
Data Frame: Panda ist aus den Bibliotheken von Python nicht mehr wegzudenken. Es handelt sich um eine objektorientierte, sehr leistungsfähige Programmiersprache, die bei Data Scientists sehr beliebt ist. Die am häufigsten verwendeten Strukturen dieser Programmbibliothek sind Series und DataFrames. Bei Series handelt es sich um Objekte, die eindimensionalen Arrays entsprechen. Bei DataFrames hingegen entsprechen die Objekte zweidimensionalen Arrays, die aus Zeilen und Spalten bestehen, wodurch die Beziehungen zwischen den verschiedenen Variablen des Datensatzes hervorgehoben werden können.
Ein Data Frame ist eine Reihe von Pandas Series, die durch einen Wert indiziert sind. In diesem Artikel werden wir dann die Struktur von DataFrames vorstellen, ihre verschiedenen Attribute und grundlegenden Methoden betrachten, indem wir ihre Nützlichkeit und ihre Funktionsweise erläutern.
1) Wie sieht ein Data Frame aus ?
Das Format von DataFrame kann mit Python-Wörterbüchern verglichen werden. Tatsächlich sind die Schlüssel die Spaltennamen und die Werte die Serien.
Die Struktur von DataFrame ist einer Excel-Tabelle ähnlich.
Jede Zeile enthält Daten, die für verschiedene Spalten spezifisch sind. Diese Spalten sind die Variablen. Der Name der Zeilen eines DataFrames heißt „Index“, der standardmäßig immer mit 0 beginnt.
Es ist jedoch möglich, die Zeilen eines DataFrames nach jedem möglichen Wert zu indizieren: Kundenkennung oder Zeiteinheit. Die Namen der Spalten sind mit dem Namen einer bestimmten Variablen gekennzeichnet, der verschiedene Werte zugewiesen werden.
Die Werte dieser Variablen können viele Datenformate annehmen. Jede Spalte ist einem Datentyp zugeordnet, beispielsweise einer Zeichenfolge (Objekt), die sich auf qualitative Daten bezieht, oder einer Spalte mit einem ganzzahligen Typ, der ganzen Zahlen entspricht.
Es ist möglich, den Typ der Variablen mit der Methode astype() nach Bedarf zu ändern.
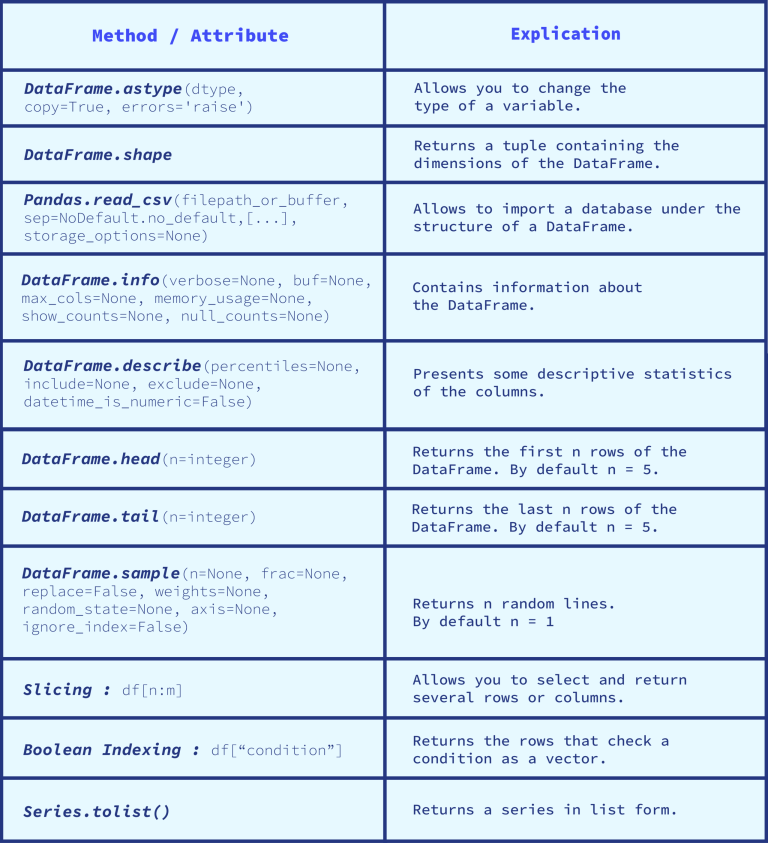
2) Wichtige Attribute und Methoden
Es gibt viele Möglichkeiten, DataFrames zu verwenden. Die Attribute und Methoden dieser Daten-Struktur sind sehr zahlreich. Dieser Artikel konzentriert sich hauptsächlich auf die grundlegenden Methoden zum Erlernen des Umgangs mit DataFrames.
A- Import und Beobachtung des Datensatzes
Import und Information von Variablen
Um einen Datensatz zu importieren, bietet die Pandas-Bibliothek eine sehr praktische Methode, nämlich pd.read_csv(). Wenn die Datei, die den Datensatz enthält, in einem anderen Format als Comma Separated Value vorliegt, muss der richtige Dateityp gewählt werden.
Beispielsweise wird eine Excel-Datei wie folgt importiert: pd.read_excel().
Diese Methode importiert das Dataset in eine DataFrame-Struktur.
Dann muss die Methode info() verwendet werden, um die Informationen über den DataFrame zu erhalten. Diese Methode gibt den Variablentyp, die Anzahl der Spalten, die Anzahl der Nicht-Null-Zeilen, den Indextyp, die Speichergröße des Datensatzes usw. zurück.
Es wird auch empfohlen, die Methode describe() zu verwenden, die Dir einige beschreibende Statistiken über den DataFrame mitteilt.
Es ermöglicht beispielsweise, den Mindest- und Höchstwert jeder Variablen, die Quartile oder die Standardabweichung der Spalten zu kennen.
Diese Methode ist nützlich, um sich ein Bild von der Verteilung von Variablen zu machen.
💡Auch interessant:
Erster Blick auf den DataFrame
Wenn der Datensatz importiert wird, ist es notwendig, einen Überblick über den DataFrame zu haben.
Der erste Schritt besteht darin, das Attribut shape zu verwenden, das Dich über die Dimension des DataFrame informiert, indem es ein Tupel zurückgibt (number_of_rows, number_of_columns).
In Bezug auf das Verständnis des Datensatzes sind drei Methoden sehr nützlich, um die Zeilen des DataFrame zu visualisieren:
- Die Methode head() gibt die ersten fünf Zeilen des DataFrame zurück, wenn keine Zahl in Klammern angegeben ist.
- Hingegen kannst Du mit der Methode tail() die letzten fünf Zeilen des DataFrame anzeigen.
Diese beiden Methoden ermöglichen eine Visualisierung des Beginns und des Endes des Datensatzes. Dies hat einen echten Vorteil für Daten vom Typ Times Series, um eine einfache Vorstellung von der Entwicklung der Daten im Laufe der Zeit zu haben.
Es ermöglicht überhaupt zu sehen, ob die Daten eine bestimmte Bedeutung behalten: Wenn der Beginn der DataFrame sich erheblich vom Ende des letzteren unterscheidet, ist es notwendig, die Ursache zu verstehen und zu versuchen, dieses Problem zu lösen, bevor Daten manipuliert werden.
- Wenn eine eher zufällige Visualisierung von Zeilen gewünscht wird, sollte die Methode sample() bevorzugt werden. Es gibt Zeilen zufällig zurück. Standardmäßig gibt das Ergebnis nur eine Zeile des DataFrame zurück.
- Es ist also besser, eine Ganzzahl in die Klammer zu schreiben, um eine größere Anzahl von Zeilen anzuzeigen und somit eine bessere Vorstellung vom Inhalt des DataFrame zu bekommen.
Slicing
Wir können unsere Daten mit Slice filtern. Beispielsweise gibt df[:2] die ersten beiden Zeilen unseres DataFrame zurück.
Sei aber vorsichtig: Wir dürfen nicht vergessen, dass die letzte Zahl exogen ist.
Dies bedeutet, dass das Slicing in unserem Beispiel die Zeilen bei Index 0 und 1 zurückgibt.
B- Datenmanipulation
Daten hinzufügen und ändern
Wie in der Einleitung erklärt, sind DataFrames zweidimensionale Arrays, die den Achsen von Zeilen (Achse = 0) und Spalten (Achse = 1) entsprechen.
Es ist möglich, so viele Zeilen oder Spalten wie nötig hinzuzufügen, indem Du die Achse angibst, in der wir diese neuen Werte hinzufügen möchten.
Das Interessante an DataFrames ist, dass es sehr einfach ist, Daten in dieser Struktur abzurufen, zu ändern, zu laden oder zu suchen. Stellen wir uns einen nach Zeit indizierten DataFrame vor.
Wir möchten alle Daten vom 18. Dezember 2020 abrufen. Mit der Funktion iloc ist es möglich, alle variablen Daten an diesem Datum abzurufen.
Außerdem ist es möglich, mit dieser Funktion einen Wert einer der Spalten zu ersetzen, indem der Index und der Name der Spalte angegeben werden.
Beispielsweise fehlt der Wert am 18. Dezember 2020 ; wir aber wissen, dass der tatsächliche Wert 25 ist. Du kannst einfach df.iloc[Index_der_Zeile, „columns“] = 25 eingeben.
Boolean Indexing
Es ist möglich, die Daten nach einer oder mehreren Bedingungen zu filtern. Damit kann man spezifische Daten und/oder bestimmte Daten für einen bestimmten Bedarf abrufen und alle nützlichen und notwendigen Informationen anzeigen.
Dies wird als Boolean Indexing bezeichnet. Mit dieser Technik kann man wissen, ob der Wert eines Tests wahr oder falsch ist. Das Ergebnis wird in Form eines Vektors zurückgegeben. Beispielsweise haben wir einen Datensatz, in dem jede Spalte ein Monat des Jahres ist. Der Typ des DataFrame ist DateTimeIndex.
Wir möchten die Zeilen abrufen, in denen der Monat Januar streng größer als 25 ist. So schreiben wir den Code: df[df[„Januar“] > 25].
Diese Methode des Boolean Indexing filtert die Daten, um nur die Zeilen zurückzugeben, die die Bedingung „Werte größer als 25 für den Monat Januar“ erfüllen. Im Allgemeinen wird Boolean Indexing in folgendem Format geschrieben: df[„Bedingung“].
Die Spalten
DataFrames werden verwendet, um große Datenmengen zu bearbeiten und zu speichern. In einem professionellen Umfeld werden jedoch regelmäßig riesige Datenmengen mit sehr vielen Variablen verarbeitet.
Die Erhöhung der Anzahl der Variablen wirkt sich insbesondere auf die Organisation von DataFrames aus.
Je höher die Anzahl der Spalten, desto weniger einfach ist es, die Namen der Variablen zu visualisieren.
Um dieses Problem zu lösen, gibt es mehrere mögliche Manipulationen.
Wenn der DataFrame zehn verschiedene Variablen hat, ist es möglich, ihre Namen mit dem Attribut df.columns herauszufinden.
Wenn der Datensatz jedoch achthundert Spalten hat, wird die Anzeige der Variablennamen nicht vollständig sein.
Um dieses Problem zu lösen, ist es möglich, die Methode df.columns.toList() zu verwenden, mit der Du die Spaltennamen in einer Python-Liste speichern kannst.
Um herauszufinden, ob es Zeilen gibt, die nicht eindeutig und möglicherweise Duplikate sind, ist die Methode df[„columns“].value_counts() eine einfache Möglichkeit, dies zu überprüfen.
Wenn wir es gewohnt sind, mit Tabellen zu arbeiten, ist es zur besseren Lesbarkeit möglich, to_frame() am Ende des Codes hinzuzufügen, um die Ergebnisse im Format eines DataFrame anzuzeigen.
Diese Methode von value_counts() ermöglicht es, das Auftreten der Modalitäten einer Variablen zu erfahren.
Fehlende Werte
Bei der Arbeit an einem Data-Science-Projekt kommt es häufig vor, dass man sich mit fehlenden und/oder falschen Werten befasst.
DataFrames lösen dieses Problem sehr einfach. Beispielsweise besteht bei qualitativen Daten eine der Methoden zum Ersetzen fehlender Werte darin, Daten nach dem Kategoriemodus zu verarbeiten.
Verwende einfach den folgenden Code, um diese Manipulation zu erreichen: df[column].fillna(df[columns].mode()[0]). Man kann zum Beispiel auch quantitative Werte durch den Mittelwert ersetzen.
So ermöglichen DataFrames, Korrelationen und Beziehungen zwischen Daten dank der verschiedenen möglichen Manipulationen zu verbessern, Filter für die den Teams präsentierten Daten zu definieren, riesige Datenmengen zu speichern und zu manipulieren.
Zusammenfassend lässt sich sagen, dass DataFrames es Data Scientists ermöglichen, die Bedeutung von ihren Daten zu verstehen, indem sie über die durchzuführenden Bedingungen und Verwendungen entscheiden.
Wenn Du lernen möchtest, welche Bedeutung Daten haben, sind unsere Data Science Ausbildungen genau das Richtige für Dich!







