Heute beschäftigen wir uns mit dem Isolation Forest, einem Machine-Learning-Algorithmus zur Lösung von binären Klassifikationsproblemen wie Betrugserkennung oder Krankheitsdiagnose. Diese Technik, die 2008 auf der Eighth IEEE International Conference vorgestellt wurde, ist die erste Klassifizierungstechnik, die sich der Erkennung von Anomalien auf der Grundlage von Isolation widmet.
Isolation Forest - Das Accuracy-Paradox-Problem
Bei einem Klassenklassifikationsproblem mit Machine Learning kann es vorkommen, dass der Datensatz unausgewogen ist. Genauer gesagt, ist der Anteil einer Klasse im Vergleich zu einer anderen in der Lernstichprobe viel größer. Dieses Problem ist ein häufiges Merkmal von binären Klassifikationsproblemen. Man könnte zunächst daran denken, einen klassischen Klassifikationsalgorithmus anzuwenden, wie z. B. Entscheidungsbäume, K-NN oder SVM, die in unserem Blog vorgestellt werden. Diese Algorithmen sind jedoch in Wirklichkeit nicht in der Lage, mit diesen atypischen Datensätzen umzugehen, in denen die Unterschiede zwischen den Klassen ziemlich groß sind. Sie tendieren dazu, über ihre Verlustfunktion Größen wie die Akkuranz zu maximieren, ohne jedoch die Verteilung der Daten zu berücksichtigen.
In der Praxis führt dies zu Modellen, die, wenn sie mit einem von einer Klasse dominierten Datenbestand trainiert werden, in der Evaluierungsphase eine hohe Rate an korrekten Vorhersagen, die sogenannte „accuracy“, aufweisen, aber für den Gebrauch nicht relevant sind.
Ein Beispiel soll dieses Paradoxon verdeutlichen. Betrachten wir ein Problem bei der Erkennung von Bankbetrug: Eine Bank versucht, aus einer großen Anzahl von Transaktionen anhand einer Reihe von erklärenden Variablen die betrügerischen Transaktionen zu bestimmen. Diese betrügerischen Transaktionen machen etwa 11% der Transaktionen in unserem Datenbestand aus. Die Klassifizierung mithilfe eines einfachen Modells wie SVM mithilfe von scikit learn ergibt z. B. folgende Punktzahl:
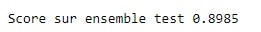
Ein Blick auf die Verwirrungsmatrix zeigt jedoch schnell, dass der Algorithmus sich recht naiv verhält:

Tatsächlich wurden von 219 betrügerischen Transaktionen nur 25 von unserem Modell tatsächlich als betrügerisch identifiziert. Wir stellen also fest, dass die Vorhersagekraft des Modells nicht so stark ist, wie es die accuracy vermuten lassen könnte. Es handelt sich um eine Metrik, die durch ein Ungleichgewicht der Klassen zu stark verzerrt ist, dieses Phänomen wird als accuracy paradox bezeichnet.
Ein Modell mit einem höheren accuracy-Wert kann eine geringere Vorhersagekraft haben als ein Modell mit einem niedrigeren accuracy-Wert.
Isolation Forest: Was ist das?
Aber wie geht man mit diesem Problem um, das die Bemühungen mehrerer gut trainierter klassischer Algorithmen zunichte macht? Es gibt verschiedene Lösungen, wie z. B. Resampling-Methoden wie Undersampling oder Oversampling, bei denen Daten zufällig ausgewählt werden, um das Klassenverhältnis auszugleichen. Wenn diese Methoden jedoch nicht effektiv genug sind, ist es üblich, das Problem neu zu überdenken und die Erkennung von Anomalien als ein Problem der unüberwachten Klassifizierung zu betrachten. Hier kommt der lang erwartete Isolation Forest ins Spiel!
Isolation Forest ist eine Technik zur Erkennung von Anomalien, die Anomalien (allgemein als „Ausreißer“ bekannt) direkt identifiziert, im Gegensatz zu herkömmlichen Techniken, die Punkte von einem „normalisierten“ Gesamtprofil unterscheiden.
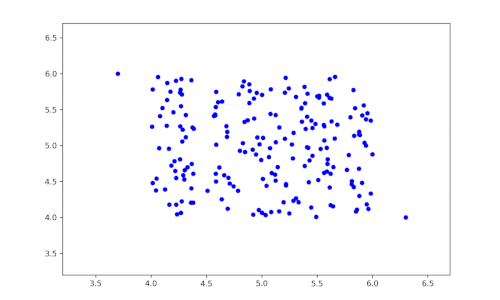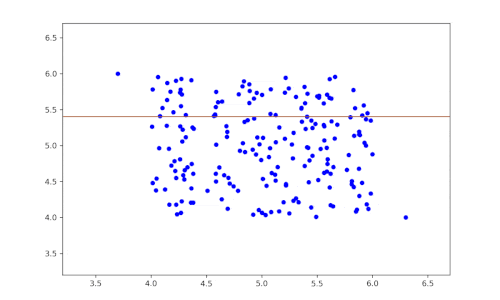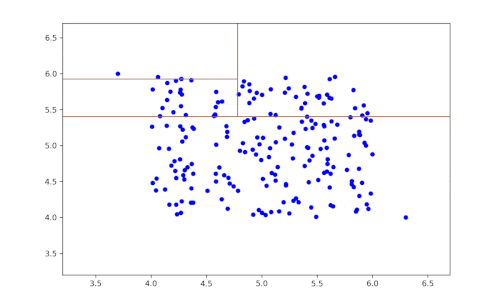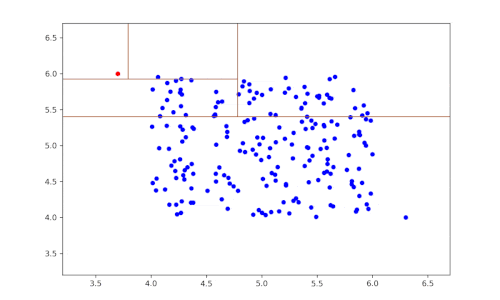
Das Prinzip dieses Algorithmus ist sehr einfach:
- Man wählt eine Variable (Feature) zufällig aus.
- Anschließend wird der Datensatz nach dieser Variable zufällig partitioniert, um zwei Teilmengen der Daten zu erhalten.
- Die beiden vorherigen Schritte werden so lange wiederholt, bis ein Datensatz isoliert ist.
- Rekursiv werden die vorherigen Schritte wiederholt.