
Daten werden immer allgegenwärtiger. So sehr, dass sie laut einigen Wissenschaftlern, darunter der Physiker Melvin Vopson, in naher Zukunft einen eigenen Aggregatzustand annehmen könnten, der messbare Masse besitzt und auf seine Umgebung einwirkt.
Es ist daher wichtig für Unternehmen, diese immensen Datenmengen verwalten zu können. Man muss in der Lage sein, sie zu extrahieren, zu transformieren und in Datenbanken zu laden: Genau das bedeutet das Kürzel „ETL“: Extract, Transform, Load. Der ETL-Entwickler hat also die Aufgabe, Prozesse (sogenannte Pipelines) zu implementieren, um diese Daten zu automatisieren und zu nutzen, und den gesamten Lebenszyklus der Daten perfekt zu beherrschen.
Den ETL-Prozess verstehen
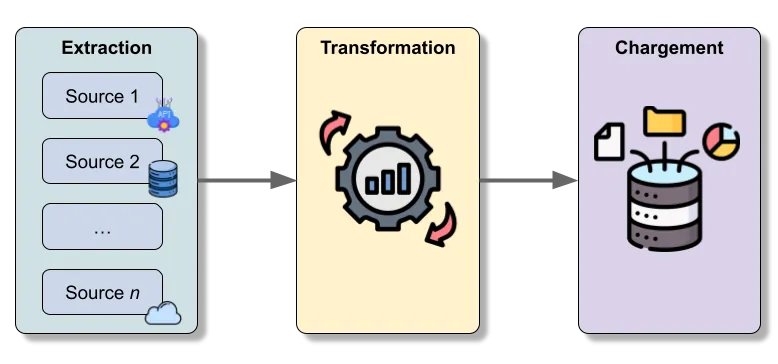
Der ETL-Prozess besteht darin, Daten zu extrahieren (möglicherweise aus mehreren Quellen), sie zu transformieren, um sie homogen zu machen, und sie dann in ein Data Warehouse (Data Warehouse) zu laden. Dieser Prozess ist unerlässlich, um sicherzustellen, dass die Rohdaten (Raw Data) korrekt vorbereitet sind und für fortgeschrittene Analysen verwendet werden können.
Diese verschiedenen Schritte werden mithilfe von ETL-Tools sichergestellt, die den Prozess automatisieren und häufig sehr detaillierte Konfigurationen in Bezug auf die angestrebte Präzision, die Automatisierung der Ausführung des Prozesses oder die Protokollierung der durchgeführten Aufgaben anbieten.
Welche Rolle hat der ETL-Entwickler?
Die Rolle eines ETL-Entwicklers ist breit gefächert und umfasst viele Aspekte des Datenmanagements. Diese Fachkraft muss in der Lage sein, die Bedürfnisse der Unternehmen (oder ihrer Kunden) in Bezug auf die Datenspeicherung genau zu verstehen und in der Lage sein, vollständige und manchmal komplexe ETL-Workflows zu erstellen. Das Ziel ist sicherzustellen, dass die Daten für Analysten und Data Scientists bereit sind. Auch das Testen dieser Workflows ist nicht zu vergessen.
Er arbeitet eng mit mehreren Teams zusammen, einschließlich der Datenanalysten, Data Scientists und Software-Ingenieure. Diese Zusammenarbeit zielt darauf ab, sicherzustellen, dass die Daten eine ausreichende Qualität aufweisen (man spricht dann von Datenqualität) und bereit sind, in analytische Modelle integriert zu werden. Tatsächlich wären ohne gut vorbereitete Daten die von Data Scientists oder Datenanalysten durchgeführten Analysen nicht zuverlässig.
Ein weiterer Aspekt der Rolle ist die Implementierung von Data Pipelines (oder Datenpipelines). Diese Pipelines ermöglichen es, den Datenfluss kontinuierlich und automatisiert zu verwalten, sodass Teams, die nach verwertbaren Informationen suchen, stets auf aktualisierte Daten zugreifen können.

Welche Fähigkeiten sind erforderlich?
Der Beruf des ETL-Entwicklers erfordert eine Kombination aus technischen und analytischen Fähigkeiten. Zu den wesentlichen technischen Fähigkeiten gehört die Kenntnis von Programmiersprachen wie SQL, Python oder Java, die zur Manipulation und Transformation von Daten verwendet werden. Ähnlich wie ein Videokünstler, der Adobe Premiere beherrschen muss, müssen ETL-Entwickler auch Tools wie Apache NiFi, Talend oder Pentaho beherrschen.
Abhängig von der Größe des Unternehmens und damit dem Datenvolumen kann die Kenntnis von Big Data Tools wie Hadoop und Spark erforderlich sein.
Ein sehr gutes Verständnis der Probleme und der Kundenbedürfnisse ist notwendig, um ETL-Workflows einzurichten und zu optimieren. Dies erfordert daher ein sehr gutes Wissen über die verschiedenen Tools und damit verbundenen Prozesse.
ETL-Entwickler vs. Data Engineer
Diese beiden Berufe werden oft verwechselt. Tatsächlich kann ein Data Engineer die Funktionen eines ETL-Entwicklers in kleinen oder mittleren Unternehmen übernehmen. Aber im Kontext großer Unternehmen und damit großer Datenmengen werden diese beiden Berufe getrennt.
Die Arbeit eines ETL-Entwicklers besteht hauptsächlich darin, ETL-Prozesse zu integrieren und umzusetzen, um die gewünschten Daten zu erhalten und im Zielsystem zu speichern. Andererseits sind Data Engineers da, um auf strategischere Probleme zu reagieren, indem sie tief im Daten-Ökosystem, den Big Data-Technologien oder dem Cloud Computing eingreifen. Er kann auch in der Lage sein, Teams zu leiten und Projekte an ETL-Entwickler zuzuweisen. Dies kann zudem eine natürliche Entwicklungsoption für einen ETL-Entwickler sein.
Arbeitsumgebung
Die wichtigsten von ETL-Entwicklern verwendeten Tools umfassen Datenintegrationswerkzeuge wie Informatica, Talend, SSIS (SQL Server Integration Services), sowie Cloud-Lösungen wie Azure Data Factory oder AWS Glue. Jedes Werkzeug hat seine eigenen Vorteile und Einschränkungen, und die Entwickler müssen in der Lage sein, das für die spezifischen Bedürfnisse des Unternehmens am besten geeignete auszuwählen.
Entwicklungsperspektiven und Gehalt
Sein Gehalt variiert je nach Unternehmen und Standort. In Deutschland liegt das durchschnittliche Jahresgehalt eines ETL-Entwicklers bei etwa 50.000 bis 60.000 €, wobei regionale Unterschiede und die Größe des Unternehmens eine Rolle spielen können. In größeren Städten wie München oder Frankfurt ist das Gehalt tendenziell höher, während es in ländlicheren Gegenden oder kleineren Unternehmen etwas niedriger ausfallen kann.
Die Karriereperspektiven sind ebenfalls interessant. Du kannst zum Data Engineer aufsteigen oder in Positionen im Projektmanagement oder Datenarchitektur wechseln. Einige können sich je nach ihren Vorlieben und Fähigkeiten auch in analytischere Positionen wie Data Analyst oder Data Scientist begeben.

Fazit
Der ETL-Entwickler sorgt für die Transformation und das Laden der Daten, wodurch prädiktive Analysen und strategische Entscheidungsfindungen ermöglicht werden. Unternehmen sind auf Daten angewiesen, um ihre Kunden zu verstehen, ihre Abläufe zu optimieren und neue Wachstumschancen zu schaffen.







