Willkommen zur dritten Episode unserer Einführung in die Programmierung mit Python zum Thema Data Cleaning. In der vorherigen Folge hast Du die verschiedenen Operatoren in Python kennengelernt, sowie die Funktionsweise von Schleifen und verschiedenen nützlichen Funktionen in Python. In diesem Teil lernst du zwei Schritte kennen, die für jedes Machine-Learning-Projekt unerlässlich sind: Data Cleaning und Data Processing.
Dataimport im DataCleaning
Bevor Du in Python mit Daten arbeiten kannst, wie z. B. Bereinigung, Umwandlung und Visualisierung, musst du sie importieren.
Dazu verwenden wir das Pandas-Modul. Es wurde entwickelt, um Python die Tools zu geben, die es braucht, um mit großen Datenmengen umzugehen. Dieses Modul hat das Ziel, das beste Werkzeug zur Datenmanipulation zu werden: leistungsstark, benutzerfreundlich und flexibel zugleich. Pandas ist heute das am häufigsten verwendete Modul zur Verwaltung von Datenbanken in den Formaten: CSV, Excel, …
csv Datei:
Einer der häufigsten Datentypen ist das CSV-Format, ein Akronym für comma separated value (kommagetrennte Werte).
Die allgemeine Struktur von CSV-Dateien verwendet Zeilen als Beobachtungen und Spalten als Attribute.
Hier ist die Vorgehensweise, um CSV-Dateien zu lesen:
Es ist auch möglich, der Funktion pd.read_csv weitere Argumente hinzuzufügen:
– Das sep-Argument in der Funktion, mit dem die Art der Trennung für das Lesen unserer Daten angegeben werden kann (z. B. , / ; / – …).
– Das Argument header bestimmt die Nummer der Zeile, die die Namen der Variablen enthält; standardmäßig ist header = 0.
– Mit dem Argument index_col wird eine Spalte des DataFrame als Index festgelegt.
Excel-Dateien:
Excel-Dateien sind zusammen mit CSV-Dateien die am häufigsten verwendeten Dateien.
Hier ist die Vorgehensweise mit der Funktion pd.ExcelFile():
Wenn wir keinen Blattnamen angeben, wird standardmäßig das erste Blatt angezeigt. Wenn wir ein bestimmtes Blatt anzeigen wollen, können wir dies mit der letzten Zeile des Codes oben tun, indem wir den Namen des Blattes angeben.
Bevor wir mit der Datenmodellierung beginnen, müssen wir eine Reihe von vorbereitenden Schritten durchlaufen, die für ein Machine-Learning-Projekt unerlässlich sind. Obwohl sie mühsam sind, sollten sie nicht außer Acht gelassen werden, da sie die Qualität unserer Modellierung garantieren. Es wird oft von „garbage in – garbage out“ gesprochen. Ein Modell, dessen Datenqualität nicht optimal ist, wird keine guten Vorhersagen machen können.
Die Vorstufen, auch Data-Pre-Processing-Schritte genannt, umfassen daher die Schritte der Statusüberprüfung, der Datenbereinigung und der Datenvorbereitung.
Verifizierung:
Zuallererst ist es wichtig, sich einen Überblick über die Daten zu verschaffen. Zum Beispiel hängt die Aufbereitung unserer Daten von der Art der Variablen ab. Bei numerischen Daten ist es interessant, den Wertebereich, den Mittelwert, die Standardabweichung und andere grundlegende Statistiken zu kennen. Dieser Überprüfungsschritt beinhaltet auch die Überprüfung, ob es Duplikate gibt.
Data Cleaning
Umgang mit fehlenden Daten
Die Datenbanken, mit denen wir täglich zu tun haben, enthalten sehr oft fehlende Daten. Es gibt viele Gründe für diese Problematik: Tippfehler, die zu Datenentfernungen geführt haben, ursprünglich nicht vorhandene Daten usw. Die meisten Datenbanken sind in der Lage, die Daten zu löschen.
Das Löschen von Daten ist der letzte Ausweg, da es zu einem großen Verlust an Informationen führt. Je mehr Informationen wir haben, desto besser ist die Vorhersagequalität unseres Modells.
In manchen Fällen wird diese Strategie jedoch trotzdem gewählt. In der Regel wird man sich dafür entscheiden, eine Datenreihe zu löschen, wenn sie voller fehlender Daten ist, insbesondere wenn die wichtigsten Variablen fehlen, wie z. B. die Target.
Wenn die meisten Daten fehlen und die Variable nur eine geringe Bedeutung für die vorhergesagte Variable hat, kann man sich dafür entscheiden, eine ganze Variable zu löschen.
Anstatt diese Daten zu löschen, sollte man die Imputation von Werten bevorzugen. Diese [cm_tooltip_parse] Methode [/cm_tooltip_parse] hilft, den Informationsverlust zu reduzieren. Es gibt verschiedene Methoden, die wir anwenden können. Man kann z. B. bei numerischen Variablen den Median- oder Mittelwert dieser Variable imputieren (bei der Imputation des Mittelwerts ist auf Extremwerte zu achten). Bei kategorialen Variablen kann man den Mehrheitswert innerhalb der Variable imputieren, indem man den Modus verwendet.
Eine feinere Imputationsmethode ist die Imputation unter Berücksichtigung der Werte in den anderen Variablen. Du kannst den Mittelwert, den Median und den Modus für Gruppen von Individuen innerhalb des DataFrame berechnen, um den zu imputierenden Wert zu verfeinern.
Ausreißer /Outlier
Ein Ausreißer ist ein Wert, der von der Verteilung der Variable abweicht. Dies kann auf einen Tippfehler oder einen Messfehler zurückzuführen sein, kann aber auch ein extremer Wert sein. Ein Extremwert ist ein Wert, der nicht fehlerhaft ist, aber dennoch stark von den übrigen Werten der Variable abweicht.
Eine recht einfache Möglichkeit, solche Werte zu erkennen, ist die Erstellung eines Box-Plots für jede der Variablen. Ein Boxplot ist ein rechteckiges Diagramm, in dem die Statistiken der Variablen (Quartile (Q1, Median, Q3)) beschrieben werden. Die Grenzen des Diagramms begrenzen die Werte gemäß der Verteilung der Variablen. Über diese Grenzen hinaus werden diese Werte als Ausreißer betrachtet.
Im Rahmen eines Machine-Learning-Projekts wird häufig die Entscheidung getroffen, einen Ausreißer zu entfernen. Um eine bessere Vorhersagequalität zu erreichen, müssen diese Daten verarbeitet werden, da ein Modell sehr empfindlich auf extreme Daten reagieren kann, was die Vorhersagen verzerrt.
Data processing
Binäre Verschlüsselung
Wenn wir es mit textuellen kategorialen Daten zu tun haben, müssen wir unsere Variablen kodieren. Wir sprechen von binärer Kodierung, wenn wir eine Variable in zwei Kategorien kodieren, normalerweise in 0, 1. Zum Beispiel kann eine Variable, die das Geschlecht einer Person beschreibt, in 0, 1 kodiert werden. Eine kategoriale Variable (mit mehr als zwei Kategorien) kann ebenfalls kodiert werden, abhängig von der Anzahl der Kategorien, aus denen sie besteht.
Die übliche Strategie ist jedoch die Erstellung von Dummies. Ausgehend von einer Variablen werden für die n-Kategorien, aus denen sie besteht, n-1 binär codierte Spalten (0-1) erstellt, die jeweils einer der Kategorien in der Variablen entsprechen. Eine Spalte wird entfernt, da diese Spalte von den anderen abgeleitet werden kann. Es ist wichtig, dass die Variablen für die Qualität der Vorhersage nicht korreliert sind.
Feature Scaling: Normalisierung und Standardisierung
Die Variablen, aus denen sich ein DataFrame zusammensetzt, haben nicht immer denselben Maßstab. Das Alter und die Körpergröße werden zum Beispiel unterschiedlich gemessen. Um die Gewichtung der einzelnen Variablen im DataFrame auszugleichen, müssen die Variablen „skaliert“ werden, d. h. sie müssen auf die gleiche Skala gesetzt werden. Dieser Schritt ist sehr wichtig, insbesondere in Modellen, die lineare Distanzmaße verwenden, die von dieser Art von Ungleichgewicht stark beeinflusst werden.
Es gibt zwei Fälle: wenn die Verteilung einer Variablen einer Normalverteilung folgt und wenn sie nicht einer Normalverteilung folgt.
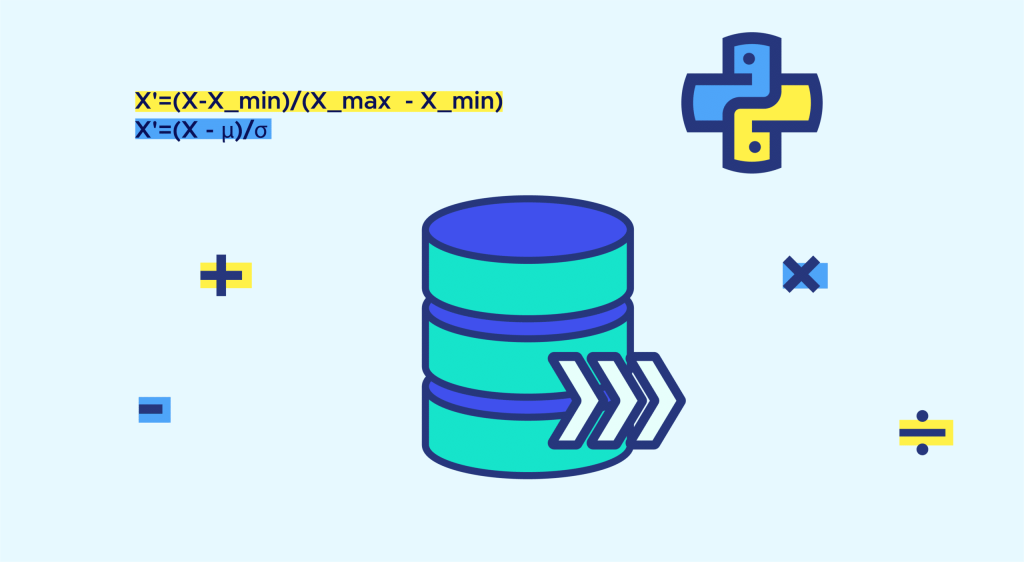
Wenn die Verteilung nicht normalverteilt ist, sollte ein „min-max scaling“ angewendet werden, wobei die Werte in einem Intervall von [0,1] liegen.
X’=(X-X_min)/(X_max – X_min)
Wenn die Variable einer Normalverteilung folgt, spricht man von Standardisierung. Dazu subtrahiert man den Mittelwert und dividiert durch die Standardabweichung.
X’=(X – μ)/σ
Dabei sind µ oder σ der Mittelwert und die Standardabweichung der Verteilung.
Data Cleaning Fazit
Dies sind die wichtigsten Meilensteine des Data Pre-Processing. Es gibt natürlich noch weitere Verfahren, die du auf deine Datenbanken in spezifischerer Weise anwenden kannst! Je besser die Variablen in unserem DataFrame verarbeitet sind, desto einfacher werden die Schritte der Variablenerstellung und Modellierung.







