
Parmi les nombreuses attaques informatiques qui existent et qui s’attaquent aux systèmes informatiques, le Data Poisoning se caractérise par la falsification des données d’entraînement des modèles de Machine Learning. Qu’est-ce que cela signifie ? Est-ce que cela représente un réel danger ? Voici un petit aperçu de cette attaque particulière, des menaces qui en découlent et moyens de s’en défendre.
Qu'est-ce que le Data Poisoning ?
Les attaques de Data Poisoning sont apparues avec l’arrivée massive des modèles de Machine Learning à la fin du XXème siècle.
Ces attaques interviennent à la phase d’entraînement des modèles de machine learning. Un modèle de machine learning doit effectivement être entraîné avec des données pour fonctionner. Progressivement, le modèle de machine learning va apprendre de ses erreurs et effectuer sa tâche de plus en plus précisément.
Un modèle prédictif est un programme informatique qui va être capable d’effectuer une tâche particulière comme reconnaître
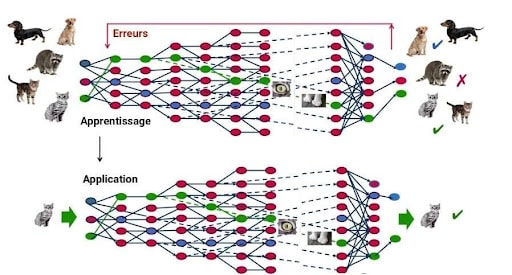
Mais l’attaque de Data Poisoning en agissant sur la phase d’entraînement va altérer, voire fausser complètement les résultats du modèle prédictif. L’exemple des attaques dirigées contre le système antispam de Google entre 2017 et 2018 montre bien comment elles agissent. Le modèle antispam de Google est entraîné avec des données qu’on appelle des paires input / étiquette.
L’input est un email ou un message textuel et l’étiquette indique si le message est un spam ou non.
C’est ici que l’attaque de Data Poisoning intervient. Elle va corrompre et falsifier massivement ces données d’entraînement en indiquant par exemple qu’un spam n’en est pas un. Cette attaque va altérer la précision du modèle de machine Learning. Dans le cas de Google, les spammeurs se frottent alors les mains : ils peuvent envoyer des spams sans que le modèle antispam de Google le notifie. Les attaques de Data Poisoning peuvent également agir sur les modèles de reconnaissance des panneaux de signalisation, utilisés pour les voitures autonomes par exemple. Si ce modèle est empoisonné, il pourrait très bien confondre un panneau stop et panneau limitation de vitesse.

Cette attaque est devenue très accessible aux moindres hackers. Précédemment, les attaques de Data Poisoning étaient difficiles à mettre en place parce qu’elles supposaient une forte puissance de calcul, du temps et de l’argent. Mais de nouvelles techniques permettent de contourner ces obstacles. La technique TrojanNet backdoor est particulièrement problématique. Cette technique, en créant un réseau de neurones qui détecte une série de patches, n’a pas besoin d’accéder au modèle original, et elle peut être effectuée par un ordinateur de base.
Quels sont les dangers du Data Poisoning ?
Le fait qu’une attaque de Data Poisoning soit devenue très accessible, en fait un véritable danger. Une fois que la phase d’entraînement du modèle est terminée, il est très difficile de corriger le modèle de machine Learning. Il faudrait faire une longue analyse de tous les inputs ayant entraîné le modèle, détecter les inputs frauduleux, et les supprimer. Mais si la masse de données est trop importante, cette analyse est tout simplement impossible. La seule solution est alors d’entraîner à nouveau le modèle.
Mais ces phases d’entraînement peuvent être extrêmement coûteuses : dans le cas du système d’intelligence artificielle GPT-3 développé par Open IA, la phase d’entraînement a coûté environ 16 millions d’euros…
Au-delà d’un simple coût économique, le Data Poisoning peut représenter un danger encore plus grand. L’intelligence Artificielle et les modèles de machine learning prennent une place toujours plus importante dans nos sociétés et sont utilisés pour les tâches de la plus haute importance, comme la santé, les transports, les enquêtes criminelles. Par exemple, la police de Chicago utilise l’IA pour lutter contre le crime, pour prévoir où et quand les crimes violents éclateront. Que se passe-t- il si les données de leurs modèles sont empoisonnées ? La lutte contre le crime devient inefficace, et les modèles dirigent les policiers vers de fausses pistes.
Comment se protéger du Data Poisoning ?
Heureusement, il existe des moyens pour lutter contre le Data Poisoning.
- Une première technique consiste à contrôler les bases de données avant de les injecter dans les données d’entraînement du modèle. On peut pour cela utiliser des méthodes statistiques pour détecter les anomalies dans les données, des tests de régression ou encore la modération manuelle.
- On peut également repérer toute baisse de performance du modèle durant la phase d’entraînement et réagir aussitôt, grâce à des outils cloud comme Azure Monitor ou Amazon SageMaker.
- Enfin, comme l’empoisonnement des données suppose une connaissance préalable du modèle, il faut garder les informations de fonctionnement du modèle secrètes durant la phase d’entraînement.
Le Data Poisoning représente donc une réelle menace informatique, et d’autant plus que ces attaques sont de plus en plus accessibles aux hackers. Mais face aux progrès techniques des hackers le défi réside dans le progrès des systèmes de prévention. Le Data Scientist et le Data Engineer sont en première ligne pour combattre ces attaques. Ce sont eux qui vont devoir collecter des données sûres ou détecter des attaques pendant les phases d’entraînement. Si vous voulez en savoir plus sur le fonctionnement et la protection de ces modèles, allez jeter un coup d’œil à nos formations dans les métiers de la data.









