Unit-Test: Definition
Der Unit-Test bezeichnet in der Computerprogrammierung das Verfahren, mit dem sichergestellt wird, dass eine Software oder ein Quellcode (bzw. ein Teil einer Software oder ein Teil eines Codes) einwandfrei funktioniert.
Nachdem der Unit-Test lange Zeit als zweitrangige Aufgabe angesehen wurde, ist er heute eine gängige und sogar wesentliche Praxis und ein fester Bestandteil des standardmäßigen Entwicklungslebenszyklus.
Der Unit-Test ist ein wesentlicher Bestandteil jedes Quellcodes, um sicherzustellen, dass die Anwendung trotz möglicher Weiterentwicklungen des Quellcodes so funktioniert, wie es in der Spezifikation vorgesehen ist. Außerdem stützen sich gute Softwareentwicklungspraktiken wie Test Driven Development (TDD) und DevOps stark auf Unit-Tests.
Die Rolle und die Kriterien des Unit-Tests
Unit-Tests werden entwickelt, um die endgültige Version mit der Spezifikation zu vergleichen, die normalerweise in den frühen Phasen eines IT-Projekts geliefert wird.
Sie ermöglichen es, eine Entscheidung über den Erfolg oder Misserfolg einer Überprüfung zu treffen. Ein Test kann also als ein Kriterium verstanden werden, das die Erwartungen an ein Programm oder einen Computercode bestätigt.
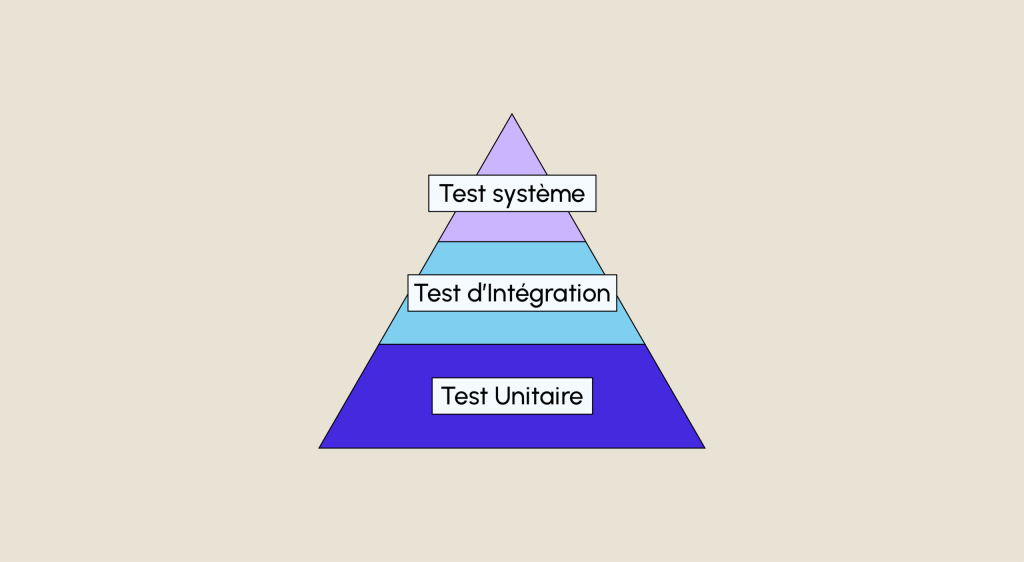
Mike Cohn, einer der Hauptverfechter der agilen Scrum-Methode, stellt Unit-Tests an die Basis seiner Testpyramide (in der die nächsten Ebenen den Service- und Schnittstellentests entsprechen).
Der Unit-Test ermöglicht unter anderem Folgendes:
- Fehler schnell zu identifizieren: Mehrere Methoden (z. B. eXtreme Programming) empfehlen, die Tests gleichzeitig oder sogar vor der zu testenden Funktion zu schreiben, um das Debugging zu erleichtern.
- Die Wartung zu erleichtern: Nach der Änderung eines Codes können die Tests schnell mögliche Rückschritte (fehlgeschlagene Tests) identifizieren.
- Die Dokumentation des Codes zu vervollständigen: Tests ermöglichen es oft, die Verwendung einer Funktion besser hervorzuheben. So können sie die Dokumentation der Funktionen ergänzen.
Um einen Unit-Test richtig zu definieren, müssen mehrere Kriterien erfüllt sein:
- Einheit: Der Unit-Test konzentriert sich auf das kleinste identifizierbare Element einer Anwendung (man spricht von einer Einheit). Allerdings können mehrere Elemente oder Codezeilen verwendet werden, um eine Einheit zu definieren, die dann eine Funktion, eine Klassenmethode, ein Modul, ein Objekt usw. sein kann.
- Aus diesem Grund werden Unit-Tests als Low-Level-Tests bezeichnet (im Gegensatz zu High-Level-Tests, die die Gültigkeit einer oder mehrerer komplexerer Funktionen überprüfen).
- White-Box-Test: Der Test muss als White-Box-Test durchgeführt werden, um zu verdeutlichen, dass der Qualitätsingenieur, der häufig für den Test verantwortlich ist, oder der Entwickler selbst Kenntnis von dem Teil des Codes (der Einheit) haben muss, der getestet werden soll.
- Isolation: Die Tests müssen isoliert durchgeführt werden, da jede getestete Einheit unabhängig von den anderen Tests durchgeführt werden muss. Die Folge von Unit-Tests muss in beliebiger Reihenfolge gestartet werden können, ohne das Ergebnis des nächsten oder vorherigen Tests zu beeinflussen.
- Schnelligkeit: Die einzelnen Tests müssen schnell ausgeführt werden können, damit sie bei jeder Änderung des Quellcodes gestartet werden können.
- Idempotenz: Idempotenz bedeutet, dass eine Operation bei jeder Anwendung die gleiche Wirkung hat. Der Test muss also unabhängig von der Umgebung oder der Anzahl der Durchführungen sein.
- Automatisierung: Der Unit-Test sollte direkt ein Ergebnis in Form von Erfolg oder Misserfolg ausgeben können und keinen manuellen Eingriff des Entwicklers zum Abschluss erfordern.
Zusammenfassend kann man also sagen, dass der wahre Wert des Testens bei wichtigen Änderungen am Quellcode einer Anwendung oder eines Systems zum Tragen kommt. Tests stellen dann sicher, dass das erwartete Verhalten beibehalten wird. Der Unit-Test trägt also dazu bei, den Grad der Unsicherheit zu verringern.
Testmethoden und -frameworks sind in der Softwareentwicklung mittlerweile fest verankert, aber wie und wo kommt der Unit-Test in der Datenwissenschaft zum Einsatz?
Tests im Machine Learning
In der traditionellen Softwareentwicklung ist das Schlüsselelement, das das Systemverhalten beeinflusst, der Quellcode.
Machine-Learning-Technologien haben zwei neue Elemente eingeführt, die sich ebenfalls direkt auf das Verhalten des Systems auswirken. Dabei handelt es sich um das verwendete Modell und die Daten. Außerdem wird das Verhalten von Machine-Learning-Modellen nicht spezifisch durch Codezeilen definiert, sondern größtenteils durch die Daten, die in der Trainingsphase verwendet werden.
Dies ist der Grund, warum Systeme, die auf Machine-Learning-Technologien basieren, zusätzliche Tests erfordern, da die Regeln, die das Verhalten des Gesamtsystems steuern, weniger explizit sind als die Regeln traditioneller Systeme.
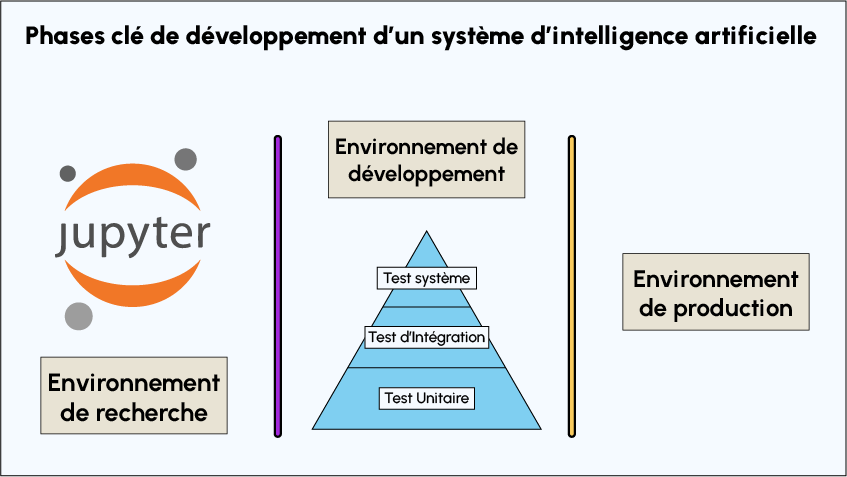
Die Arbeitsschleifen im Bereich Machine Learning werden oft über diese Umgebungen hinweg durchgeführt:
- Die Forschungs- und Entwicklungsumgebung: Hierbei handelt es sich meist um das Jupyter Notebook, das zur Entwicklung der verschiedenen Modelle und Ansätze verwendet wird. Obwohl es technisch möglich ist, Unit-Tests für grundlegende Funktionen (z. B. einer Klasse in Python) zu erstellen und durchzuführen, werden die meisten Unit-Tests in der Regel in den Entwicklungs- und Produktionsumgebungen durchgeführt.
- Die Entwicklungsumgebung : In dieser letzten Umgebung werden die meisten Tests durchgeführt. In dieser Umgebung werden normalerweise mehrere Teststufen unterschieden:
- Unit-Tests, die die Grundlage bilden (wie in der folgenden Grafik dargestellt).
- Integrationstests, um sicherzustellen, dass die verschiedenen Komponenten optimal funktionieren.
- Systemtests, um sicherzustellen, dass das Gesamtsystem funktioniert.
Es stellt sich nun die Frage, wo der Schieberegler zur Definition der Anzahl der Tests positioniert werden soll.
Um die optimale Anzahl an Tests zu definieren, können folgende Fragen herangezogen werden:
- Ist die Testbasis geeignet, um die Unsicherheit über die Funktionsweise unseres Systems zu verringern?
- Was sind die kritischen und wichtigsten Aufgaben unseres Systems?
- Sind die Prioritäten klar festgelegt?
Im Hinblick auf die Problematik des Maschinenlernens werden im Folgenden Beispiele für Unit-Tests gegeben, die man durchführen kann:
- Test des Datenformats und -typs
- Test der Parameter des Machine-Learning-Modells
- Test der Eingabevariablen
- Test auf die Qualität der Modelle.
Die Produktionsumgebung:
Dies ist die Umgebung, in der die Nutzer einer Anwendung auf diese zugreifen werden. Die Tests, die in dieser Umgebung durchgeführt werden, um sicherzustellen, dass das System insgesamt funktioniert, sind in der Regel viel komplexer.
Die Testbibliotheken in Python
Die beiden wichtigsten Python-Bibliotheken für Unit-Tests in der Programmiersprache Python sind Unittest und Pytest.
Die Verwendung der Unittest-Bibliothek für die Durchführung von Tests erfordert gute Kenntnisse der objektorientierten Programmierung von Python, da die Tests über eine Klasse durchgeführt werden.
Im Gegensatz dazu bietet die Verwendung der Pytest-Bibliothek etwas mehr Flexibilität beim Design und der Durchführung von Tests. Abgesehen davon, dass die Durchführung von Tests mit der Pytest-Bibliothek viel flexibler ist, bietet die Pytest-Bibliothek mehr Testbefehle und -optionen (assert instruction).
Um einfache Anwendungsfälle dieser beiden Bibliotheken zu veranschaulichen, betrachten wir die folgenden zwei Beispiele:
- Test einer Funktion, die das Quadrat einer ganzen Zahl berechnet: Wir testen, ob die Ausgabewerte ganze Zahlen sind (Test mit Pytest).
- Test des Typs und der Intervalle der Eingabedaten (mit unittest).
Diese beiden Beispiele sind bei weitem nicht vollständig, aber sie zeigen einige der Möglichkeiten, die diese Bibliotheken bieten.
Testbeispiel mit Pytest
Nehmen wir z. B. an, dass Entwickler im Rahmen eines Projekts eine Funktion erstellt haben, die das Quadrat einer ganzen Zahl berechnet, und dass man Tests durchführen möchte, um sicherzustellen, dass die Ausgaben der Funktion ganze Zahlen sind. Man beschließt also, die Tests mit einer Liste von Werten durchzuführen.
Schritt 1: Definiere die Funktion number_squared in der Datei function.py.
Schritt 2: Festlegen der Testfunktion in der Datei test_in_int.py
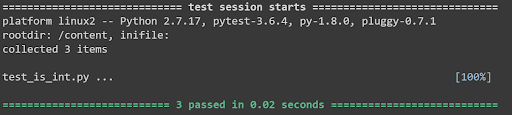
Die Ausführung des Befehls pytest in einem Terminal liefert das folgende Ergebnis:
Die einzige Einschränkung bei der Verwendung der Pytest-Bibliothek ist, dass der Name der Testdatei mit dem Präfix ‚test_‘ beginnen muss (der vollständige Name wäre test_dateiname.py). Auf diese Weise kann bei jeder Änderung oder Aktualisierung der Funktion die Testfunktion verwendet werden, um sicherzustellen, dass das erwartete Verhalten der Funktion konsistent bleibt.
Beispiel für einen Test mit unittest
In diesem Beispiel werden wir die unittest-Bibliothek benutzen, um einen Test mit einem Beispieldatensatz durchzuführen. Wir werden den Datensatz iris verwenden (klicke hier für weitere Details). Der Test, den wir implementieren wollen, besteht darin, die Art und den Umfang der Eingabedaten eines Machine-Learning-Modells zu überprüfen.
Nehmen wir zum Beispiel an, dass der Data Scientist eines Teams ein Modell zur Klassifizierung von drei Blumenarten entwickelt hat. Die Daten (genau genommen die Variablen in unserem Datensatz), die zur Entwicklung des Modells verwendet wurden, hatten jedoch einen bestimmten Typ und erstreckten sich über einen bestimmten Bereich.
Wenn die Informationen, die von den Nutzern unseres Modells geliefert werden, stark von den Trainingsdaten abweichen (Data Drift), könnte das Machine-Learning-Modell nicht mehr relevant sein und inkonsistente Vorhersagen liefern. Aus diesem Grund ist es während der Entwicklungsphase notwendig, einen Test zu definieren, um sicherzustellen, dass die Eingabedaten mit den Trainingsdaten übereinstimmen.
Mit der folgenden Übersicht und Beschreibung des Datensatzes kannst Du sehen, dass die Variablen vom Typ Float (reelle Zahlen) sind, mit Werten in der Regel zwischen 1 und 8.
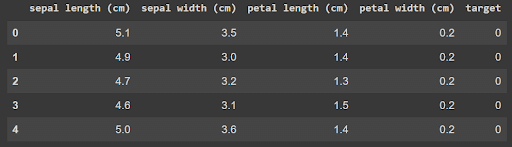
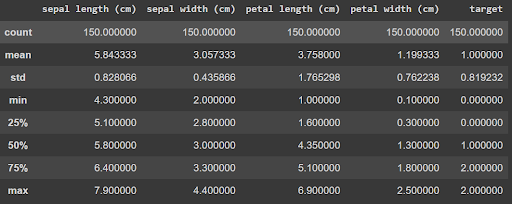
Schritt 1: Definieren eines Wörterbuchs für Variablentypen und -intervalle
In einer Wörterbuchstruktur werden wir für jede Variable sowohl den Typ als auch das Intervall jeder Variable in Übereinstimmung mit der obigen Beschreibung des Datensatzes definieren (Analogie zum Definitionsbereich in der Mathematik).
Schritt 2: Erstellen einer Pipeline zur Datenverarbeitung und zum Trainieren eines logistischen Regressionsmodells
Dieser Schritt kann in mehrere Phasen unterteilt werden, aber wir haben alle Phasen in einer Klasse zusammengefasst.
Schritt 3: Festlegen der Testklasse für unsere Testkampagne
Bei der unittest-Bibliothek ist es notwendig, eine Testklasse zu definieren:
Schritt 4: Ausführen der Tests
Um den Test in einem Jupyter Notebook auszuführen, musst Du nur den folgenden Code verwenden:
Die Ausführung des Codes liefert uns die folgende Anzeige:

Fazit
Die Durchführung von Unit-Tests ist ein unumgänglicher Schritt, um die Unsicherheit zu verringern und eine gewisse Kohärenz zwischen der Eingabespezifikation und dem Endprodukt zu gewährleisten.
Es ist daher verständlich, dass dieser Schritt in agilen Methoden eine wichtige Rolle spielt. Bei der Entwicklung von Machine-Learning-Anwendungen werden die Unit-Tests meist in der Entwicklungsphase von einem Data Scientist oder einem Data Engineer durchgeführt, um die Leistung des Systems zu gewährleisten und sicherzustellen, dass die Ergebnisse mit den Eingabedaten übereinstimmen.
Wenn Du Dich für den Beruf des Data Engineers interessierst, entdecke den von DataScientest konzipierten Werdegang auf der entsprechenden Seite.







