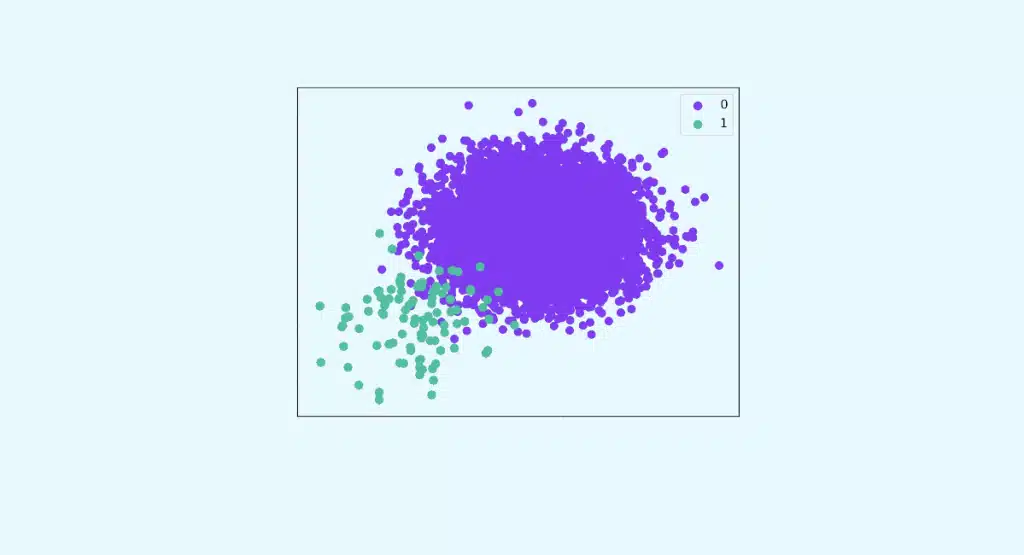
Wie geht man mit einer unausgewogenen Klassifizierung um? Teil I
Die Klassifizierung auf unausgewogenen Daten ist ein Klassifizierungsproblem, bei dem die Lernstichprobe eine starke Disparität zwischen den vorherzusagenden Klassen enthält. Dieses Problem taucht häufig bei binären Klassifikationsproblemen auf, insbesondere bei der Erkennung von Anomalien.
Dieser Artikel ist in zwei Teile gegliedert: Der erste beschäftigt sich mit der Auswahl von Metriken, die für diesen Datentyp typisch sind, der zweite beschreibt detailliert die Bandbreite an Methoden, die nützlich sind, um ein leistungsfähiges Modell zu erhalten.
Teil I: Die Wahl der richtigen Metriken
Was ist eine Bewertungsmetrik?
Eine Bewertungsmetrik quantifiziert die Leistung eines Vorhersagemodells.
Die Wahl der richtigen Metrik ist daher bei der Bewertung von Machine-Learning-Modellen entscheidend, und die Qualität eines Klassifikationsmodells hängt direkt von der Metrik ab, die zu seiner Bewertung verwendet wird.
Bei Klassifikationsproblemen bestehen die Metriken im Allgemeinen darin, die tatsächlichen Klassen mit den vom Modell vorhergesagten Klassen zu vergleichen. Sie können auch dazu dienen, die vorhergesagten Wahrscheinlichkeiten für diese Klassen zu interpretieren.
Eines der wichtigsten Leistungskonzepte für die Klassifizierung ist die Verwechslungsmatrix, die eine tabellarische Darstellung der Modellvorhersagen im Vergleich zu den tatsächlichen Labels ist. Jede Zeile der Verwechslungsmatrix repräsentiert die Instanzen einer tatsächlichen Klasse und jede Spalte repräsentiert die Instanzen einer vorhergesagten Klasse.
Nehmen wir als Beispiel eine binäre Klassifizierung, bei der es 100 positive und 70 negative Instanzen gibt.
Die folgende Verwechslungsmatrix entspricht den Ergebnissen, die unser Modell liefert:
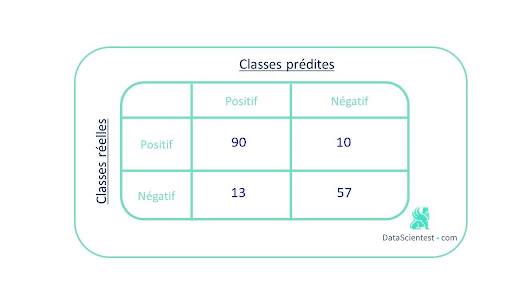
Sie gibt einen Überblick über die richtigen und falschen Vorhersagen.
Um diese Matrix in einer Metrik zusammenzufassen, kann man die Rate der richtigen Vorhersagen oder accuracy verwenden. Hier ist sie gleich (90+57)/170 = 0,86.
Die Wahl einer geeigneten Metrik ist nicht bei jedem Machine-Learning-Modell offensichtlich, aber bei Problemen mit unausgewogenen Klassifizierungen ist sie besonders schwierig.
Bei Daten mit einer stark überwiegenden Klasse sind herkömmliche Algorithmen oft verzerrt, da ihre Verlustfunktionen versuchen, Metriken wie die Rate der guten Vorhersagen zu optimieren, und dabei die Verteilung der Daten außer Acht lassen.
Im schlimmsten Fall werden die Minderheitsklassen als Ausreißer der Mehrheitsklasse behandelt und der Lernalgorithmus erzeugt einfach einen trivialen Klassifikator, der jedes Beispiel in die Mehrheitsklasse einordnet. Das Modell scheint dann zwar leistungsfähig zu sein, aber das spiegelt nur die Überrepräsentation der Mehrheitsklasse wider. Dies wird als paradoxes Akkuracy bezeichnet.
In den meisten Fällen ist es gerade die Minderheitsklasse, die von größtem Interesse ist und die man gerne identifizieren würde, wie im Beispiel der Betrugserkennung.
Der Grad der Unausgewogenheit variiert, aber die Anwendungsfälle sind häufig: Krankheitssuche, Fehlererkennung, Suchmaschinen, Spam-Filter, gezieltes Marketing etc.
Praxisbeispiel : Churn Rate
Angenommen, ein Dienstleistungsunternehmen möchte seine Abwanderungsrate (Churn Rate) vorhersagen.
Zur Erinnerung: Die Abwanderungsrate ist das Verhältnis zwischen der Anzahl der verlorenen Kunden und der Gesamtanzahl der Kunden, gemessen über einen bestimmten Zeitraum, meist ein Jahr.
Um dies zu erreichen, möchte die Firma für jeden Kunden vorhersagen, ob er seinen Vertrag am Ende des Jahres kündigen wird.
Wir haben einen Datensatz, der persönliche Informationen und vertragsbezogene Merkmale für jeden Kunden des Unternehmens für das Jahr X enthält, sowie eine Variable, mit der wir feststellen können, ob er seinen Vertrag am Ende des Jahres verlängert hat.
In unseren Daten entspricht die Anzahl der ‚Churner‘ etwa 11 % der Gesamtzahl der Kunden.
Wir beschließen, ein erstes Modell der logistischen Regression auf unsere vorbereiteten und normalisierten Daten zu trainieren.
Überraschung! Unser Code hat eine Quote guter Prognosen von 0,90!
Das ist ein sehr guter Wert, aber erinnern wir uns an unser Ziel: Erfolgreiche Vorhersage von Kundenabgängen. Bedeutet dieses Ergebnis, dass das Modell von 10 „Churnern“ 9 als solche erkennt? Absolut nicht!
Die einzige Interpretation, die man machen kann, ist, dass 9 von 10 Kunden vom Modell richtig eingestuft wurden.
Um naive Verhaltensweisen eines Modells zu erkennen, ist das effektivste Werkzeug immer noch die Verwechslungsmatrix.
Ein erster Blick auf die Verwechslungsmatrix zeigt uns, dass die gute Rate an guten Vorhersagen, die wir erhalten, stark davon beeinflusst wird, wie gut sich das Modell in der dominanten Klasse (0) verhält.
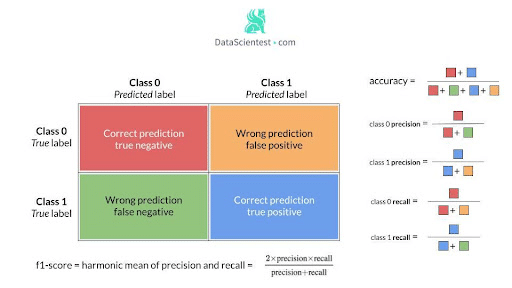
Um das Modell in Bezug auf das gewünschte Verhalten in einer Klasse zu bewerten, können wir eine Reihe von Metriken aus der Verwirrungsmatrix verwenden, wie z. B. Genauigkeit, Recall und f1-Score, die weiter unten definiert werden.

So für eine bestimmte Klasse:
Eine hohe Genauigkeit und ein hoher Recall -> Die Klasse wurde vom Modell gut erfasst.
Hohe Genauigkeit und niedriger Recall -> Die Klasse wird nicht gut erkannt, aber wenn sie erkannt wird, ist das Modell sehr zuverlässig.
Geringe Genauigkeit und hoher Recall -> Die Klasse wird gut erfasst, enthält aber auch Beobachtungen anderer Klassen.
Eine niedrige Genauigkeit und ein niedriger Recall -> Die Klasse wurde überhaupt nicht gut erfasst.
Mit dem F1-Score können sowohl die Genauigkeit als auch der Recall gemessen werden.
Im Falle einer binären Klassifizierung entsprechen Sensitivität und Spezifität dem Recall der positiven bzw. negativen Klasse.
Eine weitere Metrik, der geometrische Mittelwert (G-mean), ist nützlich für unausgewogene Klassifikationen: Er ist die Wurzel aus dem Produkt von Sensitivität und Spezifität.
Diese verschiedenen Metriken sind über das Paket imblearn leicht zugänglich.
Die Funktion classification_report_imbalanced() zeigt einen Bericht an, der die Ergebnisse für alle Metriken des Pakets enthält.
Wir erhalten die folgende Tabelle:
Die Tabelle zeigt, dass der Recall und der f1-Score der Klasse 1 schlecht sind, während sie für die Klasse 0 hoch sind. Darüber hinaus ist auch das geometrische Mittel niedrig.
Das trainierte Modell ist daher für unsere Daten nicht geeignet.
In Teil II werden wir die Methoden kennen lernen, mit denen wir viel bessere Ergebnisse erzielen können.
Möchtest Du Deine Fähigkeiten verbessern, um erfolgreiche und zuverlässige Modelle aus unausgewogenen Datensätzen zu erstellen? Schau dir alle unsere Lernmodule an!
Kontaktiere uns für weitere Informationen!
Auch interessant:







