Data Science
MOOC: Wer oder was ist das ?
Ein MOOC (Abkürzung für Massive Open Online Course) ist eine Art von Online-Kurs, der für alle offen ist. Diese Kurse sind sehr populär geworden, da
Ein MOOC (Abkürzung für Massive Open Online Course) ist eine Art von Online-Kurs, der für alle offen ist. Diese Kurse sind sehr populär geworden, da

Style Transfer: Hast Du Dir jemals gewünscht, wie Van Gogh malen zu können? Die Ästhetik von Monet in modernen Landschaften wiederzugeben? In diesem Artikel stellen
In diesem Artikel stellen wir dir drei nichtparametrische statistische Tests vor und erläutern anhand von Beispielen, in welchen Situationen sie eingesetzt werden können. Nichtparametrische Tests:
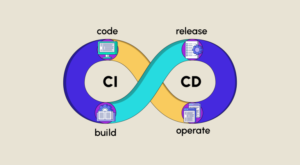
Continuous Integration (CI) und Continuous Delivery (CD) fassen eine Reihe von Prinzipien und Praktiken zusammen, die es Entwicklungsteams ermöglichen, Änderungen am Computercode zuverlässiger und häufiger

Das ACID-Konzept (Atomicity, Coherence, Isolation, Durability) stellt die Datenintegrität innerhalb einer Datenbank sicher. Hier erfährst Du alles, was Du über dieses Konzept wissen musst. Big
Deep Learning vs. Machine Learning: Die Datenanalyse ist heute ein Schlüsselfaktor bei der Entscheidungsfindung von Unternehmen. Diese Daten müssen vorverarbeitet und mithilfe von Künstlicher Intelligenz

In einem anderen Artikel haben wir über die Grenzen der künstlichen Intelligenz im Vergleich zum menschlichen Gehirn gesprochen. Wenn die Initiative in diesem Vergleich ausschlaggebend

Obwohl die Begriffe „Datenverletzung“ und „Data Leak“ oft austauschbar verwendet werden, handelt es sich dabei um zwei verschiedene Arten der Datenexposition: Eine Datenverletzung tritt auf,

Angesichts der zunehmenden Cyberkriminalität ist die Cybersicherheit für Unternehmen aller Branchen zu einer entscheidenden Herausforderung geworden. Hier erfährst Du alles Wichtige, was du über Cybersicherheit
Eine GPU oder „Graphics Processing Unit“ ist die Komponente eines Computers, die die Darstellung von Bildern auf dem Bildschirm ermöglicht. Es handelt sich dabei um
Imageio ist eine Python-Bibliothek für die Verarbeitung von Bilddaten. Hier erfährst Du alles, was Du wissen musst, um Imageio zu beherrschen: Funktionsweise, Befehle, Installation, Schulungen…

GitLab ist ein Code-Hosting- und Versionsverwaltungsservice, der mit einer kompletten DevOps-Plattform gepaart ist. Hier erfährst du alles, was du darüber wissen musst: Funktionsweise, Unterschiede zu
