Dank der Entwicklung von Big Data und künstlicher Intelligenz können Data Scientists Modelle zum Lernen von Daten verwenden, um vorausschauende Analysen durchzuführen. Zu den effektivsten Methoden gehört das Ensembling.
Worum geht es also?
Wie funktioniert das Zusammenstellen von Vorlagen?
Was sind seine Vor- und Nachteile?
💡Das werden wir uns in diesem Artikel ansehen.
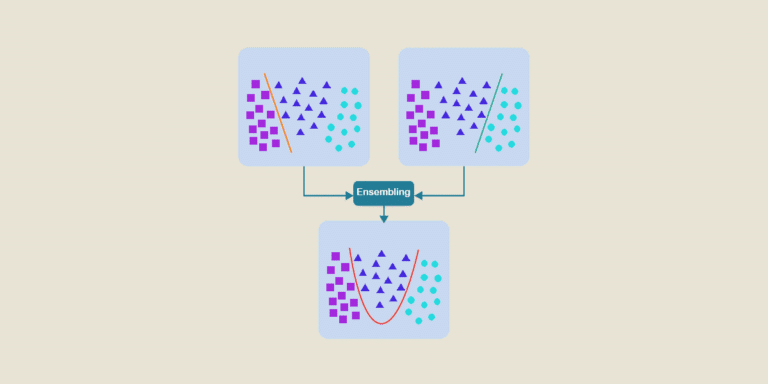
Was ist Ensembling?
Beim Ensembling werden mehrere Modelle neuronaler Netze kombiniert, um ein bestimmtes Problem zu lösen. Jedes Modell verwendet dann seine eigenen Lerntechniken. Dadurch können die Vorhersagen bereichert werden.
Mit dem Lernen von Modell-Ensembles ist es möglich, wesentlich zuverlässigere und relevantere Ergebnisse zu erzielen als mit jedem einzelnen Modell.
Wie funktioniert das Zusammenstellen von Vorlagen?
Jedes Lernmodell erfordert die Verwendung großer Datenmengen, um zu relevanten Ergebnissen zu gelangen. Aber je nach verwendeter Technik müssen die richtigen Komponenten sorgfältig ausgewählt werden (Anteil der Verzerrung und der Varianz).
Hier sind einige Beispiele für Lerntechniken:
- Absackung: Hier geht es darum, die Varianz zu reduzieren, um die Stabilität der Vorhersagen zu verbessern. In diesem Fall benötigt man Komponenten mit geringem Bias und hoher Varianz. Die Verzerrungen wirken dann den Varianzen entgegen. Dadurch werden die Ergebnisse weniger anfällig für die Besonderheiten der Trainingsdaten.
- Boosting: Umgekehrt ist es das Ziel, die Verzerrungen zu verringern. Dazu werden die Modelle sequentiell eingesetzt.
- Stacking: Es verbessert die Genauigkeit und hält gleichzeitig die Varianz und den Bias niedrig. Dies ist besonders nützlich bei zufälligen Wäldern.
Grundsätzlich werden beim Ensembling die Modelle getrennt voneinander ausgeführt, bevor die Vorhersagen miteinander kombiniert werden.
Diese Zusammenstellung der Modelle reduziert dann die Varianz der Vorhersagen, die aus den Test- und Validierungsdaten gewonnen werden.
💡Gut zu wissen:
Auch wenn die Kombination mehrerer Modelle zu zuverlässigeren Vorhersagen führt, sollte die Anzahl der Modelle begrenzt werden.
Das liegt zum einen an den Kosten für das Training und zum anderen an der schlechteren Leistung, die durch das Hinzufügen neuer Modelle verursacht wird.
Normalerweise liegt die richtige Balance zwischen 3 und 10 Modellen, die trainiert werden. Mit dieser Zahl lassen sich die besten Ergebnisse erzielen.

Was sind die Vorteile?
Ensembling ist eine der am häufigsten verwendeten Techniken des Machine Learning. Und das aus gutem Grund, denn es bietet Datenexperten eine Vielzahl von Vorteilen:
- Genauigkeit: Im Allgemeinen liefern Modell-Assemblies bessere Ergebnisse als jedes Modell mit nur einer Komponente. Meistens verbessern sich die Ergebnisse mit zunehmender Größe der Ansammlung. Aber wie bereits gesehen, muss das richtige Gleichgewicht gefunden werden. Das heißt, nicht zu viele Modelle hinzufügen.
- Relevanz: Modellansammlungen sind eher in der Lage, Verallgemeinerungen vorzunehmen, um die gegebene Fragestellung zu beantworten. Das schränkt die Streuung der Analysen ein.
- Flexibilität: Mit Ensembling haben Data Scientists Zugang zu großen Datenmengen, aber es ist durchaus möglich, die Ergebnisse an das verfügbare Informationsniveau anzupassen. Dazu gehört auch die Auswahl des besten Modells aus mehreren Möglichkeiten.
Wo liegen die Grenzen?
Obwohl Ensembling sehr effektiv ist, hat es dennoch einige Einschränkungen.
Nämlich:
- Nur Modelle, die mit denselben Parametern trainiert wurden, können kombiniert werden ;
- Einige Lernmodelle können nicht zusammengestellt werden.
- Dies gilt z. B. für Modelle, die mit dem K-Fold-Kreuztest, mit Vektoren oder Bildmerkmalen, partitionierten Modellen oder Computer Vision-Modellen gebildet wurden.
Was wir uns merken sollten:
- Beim Ensembling werden mehrere Modelle neuronaler Netze kombiniert, um die Relevanz der Vorhersageergebnisse zu optimieren.
Vor dem Assembling wird jedes Modell separat mit seinen eigenen Lerntechniken ausgeführt. - Das Lernen von Modell-Sets verbessert die Genauigkeit und Relevanz der Vorhersagen.
Allerdings ist es nicht möglich, diese Technik bei allen Modellen anzuwenden.







