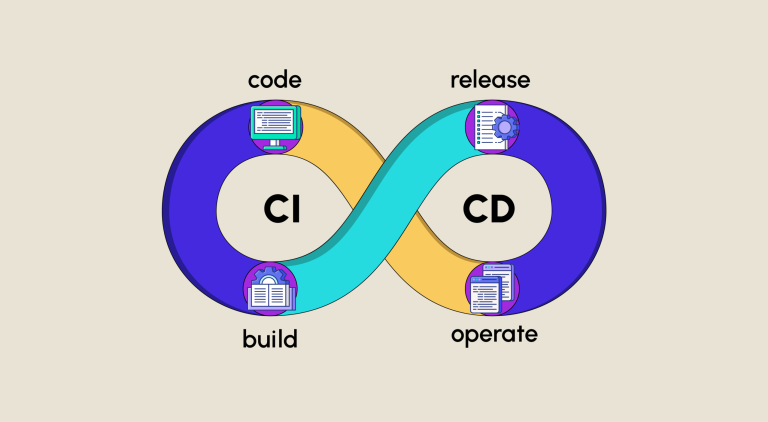
Continuous Integration (CI) und Continuous Delivery (CD) fassen eine Reihe von Prinzipien und Praktiken zusammen, die es Entwicklungsteams ermöglichen, Änderungen am Computercode zuverlässiger und häufiger vorzunehmen.
Die Implementierung von CI/CD ist das Herzstück der agilen und DevOps-Entwicklungsmethoden. Sie ermöglicht es den Softwareentwicklungsteams, sich auf die Geschäftsanforderungen, die Qualität des Codes und die Cybersicherheit zu konzentrieren. Die Einsatzschritte sind automatisiert.
Continuous Integration (CI) und Continuous Delivery (CD): Erklärung
Kontinuierliche Integration ist eine Philosophie und eine Reihe von Praktiken, bei denen Entwicklungsteams Änderungen schrittweise implementieren und den Code vor einer Ergänzung häufig überprüfen.
Moderne Anwendungen basieren auf verschiedenen Tools und Code-Plattformen. Daher benötigen die Teams einen Mechanismus, um Änderungen zu integrieren und zu validieren.
Das Ziel der kontinuierlichen Integration ist es, einen automatisierten Weg einzurichten, um Anwendungen zu bauen und zu testen. Die Beständigkeit des Integrationsprozesses ermöglicht es den Teams, häufiger Änderungen am Code vorzunehmen. Dadurch wird die Zusammenarbeit verbessert und die Qualität der Software erhöht.
Continuous Delivery oder CD ist der nächste Schritt. Sie automatisiert die Auslieferung von Anwendungen an ausgewählte Infrastrukturumgebungen.
Auch hier geht es darum, die Lieferung des Codes zwischen den verschiedenen Produktions-, Entwicklungs- und Testumgebungen zu harmonisieren, an denen die meisten Entwicklungsteams gleichzeitig arbeiten.
Mit CI/CD-Tools können die spezifischen Parameter jeder Umgebung gespeichert werden, und die Automatisierung ermöglicht es dann, die notwendigen Aufrufe an Webserver, Datenbanken und andere Dienste durchzuführen, die Verfahren wie einen Neustart bei der Bereitstellung von Anwendungen erfordern.
Continuous Integration und Continuous Delivery erfordern Continuous Testing. Dadurch wird sichergestellt, dass die Qualität des Codes und der Anwendung aufrechterhalten wird.
Continuous Integration: Wie funktioniert sie?
Die Philosophie der kontinuierlichen Integration beruht auf Mechanismen und Automatisierung. Entwickler legen ihren Code häufig in einem Versionskontrollordner ab, um das Aufspüren von Fehlern und anderen Qualitätsproblemen bei kleinen Codeteilen zu vereinfachen. Dieser Ansatz verringert auch das Risiko, dass mehrere Entwickler denselben Code gleichzeitig bearbeiten.
Verschiedene Techniken werden von CI-Entwicklungsteams verwendet, um den Code und die Funktionen zu kontrollieren. Dazu gehören die Technik der Feature Flags oder die des Version Control Branching. Nach dieser Validierungsphase wird der Code in die Produktion geschickt.
Der Build-Prozess wird durch das Verpacken der gesamten Software, der Datenbanken und anderer Komponenten automatisiert. Auch die Durchführung von Tests wird automatisiert, um den Entwicklern ein Feedback über Änderungen am Code zu geben.
Viele CI/CD-Tools ermöglichen es den Entwicklern, Builds auf Anfrage zu erstellen, indem sie den Code in den Versionskontrollordner oder zu einem bestimmten Zeitpunkt einreichen.
Die Integrationsstrategie sollte vom Team besprochen werden, insbesondere hinsichtlich der Häufigkeit von Builds und Code-Einreichungen.
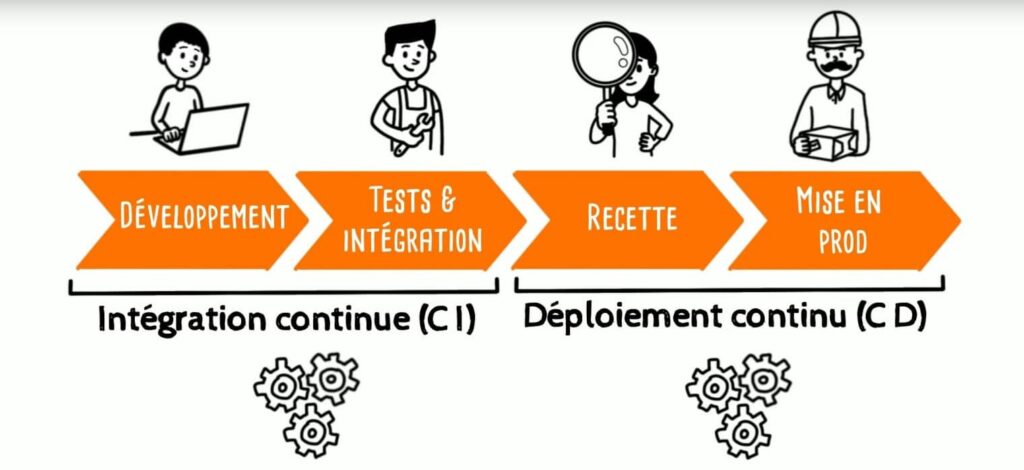
Continous Delivery: Wie funktioniert sie ?
Continuous Delivery automatisiert das „Push“ von Anwendungen an die Lieferumgebungen. Tools wie Jenkins, CircleCI, AWS CodeBuild, Azure DevOps oder Atlassian Bamboo automatisieren das Testen und Bewerten von Änderungen an Anwendungen.
Üblicherweise wird die Pipeline für die kontinuierliche Lieferung in die Schritte Build, Test und Deployment unterteilt. Zusätzliche Schritte können hinzugefügt werden, wie z. B. die Extraktion des Codes aus dem Versionskontrollordner, die Übertragung des Codes, das Pushen von Anwendungskomponenten an die entsprechenden Dienste oder das kontinuierliche Testen.
Innerhalb von Cloud-Umgebungen nutzen CI/CD-Pipelines auch Software-Container wie Docker und Orchestrierungssysteme wie Kubernetes. Auch serverlose Architekturen werden häufig eingesetzt, bei denen der Cloud-Dienstleister die Infrastruktur verwaltet. Die Anwendung verbraucht die Ressourcen je nach Bedarf.
Was sind Vorteile von CI / CD ?
Die kontinuierliche Integration und Lieferung ermöglicht eine bessere Zusammenarbeit und eine höhere Produktivität. Die Qualität des Codes wird durch eine bessere Kontrolle erhöht und auch die Qualität der fertigen Software wird gesteigert.
Darüber hinaus ermöglichen CI/CD-Pipelines Unternehmen, ihre Anwendungen häufig zu verbessern und sich dabei auf einen zuverlässigen Lieferprozess zu verlassen. Durch die Standardisierung von Builds, Tests und die Automatisierung der Bereitstellung können sich die Teams auf die Verbesserung der Anwendungen konzentrieren, anstatt sich mit technischen Details zu beschäftigen.
Diese Art zu arbeiten ist ideal für DevOps, da sie eine schlechte Abstimmung zwischen Entwicklern, die den Code zu häufig pushen wollen, und Ops-Teams, die nach stabilen Anwendungen suchen, verhindert. Automatisierung ermöglicht es, Codeänderungen häufiger zu pushen, während standardisierte Konfigurationen und kontinuierliches Testen die Stabilität verbessern.
CI / CD und Data Science
Wie in der Softwareentwicklung wird CI/CD auch im Bereich der Data Science verwendet, um Daten in die Produktion zu überführen. Dieser Ansatz ermöglicht eine automatische Bereitstellung.
Data-Science-Prozesse werden von verschiedenen Experten in Zusammenarbeit aufgebaut, z. B. Data Engineers, Machine-Learning-Experten und Visualisierungsspezialisten. Sie bestehen darin, Machine-Learning-Algorithmen auf Daten anzuwenden.
In diesem Bereich besteht die Integration in der Regel darin, die zugrunde liegenden Teile zusammenzusetzen. So wird sichergestellt, dass die Bibliotheken eines bestimmten Toolkits oder die richtigen Versionen eines Moduls im endgültigen Data-Science-Prozess enthalten sind.
Während der Entwicklung werden die Funktionen generiert und das Modell trainiert. Während der Integration wird der Prozess der Generierung von optimierten Funktionen mit dem trainierten Modell kombiniert. Die Integration umfasst auch den Produktionsprozess.
Die kontinuierliche Bereitstellung in der Data Science ähnelt der Softwareentwicklung und beinhaltet das automatische Ersetzen einer bestehenden Anwendung oder einer API. Die Fähigkeit, eine frühere Version wiederherzustellen, falls während der Produktion Probleme auftreten, ist ebenfalls vorhanden.
Während des Produktionsprozesses von Data Science muss die Leistung des Modells kontinuierlich überwacht werden. Die Erkennung von Änderungen ist entscheidend und muss durch Mechanismen sichergestellt werden.
Modelle können dann automatisch neu trainiert und bereitgestellt werden, während das Data Science-Team alarmiert werden kann, um einen neuen Prozess zu erstellen.
Git und GitHub
Die Versionskontrolle ist das Herzstück des CI/CD-Ansatzes. Dabei werden alle Änderungen an einem Softwareentwicklungs- oder Data-Science-Projekt gespeichert, um im Falle eines Fehlers oder Problems zurückgehen zu können. Es ist immer möglich, eine frühere Version wiederherzustellen.
Git wurde 2005 entwickelt und ist ein äußerst beliebtes Versionskontrollsystem. Wenn es auf einem lokalen System installiert und gepflegt wird, ermöglicht es die Sicherung von Versionen, ohne dass ein Internetzugang erforderlich ist.
Das System zeichnet sich durch seine Reaktionsfähigkeit, seine einfache Handhabung und seine Kostenlosigkeit aus. Es funktioniert besonders gut mit Textdateien wie Computercode. Seine wahre Stärke ist jedoch das Branching-Modell, das es ermöglicht, unabhängige lokale Zweige innerhalb des Codes zu erstellen. Dies ermöglicht es, neue Ideen zu testen, ohne sie unbedingt in Produktion zu bringen.
Der Hosting- und Code-Repository-Dienst GitHub ermöglicht es, Git-Versionskontrollprojekte online über den lokalen Computer oder Server hinaus zu teilen. Dieser Dienst ist vollständig cloudbasiert.
Die grafische Benutzeroberfläche von GitHub ist äußerst intuitiv und bietet native Tools zur Aufgabenverwaltung und Kontrolle für Programmierer.
Über einen Marketplace können zusätzliche Funktionen implementiert werden.
So ermöglicht es der GitHub-Dienst, Code zu teilen und mit anderen Nutzern an einem Software- oder Data-Science-Projekt zusammenzuarbeiten. Jede eingeführte Änderung schafft einen neuen Zweig, so dass jedes Teammitglied gleichzeitig arbeiten kann, ohne den Fortschritt der anderen zu stören.
Wie lernt man CI / CD ?
Continuous Integration und Continuous Delivery werden mittlerweile häufig in Unternehmen, bei der Softwareentwicklung oder im Bereich Data Science eingesetzt. Es handelt sich dabei um eine Fähigkeit, die in Unternehmen sehr gefragt ist. Um CI / CD zu beherrschen, entscheide Dich für DataScientest.
Unser Data Engineer-Fernkurs beinhaltet ein CI / CD-Modul, in dem unter anderem Git, GitHub und Qualitätssicherung behandelt werden. Die anderen Module des Programms umfassen unter anderem Python-Programmierung, Datenbanken, Data Science, Big Data, Automatisierung und Einsatz.
Nach Abschluss des Kurses wirst Du über alle Fähigkeiten verfügen, die du als Data Engineer benötigst. Du wirst in der Lage sein, große Datenmengen zu speichern, umzuwandeln und zu übertragen, Machine-Learning-Modelle für die Produktion einzusetzen und Pipelines für die Verarbeitung von gestreamten Daten zu erstellen.
Dieser Fernkurs kann als 9-monatige Weiterbildung oder als 11-wöchiges intensives BootCamp absolviert werden. Unser Blended-Learning-Ansatz kombiniert individuelles Coaching auf unserer Online-Plattform und Masterclasses.
Der Abschluss dieses Programms ermöglicht es dir, ein Zertifikat zu erhalten, das von MINES ParisTech / PSL Executive Education im Rahmen unserer Partnerschaft ausgestellt wird. Von unseren Alumni haben 80 % sofort einen Job gefunden.
Dieser Fernkurs kann man mit einem Bachelor Mathematik oder einem Master in Naturwissenschaften sowie einem Verständnis der Programmiersprache SQL und von Linux-Systemen absolvieren.
Warte nicht länger und entdecke die Ausbildung zum Data Engineer!
Du weißt jetzt alles über CI / CD. Weitere Informationen findest du in unserem ausführlichen Dossier über Git und unserem Dossier über DevOps.







