
In den beiden vorherigen Artikeln haben wir ein erstes Beispiel für die Programmierung einer Web-API unter Flask gesehen und wie man eine Web-API mit einer SqLite-Datenbank verbindet.
Im Folgenden werden wir sehen, wie man REST-APIs mit Input- und Output-Validierung und automatisch erstellter Dokumentation von Swagger/OpenAPI baut. Wir werden auch sehen, wie die API mit JavaScript verwendet werden kann, um das DOM (Document Object Model), d. h. die Struktur der angezeigten Webseite, zu aktualisieren.
Die REST-API, die wir bauen werden, wird es ermöglichen, ein Personenverzeichnis zu manipulieren, wobei die Personen durch ihre Nachnamen identifiziert werden. Aktualisierungen werden mit einem „Timestamp“ (Datum/Uhrzeit) markiert.
Man könnte das Verzeichnis in Form einer Datenbank, einer Datei oder über ein Netzwerkprotokoll manipulieren, aber um die Dinge zunächst zu vereinfachen, werden wir Daten im Speicher verwenden.
Eines der Ziele von APIs ist es, die Daten von den Anwendungen, die sie nutzen, zu entkoppeln, indem die Details der Datenimplementierung transparent gemacht werden.
1. Die REST Methode
Die REST-Methode wurde im ersten Artikel erwähnt. Nun wollen wir sie genauer betrachten.
REST kann als eine Reihe von Konventionen betrachtet werden, die das HTTP-Protokoll nutzen, um CRUD-Tools (Create, Read, Update, Delete) bereitzustellen, die mit Entitäten oder Sammlungen von Entitäten im Internet arbeiten.
CRUD kann wie folgt auf HTTP abgebildet werden:
Du kannst jede dieser Aktionen an einer Entität oder einer Ressource durchführen.
Eine Ressource kann man sich als eine Entität vorstellen, der man einen Namen zuordnen kann: eine Person, eine Adresse, eine Transaktion.
Die Idee einer Ressource kann mit der Idee einer URL in Verbindung gebracht werden, wie im ersten Artikel beschrieben.
Eine URL muss eine einzigartige Ressource im Web identifizieren, etwas, das immer mit derselben URL übereinstimmt.
Mit den Konzepten der Ressource und der URL sind wir in der Lage, Anwendungen zu entwerfen, die auf eindeutig identifizierte Dinge im Web einwirken.
Dies ist ein erster Schritt auf dem Weg zur Entwicklung von eigentlichen APIs, die es ermöglichen, die gewünschten Aktionen über das Netz auszuführen.
2.Was REST nicht ist
Da die REST-Methode sehr nützlich ist und dabei hilft, die Art und Weise zu entwickeln, wie man mit einer API interagiert, wird sie manchmal fälschlicherweise für Probleme verwendet, für die sie nicht geeignet ist.
In vielen Fällen möchte man eine Aktion direkt ausführen. Nehmen wir als Beispiel das Ersetzen einer Zeichenkette.
Hier ist ein Beispiel für eine URL, die dies auf den ersten Blick ermöglicht:
/api/substituteString/<string>/<search_string>/<sub_string>
Hier bezeichnet, die Zeichenkette, die ersetzt werden soll, ist die zu ersetzende Teilzeichenkette und ist die neue Teilzeichenkette.
Man kann sicherlich einen Code auf dem Server entwerfen, mit dem die gewünschte Operation durchgeführt werden kann, aber das wirft in Bezug auf REST einige Probleme auf.
- Erstes Problem: Die URL verweist nicht auf eine einzelne Ressource; was sie zurückgibt, hängt also vollständig vom angegebenen Pfad ab.
- Zweites Problem: Es gibt kein CRUD-Konzept, das zu dieser URL passt.
- Drittes Problem: Die Bedeutung der Pfadvariablen hängt von ihrer Position in der URL ab.
Dies könnte behoben werden, indem die URL so geändert wird, dass eine Abfrage :
/api/substituteString? string=<string>&search_string=<search_string>&sub_string=<sub_string>.
Aber der URL-Teil /api/substituteString bezeichnet keine Entität (kein Name) oder eine Sammlung von Entitäten.
Sammlung von Entitäten: Er bezeichnet eine Aktion (es ist ein Verb).
Dies entspricht nicht den REST-Konventionen und ist daher keine API. Was die vorherige URL darstellt, ist in Wirklichkeit ein RPC (Remote Procedure Call).
Es ist sinnvoller, das, was du tun willst, als RPC zu konzeptualisieren. Dies gilt umso mehr, als die REST- und RPC-Konventionen innerhalb einer API problemlos koexistieren können.
3. Erste Schritte
Im folgenden Beispiel soll eine REST-API entwickelt werden, mit der du auf ein Personenverzeichnis zugreifen und CRUD-Operationen darauf ausführen kannst.
Hier ist das Design der API :
Wir beginnen damit, einen sehr einfachen Webserver mithilfe des Flask-Entwicklungsframeworks zu erstellen.
Wir erstellen ein Verzeichnis api, ein Unterverzeichnis version_1 und dann ein Unterverzeichnis templates, in dem wir die folgenden Programme speichern:
server.py
templates/home.html
Das HTML-Programm heißt home.html und nicht wie üblich index.html, da index.html Probleme bereitet, wenn man das Modul Login importiert, was wir im Folgenden tun werden.
Wir starten ein Terminal-Fenster, wechseln in das Verzeichnis projects/api/version_1 und starten die Anwendung, indem wir nacheinander Folgendes eingeben:
- $ export FLASK_APP = server.py
- $ export FLASK_ENV = development
- $ flask run
Das folgende Ergebnis erhält man, wenn man http://127.0.0.1:5000 in die Browserleiste eingibt:
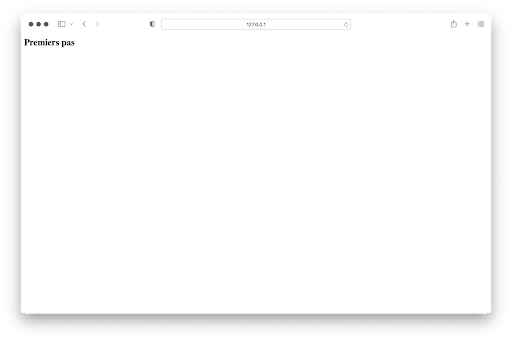
4. Connexion
Nachdem wir nun einen funktionierenden Webservice haben, fügen wir einen REST API Endpunkt hinzu. Zu diesem Zweck installieren wir das Modul Connection.
Dazu gibst du in einem Terminalfenster ein (dies setzt voraus, dass du unter Anaconda arbeitest):
$ conda install -c conda-forge Connection.
Nun können wir das Modul in Python importieren.
Wir erstellen dann ein Unterverzeichnis version_2 im Verzeichnis api und speichern dort die folgenden Programme:
server.py
swagger.yml
Um Connexion zu verwenden, importieren wir es zunächst und erstellen dann die Anwendung mithilfe von Connexion statt mit Flask. Die Flask-Anwendung wird trotzdem unterschwellig erstellt, jedoch mit zusätzlichen Funktionen.
Die Erstellung der Instanz der Anwendung enthält einen Parameter specification_dir. Er teilt Connexion mit, wo die Konfigurationsdatei zu finden ist, hier das aktuelle Verzeichnis.
Die Zeile app.add_api (’swagger.yml‘) weist die Instanz an, die Datei swagger.yml im specification_dir zu lesen und das System für Connexion zu konfigurieren.
Die Datei swagger.yml ist eine YAML- (oder JSON-) Datei, die die notwendigen Informationen für die Konfiguration des Servers enthält, um die Validierung der Inputs und Outputs zu gewährleisten, die Anfrage-URLs bereitzustellen und die Swagger-Benutzeroberfläche (UI) zu konfigurieren.
Der vorherige Code definiert die GET / api/people-Anfrage. Der Code ist hierarchisch organisiert, wobei die Einrückung den Grad der Zugehörigkeit oder Reichweite definiert.
Zum Beispiel definiert paths die Wurzel aller API-URLs. Der nachträglich eingerückte Wert /people definiert die Wurzel aller /api/people-URLs. Das nachträglich eingerückte get: definiert eine GET-Anfrage an die URL /api/people, und so weiter für die gesamte Konfigurationsdatei.
In der Datei swagger.yml wird Connection mit dem Wert operationId konfiguriert, um das Modul people und die Funktion read dieses Moduls aufzurufen, wenn die API eine HTTP-Anfrage vom Typ GET /api/people erhält. Das bedeutet, dass ein Modul people.py existieren und eine read( )-Funktion enthalten muss.
Hier ist das Modul people.py :
people.py
Im Modul people.py erscheint zunächst die Funktion get_timestamp( ), die eine Darstellung des aktuellen Datums/der aktuellen Uhrzeit in Form einer Zeichenkette erzeugt. Sie wird verwendet, um die Daten zu ändern, wenn eine Änderungsanforderung an die API gesendet wird.
Als Nächstes definieren wir ein PEOPLE-Wörterbuch, das eine einfache Namensdatenbank ist, die als Schlüssel den Nachnamen hat.
PEOPLE ist eine Modulvariable und ihr Status bleibt daher zwischen den API-Aufrufen bestehen.
In einer echten Anwendung würden sich die PEOPLE-Daten in einer Datenbank, einer Datei oder einer Webressource befinden, d. h. sie würden unabhängig von der Ausführung der Anwendung bestehen bleiben.
Als nächstes kommt die Funktion read( ), die aufgerufen wird, wenn der Server eine HTTP-GET-Anfrage nach /api/people erhält.
Der Rückgabewert dieser Funktion wird in das JSON-Format umgewandelt (wie von produces: in der Konfigurationsdatei swagger.yml angegeben).
Er besteht aus der Liste der Personen, die alphabetisch nach Nachnamen sortiert ist. An dieser Stelle können wir das Programm server.py mit dem Befehl :
$ python server.py
was zu folgendem Ergebnis führt, wenn man als Adresse http://0.0.0.0:8080/api/people in die Leiste des Browsers eingibt:
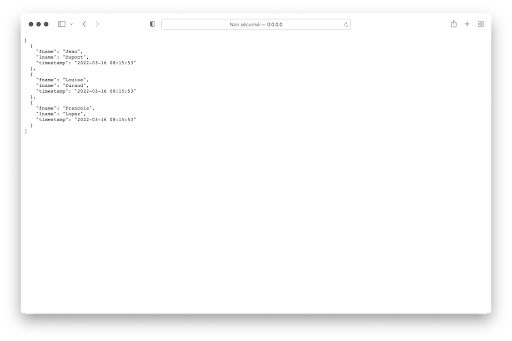
5. Swagger/OpenAPI
Wir haben also eine einfache API gebaut, die eine einzige Anfrage zulässt. Es stellt sich jedoch die Frage, wie man das gleiche Ergebnis auf viel einfachere Weise mit Flask erreichen kann, wie wir in unserem ersten Artikel gesehen haben:
Was bringt die Konfiguration mithilfe der Datei swagger.yml?
Zusätzlich zur API wurde von Connexion eine Swagger-Benutzeroberfläche (OpenAPI) erstellt. Um darauf zuzugreifen, gib einfach http://localhost:8080/api/ui ein.
Man erhält folgendes Ergebnis:
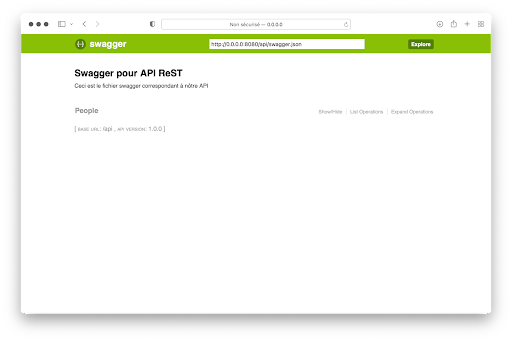
Wenn du auf People klickst, erscheint die potenzielle Abfrage :
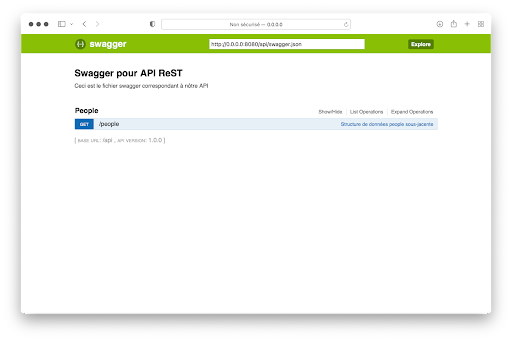
Wenn Du auf die Anfrage klickst, werden die folgenden zusätzlichen Informationen von der Schnittstelle angezeigt:
- Die Struktur der Antwort
- Das Format der Antwort (content-type)
Der Text, der in swagger.yml über die Anfrage eingegeben wurde.
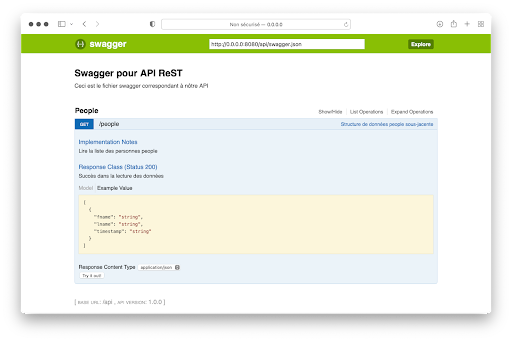
Man kann die Abfrage sogar ausprobieren, indem man auf die Schaltfläche Try It Out! am unteren Rand des Bildschirms klickt.
Die Schnittstelle erweitert die Anzeige noch weiter und man erhält als Ergebnis :
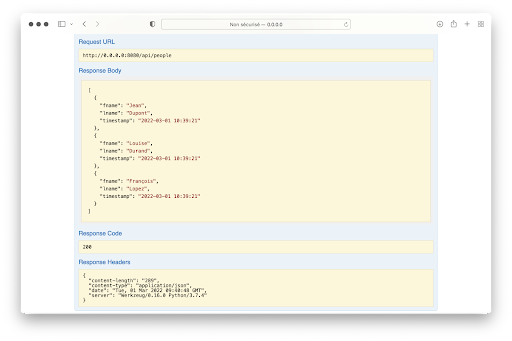
All das ist sehr nützlich, wenn du eine vollständige API hast, da es dir erlaubt, mit der API zu testen und zu experimentieren, ohne Code zu schreiben. Die Swagger/OpenAPI-Schnittstelle ist nicht nur praktisch, um auf die Dokumentation zuzugreifen, sondern hat auch den Vorteil, dass sie aktualisiert wird, sobald die Datei swagger.yml aktualisiert wird.
Außerdem bietet die swagger.yml-Datei einen methodischen Weg, um alle Abfragen zu entwerfen, was ein rigoroses API-Design sicherstellt. Schließlich ermöglicht sie es, den Python-Code von der Konfiguration der Abfragen zu entkoppeln, was sehr nützlich sein kann, wenn man APIs entwirft, die Webanwendungen unterstützen. Ein Beispiel dafür wird im Folgenden gezeigt.
6. Komplette API
Unser Ziel war es, eine API zu erstellen, die CRUD-Zugriff auf unsere PEOPLE-Daten bietet. Zu diesem Zweck ergänzen wir die Konfigurationsdatei swagger.yml und das Modul people.py, um die Spezifikationen unserer API zu erfüllen.
Die ergänzten Dateien sind im Unterverzeichnis version_3 auf GitHub verfügbar: https://github.com/salimlardjane1/projects/tree/version_3.
Die Ausführung von server.py ergibt dann in Bezug auf die Swagger/OpenAPI-Schnittstelle :
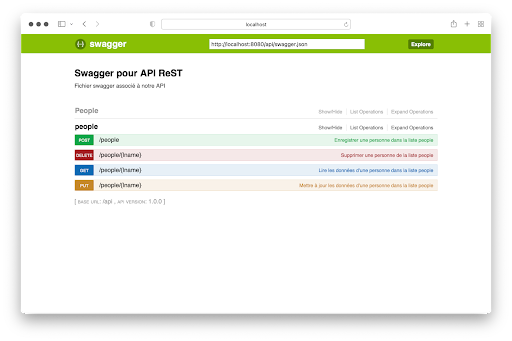
Die vorherige Schnittstelle ermöglicht den Zugriff auf die Dokumentation in der Datei swagger.yml und die Interaktion mit allen URLs, die die CRUD-Funktionen der API implementieren.
7. Web App
Wir haben jetzt eine dokumentierte REST-API, mit der wir mithilfe von Swagger/OpenAPI interagieren können.
Wie geht es weiter?
Der nächste Schritt besteht darin, eine Webanwendung zu erstellen, die die konkrete Verwendung der API veranschaulicht.
Wir erstellen eine Webanwendung, die die Personen in der Datenbank auf dem Bildschirm anzeigt und es ermöglicht, Personen hinzuzufügen, die Daten der Personen zu aktualisieren und Personen aus der Datenbank zu löschen. Dies geschieht mithilfe von AJAX-Anfragen, die von JavaScript an die URLs unserer API gesendet werden.
Als Erstes müssen wir die Datei home.html, die die Struktur und das Aussehen der Startseite der Webanwendung steuert, wie folgt ergänzen:
Die Datei home.html ist auf GitHub verfügbar:
Im Unterverzeichnis templates des Verzeichnisses version_4.
Das HTML-Programm ergänzt das ursprüngliche home.html-Programm um einen Aufruf der externen Datei normalize.min.css (https:// necolas.github.io/normalize.css/), mit der die Darstellung in verschiedenen Browsern standardisiert werden kann.
Außerdem wird die Datei jquery-3.3.1.min.js (https:// jquery.com) verwendet, die die jQuery-Funktionen in JavaScript zur Verfügung stellt. Diese werden verwendet, um die Interaktivität der Seite zu programmieren.
Der HTML-Code definiert den statischen Teil der Anwendung. Die dynamischen Teile werden von JavaScript eingebracht, wenn auf die Seite zugegriffen wird und wenn der Nutzer mit ihr interagiert.
Die Datei home.html verweist auf zwei statische Dateien: static/css/home.css und static/js/home.js. Das Verzeichnis mit dem Namen static wird von der Flask-Anwendung sofort erkannt und der Inhalt der Verzeichnisse css und js ist somit von der Datei home.html aus zugänglich.
Die Dateien home.css und home.js sind auf GitHub verfügbar:
Wir werden im nächsten Artikel mehr über CSS und JavaScript sprechen.
Wenn man in das Verzeichnis version_4 wechselt und server.py ausführt, erhält man im Browser folgendes Ergebnis:
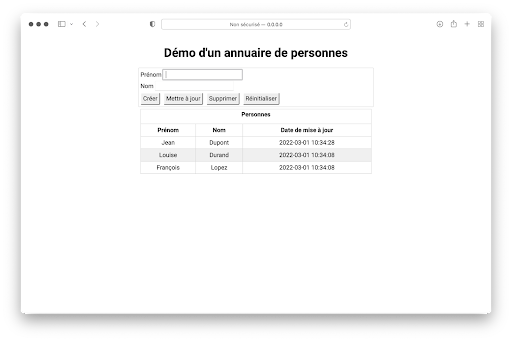
Mit der Schaltfläche Erstellen kann der Nutzer eine Person zum Katalog auf dem Server hinzufügen.
Ein Doppelklick auf eine Zeile in der Tabelle lässt den Vor- und Nachnamen in den Eingabefeldern erscheinen.
Um zu aktualisieren, muss der Nutzer den Vornamen ändern, da der Name der Suchschlüssel ist.
Um eine Person aus dem Verzeichnis zu entfernen, klicke einfach auf Löschen.
Zurücksetzen leert die Eingabefelder.
Damit haben wir eine kleine, funktionierende Webanwendung gebaut.
Wie sie funktioniert, werden wir im nächsten Artikel genauer betrachten.
8. Bibliografische Referenzen
- Creating Web APIs with Python and Flask, Patrick Smyth, 2022 : https://programminghistorian.org/en/lessons/creating-apis-with-python-and-flask.
- Python REST APIs With Flask, Connexion, and SQLAlchemy, Doug Farrell, 2022 : https://realpython.com/flask-connexion-rest-api/.
- Python REST APIs With Flask, Connexion, and SQLAlchemy, Doug Farrell, 2022 : https://realpython.com/flask-connexion-rest-api-part-2/.
- Flask RESTful documentation, 2020 : https://flask-restful.readthedocs.io/en/latest/index.html.
- Flask Web Development : Developing Web Applications with Python (2ème édition). M. Grinberg. O’Reilly 2018.
- Architectural Styles and the Design of Network-Based Software Architectures. T. Fielding. Thèse, Université de Californie, 2000.







