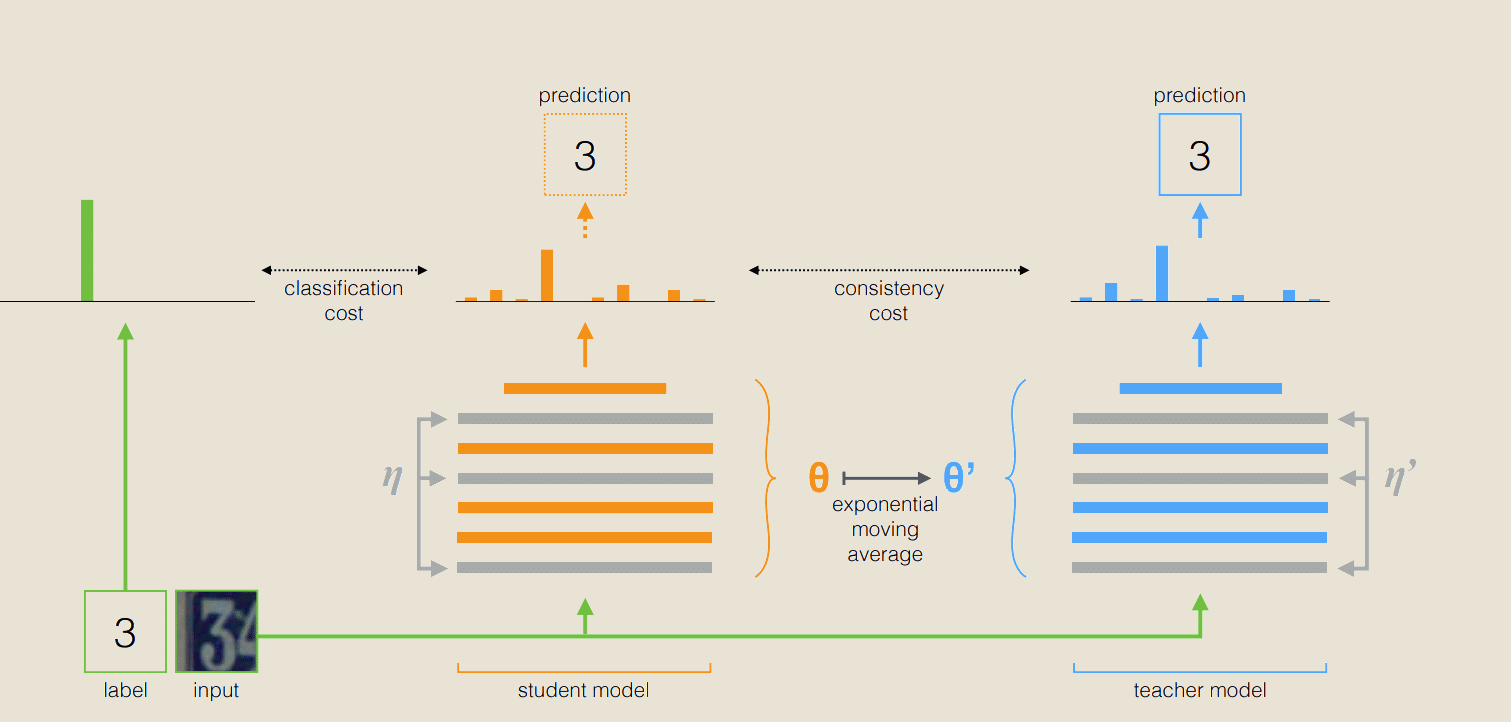
La méthode The Mean Teacher est constituée de deux modèles : le modèle élève et le modèle enseignant. Pour effectuer la classification de données avec cet algorithme, on commence par effectuer un apprentissage supervisé avec les données labellisées à notre disposition sur le modèle élève. Durant cet apprentissage, l’objectif comme on le sait consistera à minimiser le coût de classification comme on peut le voir sur la figure ci-dessus. Au terme de cet apprentissage supervisé, on va envoyer le jeu de données non labellisées à notre modèle et c’est à ce niveau que le coût de consistance et la moyenne mobile exponentielle interviennent.
On définit le coût de consistance comme la distance moyenne entre la prédiction du modèle élève et celle du modèle enseignant, l’objectif ici étant de faire converger les deux modèles au terme de l’entraînement vers la même prédiction. La fonction de consistance est donnée par :
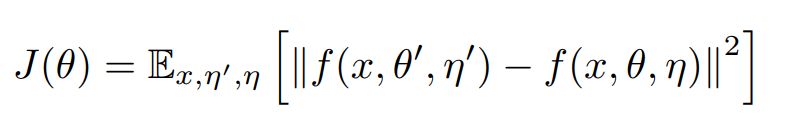
Pourquoi ajouter des bruits au modèle ?
Le bruit est important pour ce modèle car l’initialisation des poids est aléatoire et si lors de la mise à jour des poids au cours de l’entraînement, on a égalité des poids des deux modèles et absence de bruits, notre modèle va s’effondrer. En effet, on aura dans l’expression de J, la minimisation de la différence entre une fonction et elle-même ce qui conduit à une solution triviale du type f=0.
La mise à jour des poids obéit à la moyenne exponentielle mobile c’est-à-dire :
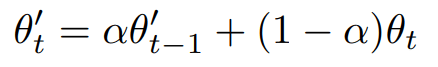
La méthode FIXMATCH
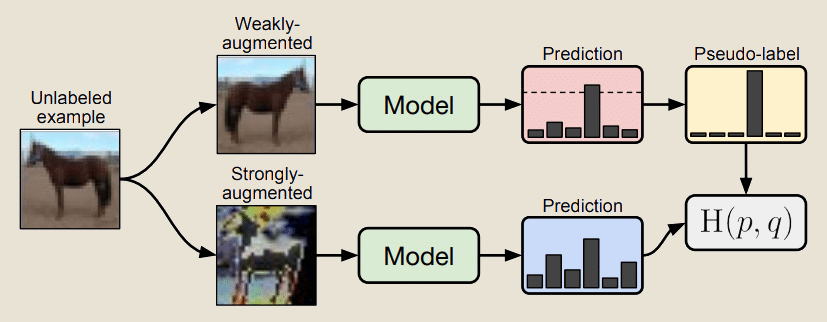
La méthode FixMatch est un autre algorithme utilisé dans cette technique d’apprentissage qui se base également sur la régularisation de consistance pour effectuer des prédictions. En effet, à l’issue de l’apprentissage supervisé, elle réalise des augmentations forte et faible des images non labellisées et l’objectif au cours de l’entraînement de ce modèle c’est que les prédictions des versions augmentées et non augmentées d’une même image soient les mêmes d’où la notion de consistance.
À quoi sert l’apprentissage semi-supervisé ?
L’apprentissage semi-supervisé est utilisé de nos jours dans divers domaines pour résoudre des problèmes dans lesquels on ne dispose pas d’assez de données labellisées. On pourrait citer en guise d’exemples le problème de détection de fraudes dans le secteur bancaire, le problème de classification des pages web en catégories ou le correcteur automatique.
En résumé, l’apprentissage semi-supervisé est une technique utilisée en Deep Learning qui est au cœur de la résolution de plusieurs problèmes concrets aujourd’hui. De nombreuses méthodes parmi lesquelles la méthode de proxy-label, les algorithmes génératifs et la méthode de régularisation de consistance ont été développées à cet effet.








