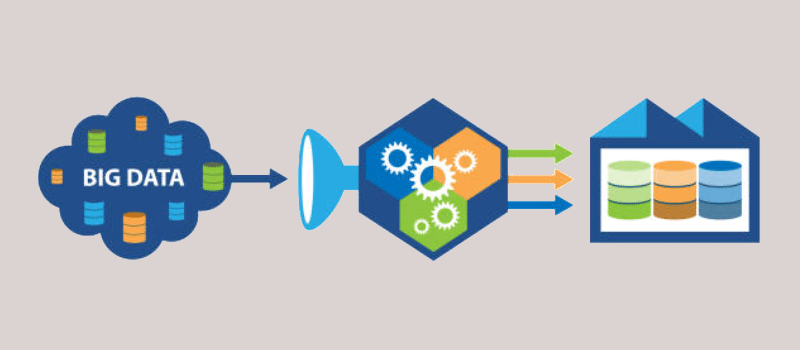
Eine Data Pipeline ist eine Reihe von Prozessen und Werkzeugen, die verwendet werden, um Rohdaten aus verschiedenen Quellen zu sammeln, sie zu analysieren und die Ergebnisse in einem verständlichen Format darzustellen. Unternehmen nutzen Datenpipelines, um spezifische geschäftliche Fragen zu beantworten und strategische Entscheidungen auf der Grundlage von realen Daten zu treffen. Alle verfügbaren Datensätze (interne oder externe) werden analysiert, um diese Informationen zu erhalten.
Eine Data Pipeline ist eine Reihe von Prozessen und Werkzeugen, die verwendet werden, um Rohdaten aus verschiedenen Quellen zu sammeln, sie zu analysieren und die Ergebnisse in einem verständlichen Format darzustellen. Unternehmen nutzen Datenpipelines, um spezifische geschäftliche Fragen zu beantworten und strategische Entscheidungen auf der Grundlage von realen Daten zu treffen. Alle verfügbaren Datensätze (interne oder externe) werden analysiert, um diese Informationen zu erhalten.
Data Pipeline vs. ETL-Pipeline
Obwohl sich die Begriffe „Data Science Pipelines“ und „ETL-Pipelines“ beide auf den Prozess der< Übertragung von Daten von einem System in ein anderes beziehen, gibt es wesentliche Unterschiede zwischen den beiden:
- Die ETL-Pipeline endet, wenn die Daten in ein Data Warehouse (Datenlager) oder eine Datenbank geladen werden. Die Data Science Pipeline endet nicht an dieser Stelle, sondern beinhaltet zusätzliche Schritte wie Feature Engineering oder Machine Learning.
ETL-Pipelines beinhalten immer einen Schritt der Datentransformation (ETL steht für Extract Transform Load), im Gegensatz zu Data Science Pipelines, bei denen der Großteil der Schritte mit den Rohdaten durchgeführt wird. - Data Science Pipelines laufen in der Regel in Echtzeit ab, während ETL-Pipelines die Daten in Blöcken oder in regelmäßigen Zeitabständen übertragen.
Warum ist die Data Pipeline wichtig?
Unternehmen erstellen jeden Tag Milliarden von Daten, und jede dieser Daten enthält verwertbare Informationen. Die Data Pipeline holt das Maximum aus den Informationen heraus, indem sie die Daten aller Teams zusammenführt, sie bereinigt und in einer leicht verständlichen Form präsentiert. Dadurch können schnelle, datengestützte Entscheidungen getroffen werden.
Mithilfe einer Data Pipeline kannst du den zeitraubenden und fehleranfälligen Prozess der manuellen Datensammlung vermeiden. Durch den Einsatz intelligenter Tools zur Datenaufnahme (wie Talend oder Fivetran) hast du ständigen Zugriff auf saubere, zuverlässige und aktuelle Daten, die entscheidend sind, um der Konkurrenz immer einen Schritt voraus zu sein.
Vorteile von Data Pipelines
- Die Agilität erhöhen, um auf die sich ändernden Geschäftsanforderungen und Kundenpräferenzen zu reagieren.
Den Zugang zu Informationen über das Unternehmen und die Kunden vereinfachen. - Den Prozess der Entscheidungsfindung beschleunigen.
- Datensilos und Engpässe beseitigen, die das Handeln verzögern und Ressourcen verschwenden.
- Den Prozess der Datenanalyse vereinfachen und beschleunigen.
Wie funktioniert eine Data Pipeline?
Bevor du Rohdaten in die Data Pipeline verschiebst, ist es entscheidend, die spezifischen Fragen zu identifizieren, die die Daten beantworten sollen. Dies hilft den Nutzern, sich auf die interessanten Daten zu konzentrieren, um die richtigen Informationen zu erhalten.
Die Data Science Pipeline besteht aus mehreren Schritten:
Die Beschaffung von Daten.
In dieser Phase werden Daten aus internen, externen und Drittquellen gesammelt und in ein brauchbares Format (XML, JSON, .csv usw.) umgewandelt.
Die Bereinigung von Daten.
Dies ist der zeitaufwändigste Schritt des Prozesses. Die Daten können Anomalien wie doppelte Parameter, fehlende Werte oder irrelevante Informationen enthalten, die bereinigt werden müssen, bevor eine Datenvisualisierung erstellt werden kann.
Dieser Schritt kann in zwei Kategorien unterteilt werden:
- Durchsicht der Daten, um Fehler, fehlende Werte oder beschädigte Datensätze zu identifizieren.
- Bereinigung der Daten, was bedeutet, Lücken zu schließen, Fehler zu korrigieren, Duplikate zu entfernen und irrelevante Datensätze oder Informationen zu löschen.
Datenexploration und -modellierung.
Nachdem die Daten sorgfältig bereinigt wurden, können sie anschließend zur Identifizierung von Mustern verwendet werden. Hier kommen Machine-Learning-Tools ins Spiel. Diese Tools helfen dir dabei, Muster zu finden und Regeln anzuwenden, die spezifisch für Daten oder Datenmuster sind. Diese Regeln können dann an Beispieldaten getestet werden, um festzustellen, wie sich das auf Leistung, Umsatz oder Wachstum auswirken würde.
Die Interpretation der Daten.
In diesem Schritt geht es zunächst darum, die Informationen zu identifizieren und sie mit den Ergebnissen deiner Daten zu korrelieren. Anschließend kannst du deine Ergebnisse mithilfe von Diagrammen, Dashboards oder Berichten an die Unternehmensleiter oder deine Kollegen weitergeben.
Die Überarbeitung der Daten.
Wenn sich die Anforderungen des Unternehmens ändern oder mehr Daten verfügbar werden, ist es wichtig, dein Modell regelmäßig zu überprüfen und gegebenenfalls zu überarbeiten.
Fazit
In diesem Artikel haben wir die Verwendung von Pipelines in der Datenbranche beschrieben. Als Data Engineer oder Analytics Engineer musst du Datenpipelines erstellen und pflegen, um deren Qualität und Verfügbarkeit für die Erstellung von Machine-Learning-Modellen oder im Rahmen von Business Intelligence zu gewährleisten.
Um mehr über die Berufe Data Engineer und Analytics Engineer und die von uns angebotenen Ausbildungswege zu erfahren, besuche bitte unsere speziellen Seiten.







