U-NET ist ein Modell für ein neuronales Netz, das sich mit Computer Vision Patches und insbesondere mit semantischen Segmentierungsproblemen befasst. Hier erfährst Du alles, was Du dazu wissen solltest: Überblick, Funktionsweise, Architektur, Vorteile, Weiterbildungen…
💡Auch interessant:
| Was genau ist ein Deep Neural Network? |
| Recurrent Neural Network (RNN): Was genau ist das? |
| Convolutional Neural Network (CNN): Alles, was Du wissen solltest |
Die Künstliche Intelligenz ist eine breitgefächerte Technologie mit vielen verschiedenen Zweigen. Eine dieser Unterkategorien ist die Computer Vision.
Es handelt sich um ein interdisziplinäres wissenschaftliches Feld, das darauf abzielt, Computer so zu gestalten, dass sie Bilder und Videos „verstehen“ können. Ziel ist es, die vom menschlichen Sehapparat ausgeführten Aufgaben zu automatisieren.
Dank Deep Learning konnten in den letzten Jahren enorme Fortschritte im Bereich des Maschinellen Sehens erzielt werden. Mittlerweile sind Maschinen sogar in der Lage, in bestimmten Situationen mit dem menschlichen Sehvermögen zu konkurrieren.
Die verschiedenen Aufgaben der Computer Vision
Es gibt verschiedene Aufgaben der Computer Vision. Eine der häufigsten Anwendungen ist die Bildklassifizierung. Sie besteht darin, dass der Computer das Hauptobjekt in einem Bild identifiziert und ihm ein Etikett zuweist, um das Bild zu klassifizieren.
Genauso ist es möglich, dass der Computer die Position des Objekts auf dem Bild lokalisiert. Dazu umrahmt er das Objekt mit einer „Bounding Box„, die durch numerische Parameter der Bildränder identifiziert werden kann.
Die Objektklassifikation ist auf ein einzelnes Objekt pro Bild beschränkt. Die komplexere Objekterkennung geht darüber hinaus und setzt voraus, dass der Computer alle verschiedenen Objekte innerhalb eines Bildes erkennt und lokalisiert.
Bei der semantischen Segmentierung wird jedes Pixel in einem Bild mit einer Klasse versehen, die dem entspricht, was dargestellt wird. Man spricht auch von „dense prediction„, da jedes Pixel vorhergesagt werden muss.
Im Gegensatz zu anderen Aufgaben der Computervision erzeugt die semantische Segmentierung nicht nur Etiketten und Bounding Boxes. Sie erzeugt außerdem ein hochauflösendes Bild, auf dem jedes Pixel klassifiziert wird.
Die Instanzsegmentierung geht noch einen Schritt weiter, indem sie jede Instanz einer Klasse separat klassifiziert. Wenn auf einem Bild beispielsweise drei Hunde zu sehen sind, ist jeder Hund eine Instanz der Klasse „Hund“. Jeder wird separat klassifiziert, zum Beispiel durch die Verwendung unterschiedlicher Farben.
Durch diese verschiedenen Aufgaben „versteht“ der Computer den Inhalt der Bilder mit einer immer höheren Detailgenauigkeit. In diesem Artikel werden wir uns speziell mit der Aufgabe der semantischen Segmentierung beschäftigen.
Anwendungen und Anwendungsbeispiele der semantischen Segmentierung
Die semantische Segmentierung wird für eine Vielzahl von Anwendungen genutzt. Autonome Fahrzeuge zum Beispiel erfordern die Wahrnehmung, Planung und Ausführung in ständig wechselnden Umgebungen .
Deshalb erfordern sie eine hohe Genauigkeit, da die Systeme im Straßenverkehr absolut fehlerfrei funktionieren müssen. Mithilfe der semantischen Segmentierung ist es möglich, dass unbemannte Autos freie Flächen auf den Fahrbahnen, Fahrbahnmarkierungen und Verkehrsschilder erkennen.
Diese KI-Technik wird ebenfalls in der medizinischen Diagnostik eingesetzt. Die Maschinen können die Analysen von Radiologen unterstützen, um die Zeit für die Erstellung von Diagnosen zu verkürzen.
Ein weiterer Anwendungsfall ist die Satellitenkartografie, die für die Überwachung von Abholzungsgebieten oder für die Urbanisierung sehr wichtig ist. Durch semantische Segmentierung können nämlich verschiedene Geländetypen automatisiert unterschieden werden. Auch die Erkennung von Gebäuden und Straßen ist für das Verkehrsmanagement oder die Stadtplanung von großem Nutzen.
Schließlich können Roboter in der Präzisionslandwirtschaft die semantische Segmentierung nutzen, um zwischen Nutzpflanzen und Unkraut zu unterscheiden. Dadurch können sie die Unkrautbekämpfung automatisieren und die Menge an Herbiziden verringern.
Was ist U-NET?
Es gibt verschiedene Methoden, um Probleme bei der semantischen Segmentierung zu lösen. Traditionelle Ansätze bestehen darin, Punkte, Linien oder Ränder zu erkennen. Es ist auch möglich, sich auf die Morphologie zu stützen oder Pixelcluster zusammenzusetzen.
Inzwischen werden im Deep Learning Convolutional Neuronal Networks (faltungsneurale Netzwerke) häufig eingesetzt. Sie ermöglichen es, mithilfe der Bildsegmentierung komplexere Probleme anzugehen.
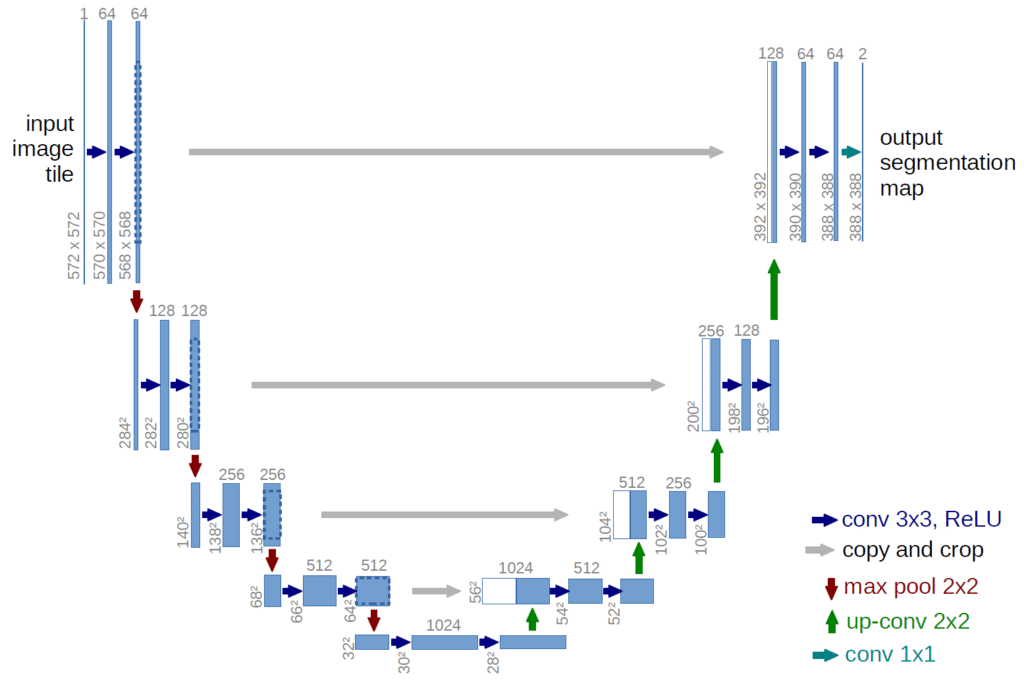
Eines der am häufigsten für die Bildsegmentierung verwendeten neuronalen Netze ist U-NET. Dabei handelt es sich um ein vollständig faltbares Modell eines neuronalen Netzes. Dieses Modell wurde ursprünglich von Olaf Ronneberger, Phillip Fischer und Thomas Brox im Jahr 2015 für die Segmentierung von medizinischen Bildern entwickelt.
Die Architektur von U-NET besteht aus zwei „Pfaden“. Der erste ist der Kontraktionspfad, der auch als Encoder bezeichnet wird. Er wird verwendet, um den Kontext eines Bildes zu erfassen.
Im Grunde handelt es sich dabei um eine Ansammlung von Faltungsschichten und „Max-Pooling„-Schichten, die es ermöglichen, eine Karte mit den Merkmalen eines Bildes zu erstellen und seine Größe zu reduzieren, um die Anzahl der Parameter des Netzwerks zu verringern.
Der zweite Weg ist die symmetrische Expansion, die auch als >Decoder bezeichnet wird. Er ermöglicht ebenfalls eine genaue Lokalisierung durch die transponierte Faltung.
Die Vorteile von U-NET
Im Bereich des Deep Learning ist es notwendig, große Datensätze zu verwenden, um die entsprechenden Modelle zu trainieren. Die Zusammenstellung solcher Datenmengen zur Lösung eines Bildklassifizierungsproblems kann sich in Bezug auf Zeit, Budget und Hardwareressourcen als schwierig erweisen.
Auch die Kennzeichnung der Daten erfordert das Fachwissen mehrerer Entwickler und Ingenieure. Dies ist besonders in hochspezialisierten Bereichen wie der medizinischen Diagnostik der Fall.
U-NET schafft hier Abhilfe, da es selbst bei einem begrenzten Datensatz zuverlässig arbeitet. Außerdem bietet es eine höhere Genauigkeit als herkömmliche Modelle.
Eine herkömmliche Autoencoder-Architektur reduziert die Größe der eingegebenen Informationen. Danach beginnt die Decodierung, die lineare Merkmalsdarstellung wird erlernt und der Raster wird allmählich größer. Am Ende dieser Architektur entspricht die Ausgabegröße der Eingabegröße.
Eine solche Architektur ist ideal, um die Anfangsgröße zu erhalten. Das Problem ist, dass sie den Input linear komprimiert, sodass nicht alle Merkmale übertragen werden können.
Hier spielt U-NET dank seiner U-Architektur seine Stärken aus. Die Entfaltung erfolgt auf der Seite des Decoders, wodurch das bei einer Auto-Encoder-Architektur auftretende Flaschenhalsproblem und damit der Verlust von Merkmalen vermieden wird.
💡Auch interessant:
Wie lernt man, U-NET zu verwenden?
Da KI und Computer Vision in allen Bereichen zunehmend genutzt werden, ist der Umgang mit Deep Learning und den verschiedenen Modellen wie U-NET eine wertvolle und gefragte Fertigkeit.
Um diese Fähigkeiten zu erwerben, bietet DataScientest Dir eine Reihe von Weiterbildungen an. Machine Learning und Deep Learning stehen im Mittelpunkt unseres Data Scientist-Kurses.
In diesem Kurs lernst Du zudem mit Python zu programmieren, die Nutzung von DataViz und den Umgang mit Datenbanken und Big-Data-Tools. Nach Abschluss des Kurses besitzt Du alle notwendigen Fähigkeiten, um den boomenden Beruf des Data Scientists auszuüben.
Unsere berufsvorbereitenden Kurse sind so konzipiert, dass sie auf die tatsächliche Bedürfnissen von Unternehmen und Organisationen zugeschnitten sind. Sie können als Intensivkurs oder als berufsbegleitende Weiterbildung absolviert werden.
Wir bieten Dir einen innovativen Blended-Learning-Ansatz, der Präsenzunterricht und Fernunterricht miteinander verbindet. Am Ende des Programms erhältst Du ein von der Sorbonne zertifiziertes Diplom.
Von unseren Alumni haben 93 % sofort einen Job gefunden. Warte nicht länger und entdecke jetzt unsere Weiterbildung zum Data Scientist!
Jetzt weißt Du alles über U-NET. Lies unseren Artikel über Computer Vision sowie unseren allgemeineren Artikel über Deep Learning.







